This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As developers look for ways to simplify how they create software, serverless solutions, which enable them to write code without worrying about the underlying infrastructure required to run their applications, is becoming increasingly popular. Spruill said that this wasn’t the company’s first foray into serverless.
Azure Key Vault Secrets offers a centralized and secure storage alternative for API keys, passwords, certificates, and other sensitive statistics. Azure Key Vault is a cloud service that provides secure storage and access to confidential information such as passwords, API keys, and connection strings. What is Azure Key Vault Secret?
Amazon Bedrock Custom Model Import enables the import and use of your customized models alongside existing FMs through a single serverless, unified API. This serverless approach eliminates the need for infrastructure management while providing enterprise-grade security and scalability. An S3 bucket prepared to store the custom model.
Introduction With an ever-expanding digital universe, data storage has become a crucial aspect of every organization’s IT strategy. S3 Storage Undoubtedly, anyone who uses AWS will inevitably encounter S3, one of the platform’s most popular storage services. Storage Class Designed For Retrieval Change Min.
This article delves into the concept of User Data Governance and its implementation using serverless streaming. We will explore the benefits of using serverless streaming for processing user data and how it can lead to improved data governance and increased privacy protection.
DeltaStream provides a serverless streaming database to manage, secure and process data streams. “Serverless” refers to the way DeltaStream abstracts away infrastructure, allowing developers to interact with databases without having to think about servers. .”
That’s where the new Amazon EMR Serverless application integration in Amazon SageMaker Studio can help. In this post, we demonstrate how to leverage the new EMR Serverless integration with SageMaker Studio to streamline your data processing and machine learning workflows.
If you don’t have an AWS account, refer to How do I create and activate a new Amazon Web Services account? If you don’t have an existing knowledge base, refer to Create an Amazon Bedrock knowledge base. Performance optimization The serverless architecture used in this post provides a scalable solution out of the box.
The workflow consists of the following steps: WAFR guidance documents are uploaded to a bucket in Amazon Simple Storage Service (Amazon S3). Using Amazon Bedrock Knowledge Base, the sample solution ingests these documents and generates embeddings, which are then stored and indexed in Amazon OpenSearch Serverless.
Shared components refer to the functionality and features shared by all tenants. API Gateway is serverless and hence automatically scales with traffic. The advantage of using Application Load Balancer is that it can seamlessly route the request to virtually any managed, serverless or self-hosted component and can also scale well.
This solution can serve as a valuable reference for other organizations looking to scale their cloud governance and enable their CCoE teams to drive greater impact. Oleg Chugaev is a Principal Solutions Architect and Serverless evangelist with 20+ years in IT, holding multiple AWS certifications. About the Authors Steven Craig is a Sr.
We also use Vector Engine for Amazon OpenSearch Serverless (currently in preview) as the vector data store to store embeddings. Asynchronous updates – To ensure the reference documents remain current, they can be updated asynchronously along with their embedding representations. An OpenSearch Serverless collection.
Since Amazon Bedrock is serverless, you don’t have to manage any infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with. We're more than happy to provide further references upon request. We must also include.$
With Serverless, it’s not the technology that’s hard, it’s understanding the language of a new culture and operational model. Serverless architecture has coined some new terms and, more confusingly, re-used a few older terms with new meanings. This glossary will clarify some of them. We call it Cloudlocal, try it for yourself.
The solution presented in this post takes approximately 15–30 minutes to deploy and consists of the following key components: Amazon OpenSearch Service Serverless maintains three indexes : the inventory index, the compatible parts index, and the owner manuals index. The following diagram illustrates how it works.
