
Build a contextual text and image search engine for product recommendations using Amazon Bedrock and Amazon OpenSearch Serverless
AWS Machine Learning - AI
APRIL 3, 2024
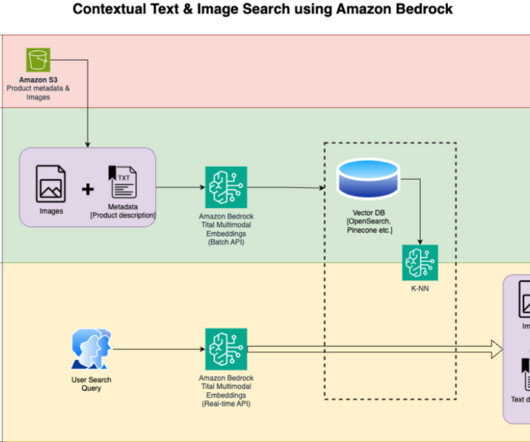
In this post, we show how to build a contextual text and image search engine for product recommendations using the Amazon Titan Multimodal Embeddings model , available in Amazon Bedrock , with Amazon OpenSearch Serverless. Store embeddings into the Amazon OpenSearch Serverless as the search engine. Review and prepare the dataset.


























Let's personalize your content