This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The system then orchestrates the creation of necessary model endpoints, processes documents in batches for efficiency, and automatically cleans up resources upon completion. Multiple specialized Amazon Simple Storage Service Buckets (Amazon S3 Bucket) store different types of outputs.
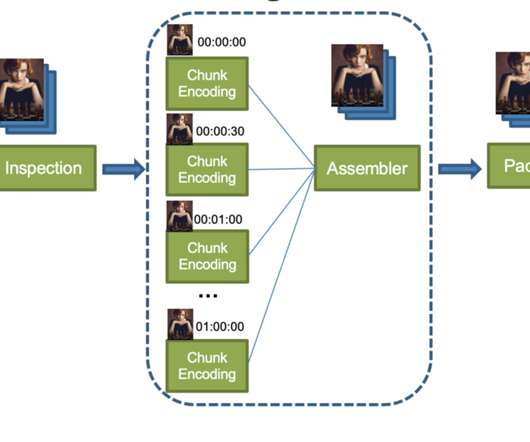
From chunk encoding to assembly and packaging, the result of each previous processing step must be uploaded to cloud storage and then downloaded by the next processing step. Since not all projects are terabytes projects, allocating the largest cloud storage to all packager instances is not an efficient use of cloud resources.
Understanding the intrinsic value of data network effects, Vidmob constructed a product and operational systemarchitecture designed to be the industry’s most comprehensive RLHF solution for marketing creatives. On the backend, a router is used to determine the context (ad-related dataset) as a reference to answer the question.
FHIR components: resources, references, profiles. The main idea about FHIR is to provide a core set of data elements called resources , which, when combined through references , should cover most clinical use cases. These three components (resources, references, profiles) are the main aspects of FHIR development. FHIR resources.
Incorporate flexibility to scale with Modern EDI systemarchitecture. Encrypted transfer protocols and proper data storage are critical for end-to-end processes. APIs help connect directly to applications and transactional systems like ERP for instant data transfer. References. Here are our top 3 recommendations.
Additional data is available over REST as well as static reference data published on web pages. As with any system out there, the data often needs processing before it can be used. There’s also some static reference data that is published on web pages. ?After Wrangling the data. Resolving codes in events to their full values.
By adding this event id, we can now reference the corner-specific sheet for additional data on each row. No surprise, we will again start with the Wikipedia definition: “A NoSQL database provides a mechanism for storage and retrieval of data that is modeled in means other than the tabular relations used in relational databases.”.
Check out the Day 2 Operations Guide as you plan your upgrades to Cloudera’s Data Services on private cloud and bookmark it for future reference as you operate your state-of-the-art data platform. Planning the architecture: design the systemarchitecture, considering factors like scalability, security, and performance.
In this post we will provide details of the NMDB systemarchitecture beginning with the system requirements?—?these these will serve as the necessary motivation for the architectural choices we made. Conductor helps us achieve a high degree of service availability and data consistency across different storage backends.
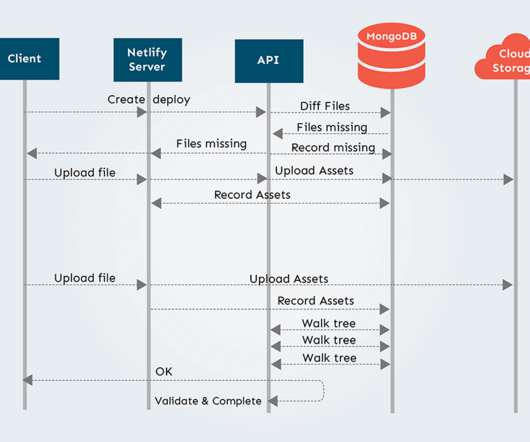
If we kept all the references in a single document we run into the storage limitations of MongoDB. But, of course, there’s more nuance in actually making this change: from coordination between different services, languages, deploy types, and deploy styles to how to roll it out on an already running system.
The data fabric refers to various activities such as data extraction, data discovery, data transformation, data definition, data modelling, and data management for both structured as well as unstructured data. Data storage requirements in terms of data warehouse or data lakes or operational data store. Data Management.
In order to perform this critical function of data storage and protection, database administration has grown to include many tasks: Security of data in flight and at rest. Interpretation of data through defined storage. Acquisition of data from foreign systems. Security of data at an application access level. P stands for post.
It involves a lot of automation and is usually accompanied by a change in systemarchitecture, organizational structure, and incentives (more on that later). That’s when newly minted internet companies tried to grow systems many times larger than any enterprise could manage.
From there these events can be used to drive applications, be streamed to other data stores such as search replicas or caches and streamed to storage for analytics. Since the error message references t.id , which we specify as the incrementing.column.name , maybe it’s got something to do with this.
Refer to the GitHub repo for instructions on setting up an EKS cluster. Custom resources Running multi-node distributed training requires various resources, such as device plugins, Container Storage Interface (CSI) drivers, and training operators, to be pre-deployed on the EKS cluster. If you save checkpoints with ray.train.report(.,
Agmatix’s technology architecture is built on AWS. Their data pipeline (as shown in the following architecture diagram) consists of ingestion, storage, ETL (extract, transform, and load), and a data governance layer. Multi-source data is initially received and stored in an Amazon Simple Storage Service (Amazon S3) data lake.
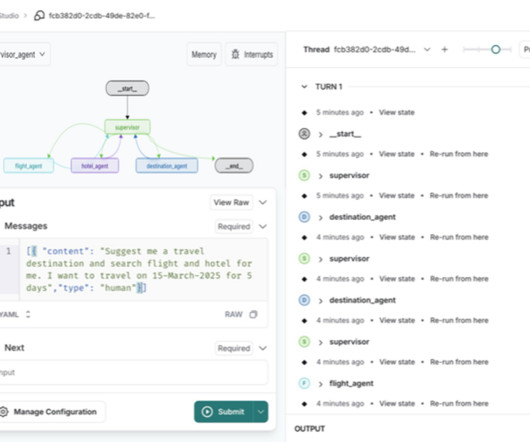
Memory management in AI systems differs between single-agent and multi-agent architectures. Single-agent systems use a three-tier structure: short-term conversational memory, long-term historical storage, and external data sources like Retrieval Augmented Generation (RAG).
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content