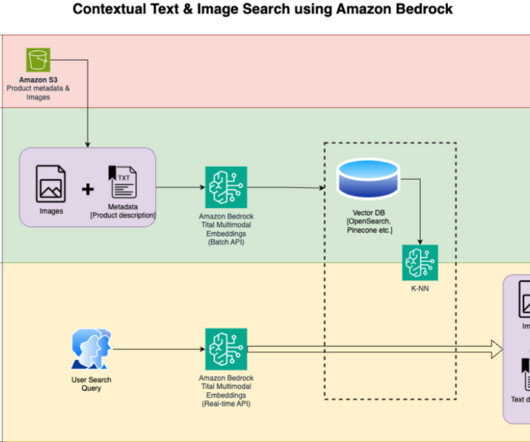
In this post, we show how to build a contextual text and image search engine for product recommendations using the Amazon Titan Multimodal Embeddings model , available in Amazon Bedrock , with Amazon OpenSearch Serverless. Store embeddings into the Amazon OpenSearch Serverless as the search engine. Review and prepare the dataset.
When serverless architecture became all the rage a few years ago, we wondered whether it was just marketing hype. Was serverless really cloud 2.0 Serverless architecture’s popularity has risen over the past 5 years. You don’t have to manage servers to run apps, storage systems, or databases at any scale.
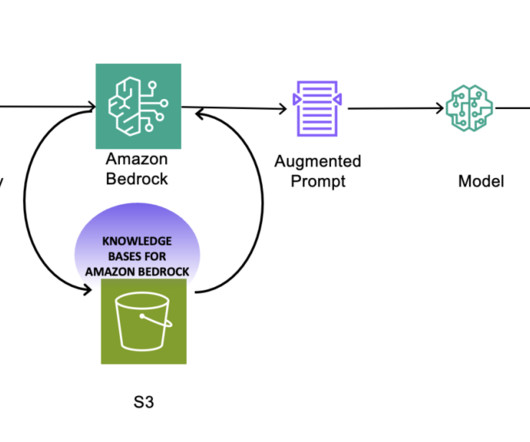
With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using the AWS tools without having to manage any infrastructure. The transcript is provided in tags. The following diagram illustrates the solution architecture.
If you’ve built a serverless application or two, you’re probably familiar with the benefits of serverless architecture. You take advantage of already built, managed cloud services to handle standard application requirements like authentication, storage, compute, API gateways, and a long list of other infrastructure needs.
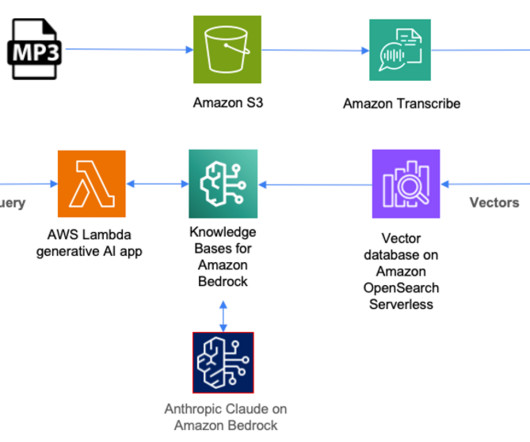
We explore how to build a fully serverless, voice-based contextual chatbot tailored for individuals who need it. The aim of this post is to provide a comprehensive understanding of how to build a voice-based, contextual chatbot that uses the latest advancements in AI and serverless computing. We discuss this later in the post.
“Awareness of FinOps practices and the maturity of software that can automate cloud optimization activities have helped enterprises get a better understanding of key cost drivers,” McCarthy says, referring to the practice of blending finance and cloud operations to optimize cloud spend.
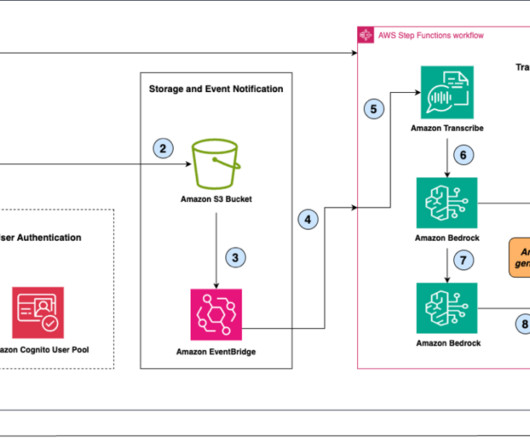
In the following sections, we walk you through constructing a scalable, serverless, end-to-end Public Speaking Mentor AI Assistant with Amazon Bedrock, Amazon Transcribe , and AWS Step Functions using provided sample code. Uploading audio files alone can optimize storage costs.
