This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Software-as-a-service (SaaS) applications with tenant tiering SaaS applications are often architected to provide different pricing and experiences to a spectrum of customer profiles, referred to as tiers. The user prompt is then routed to the LLM associated with the task category of the reference prompt that has the closest match.
This includes the creation of landing zones, defining the VPN, gateway connections, network policies, storage policies, hosting key services within a private subnet and setting up the right IAM policies (resource policies, setting up the organization, deletion policies).
This led to the rise of software infrastructure companies providing technologies such as database systems, networking infrastructure, security solutions and enterprise-grade storage. The resource management tools we call AI enablers make it easier to use databases, streaming, storage and caching.
In this context, they refer to a count very close to accurate, presented with minimal delays. After selecting a mode, users can interact with APIs without needing to worry about the underlying storage mechanisms and counting methods. For more information regarding this, refer to our previous blog.
Solution overview This section outlines the architecture designed for an email support system using generative AI. High Level SystemDesign The solution consists of the following components: Email service – This component manages incoming and outgoing customer emails, serving as the primary interface for email communications.
Ground truth data in AI refers to data that is known to be factual, representing the expected use case outcome for the system being modeled. By providing an expected outcome to measure against, ground truth data unlocks the ability to deterministically evaluate system quality. . Amazons operating margin in 2023 was 6.4%.
Key features of AWS Batch Efficient Resource Management: AWS Batch automatically provisions the required resources, such as compute instances and storage, based on job requirements. This enables you to build end-to-end workflows that leverage the full range of AWS capabilities for data processing, storage, and analytics.
Once upon an IT time, everything was a “point product,” a specific application designed to do a single job inside a desktop PC, server, storage array, network, or mobile device. A few years ago, there were several choices of data deduplication apps for storage, and now, it’s a standard function in every system.
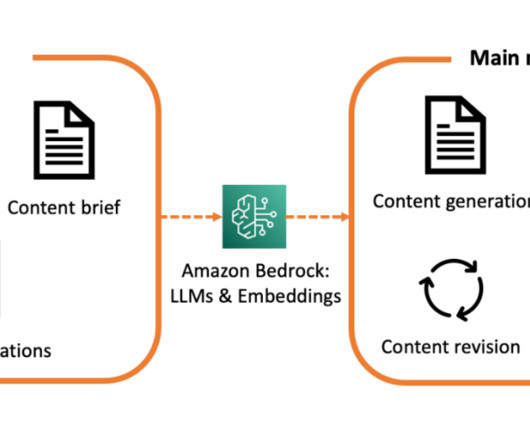
Amazon Simple Storage Service (S3) : for documents and processed data caching. Image 2: Content generation steps The workflow is as follows: In step 1, the user selects a set of medical references and provides rules and additional guidelines on the marketing content in the brief. Amazon Translate : for content translation.
So this post aims to set the record straight and assure a canonical history that everyone can reference and use. Examples include mainframes, solitary servers, HA loadbalancers/firewalls (active/active or active/passive), database systemsdesigned as master/slave (active/passive), and so on. The History.
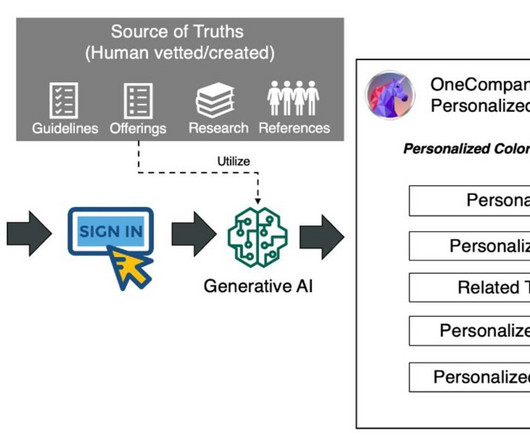
We employed other LLMs available on Amazon Bedrock to synthetically generate fictitious reference materials to avoid potential biases that could arise from Amazon Claude’s pre-training data. We now need to gather human-curated sources of truth such as testimonials, design guidelines, requirements, and offerings. offerings = open("./references/offerings.txt",
The RAG workflow enables you to use your document data stored in an Amazon Simple Storage Service (Amazon S3) bucket and integrate it with the powerful natural language processing (NLP) capabilities of foundation models (FMs) provided by Amazon Bedrock. For installation instructions, refer to the AWS CDK workshop.
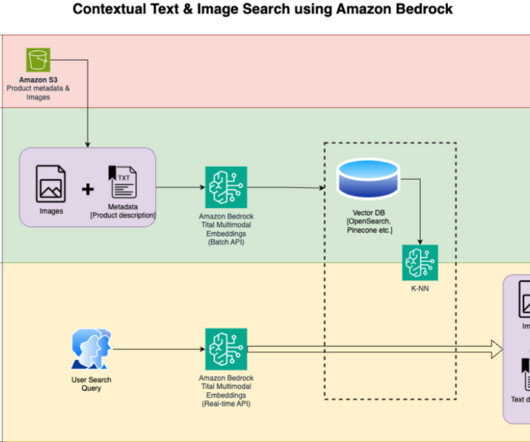
The following are the solution workflow steps: Download the product description text and images from the public Amazon Simple Storage Service (Amazon S3) bucket. If you don’t have a SageMaker Studio domain already configured, refer to Amazon SageMaker simplifies the Amazon SageMaker Studio setup for individual users for steps to create one.
