

Reduce ML training costs with Amazon SageMaker HyperPod
AWS Machine Learning - AI
APRIL 10, 2025
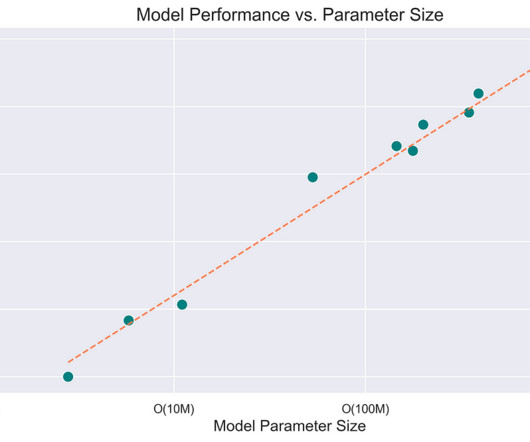
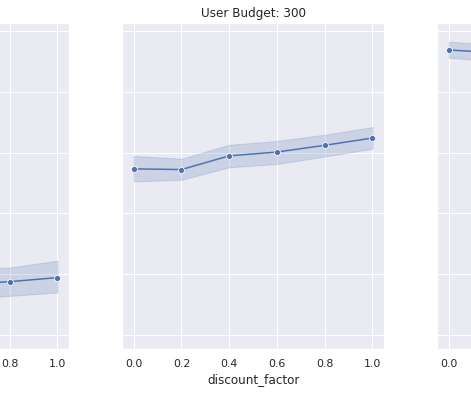
Training a frontier model is highly compute-intensive, requiring a distributed system of hundreds, or thousands, of accelerated instances running for several weeks or months to complete a single job. As cluster sizes grow, the likelihood of failure increases due to the number of hardware components involved. million H100 GPU hours.





































Let's personalize your content