This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Software-as-a-service (SaaS) applications with tenant tiering SaaS applications are often architected to provide different pricing and experiences to a spectrum of customer profiles, referred to as tiers. The user prompt is then routed to the LLM associated with the task category of the reference prompt that has the closest match.
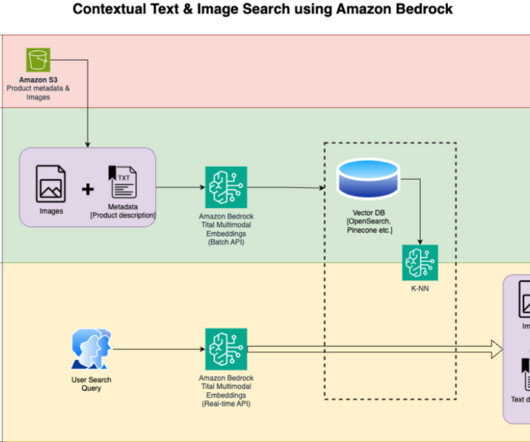
In this post, we show how to build a contextual text and image search engine for product recommendations using the Amazon Titan Multimodal Embeddings model , available in Amazon Bedrock , with Amazon OpenSearch Serverless. Store embeddings into the Amazon OpenSearch Serverless as the search engine.
Amazon Bedrock offers a serverless experience so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage infrastructure. Refer to the GitHub repository for deployment instructions.
Ground truth data in AI refers to data that is known to be factual, representing the expected use case outcome for the system being modeled. By providing an expected outcome to measure against, ground truth data unlocks the ability to deterministically evaluate system quality. . 201% $12.2B
By using the AWS CDK, the solution sets up the necessary resources, including an AWS Identity and Access Management (IAM) role, Amazon OpenSearch Serverless collection and index, and knowledge base with its associated data source. For installation instructions, refer to the AWS CDK workshop. The AWS CDK already set up.
Each job references a job definition. It’s built on serverless services (API Gateway / Lambda) and provides the same functionality as the CLI tool pcluster. This is a serverless web UI that mirrors the pcluster functionality. Jobs can be artefacts such as Docker container images, shell scripts or regular Linux executables.
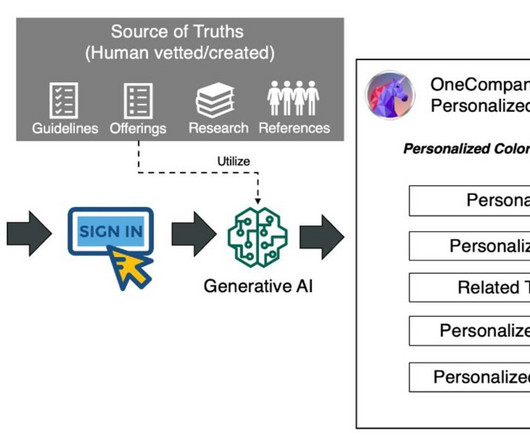
We employed other LLMs available on Amazon Bedrock to synthetically generate fictitious reference materials to avoid potential biases that could arise from Amazon Claude’s pre-training data. We now need to gather human-curated sources of truth such as testimonials, design guidelines, requirements, and offerings. offerings = open("./references/offerings.txt",
The agent can recommend software and architecture design best practices using the AWS Well-Architected Framework for the overall systemdesign. Recommend AWS best practices for systemdesign with the AWS Well-Architected Framework guidelines. For more details, refer to Amazon Bedrock pricing.
To set up SageMaker Studio, refer to Launch Amazon SageMaker Studio. Refer to the SageMaker JupyterLab documentation to set up and launch a JupyterLab notebook. For more details, refer to Evaluate Bedrock Imported Models. He specializes in generative AI, artificial intelligence, machine learning, and systemdesign.
Refer to the licensing information regarding this dataset before proceeding further. He has more than 18 years working with technology, from software development, infrastructure, serverless, to machine learning. He specializes in Generative AI, Artificial Intelligence, Machine Learning, and SystemDesign.
“Build one to throw away” shouldn’t refer to your flagship product. Allow yourself time to vet and review references. In many cases, this layer could exist in the cloud as redirects or services like serverless compute. Use a DesignSystem. Good leadership will create a sense of ownership.
Finally, last year we observed that serverless appeared to be keeping pace with microservices. While microservices shows healthy growth, serverless is one of the few topics in this group to see a decline—and a large one at that (41%). Solid year-over-year growth and heavy usage is exactly what we’d expect to see. That’s no longer true.
Journey to Event Driven – Part 3: The Affinity Between Events, Streams and Serverless. Processing failure can be due to any number of reasons, from deserialization failure to invalid values or invalid references (join failure, etc). To see how all stream processing microservices run within a monolith, refer to KPayAllInOneImpl.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content