The agent can recommend software and architecture design best practices using the AWS Well-Architected Framework for the overall systemdesign. Recommend AWS best practices for systemdesign with the AWS Well-Architected Framework guidelines. For more details, refer to Amazon Bedrock pricing.
To leverage this feature you can run the import process (covered later in the blog) with your model weights being in Amazon Simple Storage Service (Amazon S3). This training job reads the dataset from Amazon Simple Storage Service (Amazon S3) and writes the model back into Amazon S3. On the options menu (three dots), choose Delete.
For a more in-depth description of these phases please refer to Impala: A Modern, Open-Source SQL Engine for Hadoop. Query Planner Design. However before those rows get to the join operation they have to be read from storage and materialized in memory, just to be later discarded by the join.
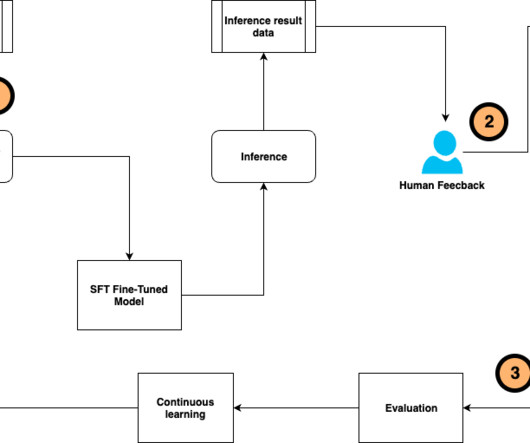
The complete flow is shown in the following figure and it covers the following steps: The user invokes a SageMaker training job to fine-tune the model using QLoRA and store the weights in an Amazon Simple Storage Service (Amazon S3) bucket in the user’s account. This step will run Steps 3–5 automatically.
You can integrate existing data from AWS data lakes, Amazon Simple Storage Service (Amazon S3) buckets, or Amazon Relational Database Service (Amazon RDS) instances with services such as Amazon Bedrock and Amazon Q. For example, “Cross-reference generated figures with golden source business data.” Don’t make up any statistics.”
Next, you will provide the Amazon Simple Storage Service (Amazon S3) path where you want to store the input documents to run your Lambda function on and to store the output of the documents. He specializes in Generative AI, Artificial Intelligence, Machine Learning, and SystemDesign.
Any COVID-19 safety measures still in place. Looking forward to your response. “”” print(main(message=message)) This module is part of an automated email processing systemdesigned to analyze customer messages, detect their intent, and generate structured responses based on the analysis.
Today I will be covering the advances that we have made in the area of hybrid-core architecture and its application to Network Attached Storage. This is referred to as the Von Neumann bottleneck. File System Board (MFB) The File System Board (MFB) is the core of the hardware accelerated file system.
In order to perform this critical function of data storage and protection, database administration has grown to include many tasks: Security of data in flight and at rest. Interpretation of data through defined storage. Acquisition of data from foreign systems. Security of data at an application access level. P stands for post.
Apache Hadoop Distributed File System (HDFS) is the most popular file system in the big data world. The Apache Hadoop File System interface has provided integration to many other popular storagesystems like Apache Ozone, S3, Azure Data Lake Storage etc. References: Apache Hadoop ViewFS Guide: [link].
Data refers to raw facts and figures. Application, or the reason for data collection, Collection, or the process of data gathering, Warehousing, or systems and activities related to data storage and archiving, and. But to make things ultimately clear, we need to answer the question: What exactly is health information?
At the same time, you should avoid bloating your fleet to minimize storage/demurrage charges and other expenses. When connected to cloud-based storage and processing solutions, they create the Internet of Things (IoT) infrastructure. Tracking traditionally refers to knowing the exact location of an asset, shipment, or whatever.
This is isolation in action and is sometimes referred to as “degradation of service” since the failure does not render the entire set of functionality useless. This includes assigning greater or fewer compute and storage infrastructure resources and customized configuration of said resources. Of course, there will be!
Each first stage booster has nine Merlin engines, a fuel storage/dispensing system, and four landing legs. Their job is to make sure the landing legs work properly and do their job as part of the overall system. From experience-based, leader-driven decision-making to data-driven decision-making at the front line.
NoSQL is really more a movement than a technology —one that’s devoted to expanding the number of storage options for systemdesigners. NoSQL was never a single technology; databases like Cassandra, HBase, Redis, MongoDB, and many others are wildly different. Of the more established NoSQL databases, MongoDB shows 10% growth.
There are three parts in the book: Foundations of Data Systems (chapters 1 – 4), Distributed Data (chapters 5 – 9), and Derived Data (chapters 10 – 12). Each chapter ends with lots of references (between 30 and 110). Foundations of Data Systems. Storage and Retrieval. Encoding and Evolution.
Besides the efficiency in systemdesign, the compound AI system also enables you to optimize complex generative AI systems, using a comprehensive evaluation module based on multiple metrics, benchmarking data, and even judgements from other LLMs. For more details, refer to Amazon Bedrock pricing.
Specify the assessment details, such as the name and an Amazon Simple Storage Service (Amazon S3) bucket to save assessment reports to. Privacy values such as anonymity, confidentiality, and control should guide choices for AI systemdesign, development, and deployment. Choose Create assessment.
These two 1991 books are foundational references on what came to be called “lean product development,” although the term “lean” would not be associated with product development for another decade. Charter a team of responsible experts led by an entrepreneurial systemdesigner. Kanban , Blue Hole Press, 2010 Beck, Kent.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content