Because Amazon Bedrock is serverless, you don’t have to manage any infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with. For more details and specific model prices, refer to Amazon Bedrock Pricing.
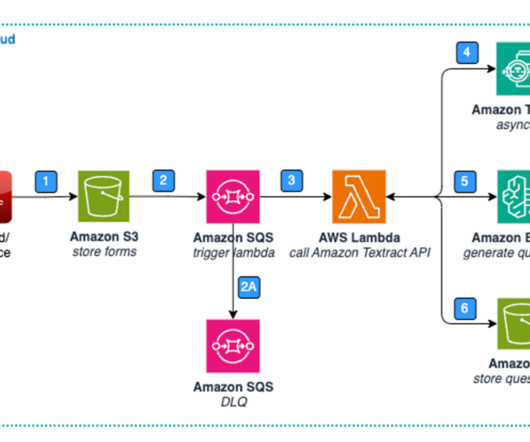
Handling large volumes of data, extracting unstructured data from multiple paper forms or images, and comparing it with the standard or reference forms can be a long and arduous process, prone to errors and inefficiencies. Figure 1: Architecture – Standard Form – Data Extraction & Storage.
Observability refers to the ability to understand the internal state and behavior of a system by analyzing its outputs, logs, and metrics. Cost optimization – This solution uses serverless technologies, making it cost-effective for the observability infrastructure. Additionally, you can choose what gets logged.
In this article, we are going to compare the leading cloud providers of serverless computing frameworks so that you have enough intel to make a sound decision when choosing one over the others. It provides a developer guide, API references, and sample applications for hands-on experience. For other services (i.e: Description.
Here are some features which we will cover: AWS CloudFormation support Private network policies for Amazon OpenSearch Serverless Multiple S3 buckets as data sources Service Quotas support Hybrid search, metadata filters, custom prompts for the RetreiveAndGenerate API, and maximum number of retrievals.
Last week, I joined an awesome lineup of speakers and serverless users in Tennessee for the inaugural ServerlessDays Nashville conference. Whether you help architect serverless applications at work or you’re just getting started in the community, chances are you’ve caught wind of a ServerlessDays event. Enter serverless.
Using Amazon Bedrock allows for iteration of the solution using knowledge bases for simple storage and access of call transcripts as well as guardrails for building responsible AI applications. This step is shown by business analysts interacting with QuickSight in the storage and visualization step through natural language.
Amazon Bedrock offers a serverless experience so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage infrastructure. Refer to the GitHub repository for deployment instructions.
Software-as-a-service (SaaS) applications with tenant tiering SaaS applications are often architected to provide different pricing and experiences to a spectrum of customer profiles, referred to as tiers. The user prompt is then routed to the LLM associated with the task category of the reference prompt that has the closest match.
Ground truth data in AI refers to data that is known to be factual, representing the expected use case outcome for the system being modeled. Document Section Targeting - Reference specific sections when the information location is relevant - Example: "In Section [X] of [Document Name], what are the steps for [specific process]?"
Organizations that have used Google Cloud Platform’s Cloud Functions – a serverless execution environment – could be impacted by a privilege escalation vulnerability discovered by Tenable and dubbed as “ConfusedFunction.” Cloud Functions in GCP are event-triggered, serverless functions. What are Cloud Functions?
In this solution, audio files stored in mp3 format are first uploaded to Amazon Simple Storage Service (Amazon S3) storage. For instructions on transcribing with the AWS Management Console or AWS CLI, refer to the Amazon Transcribe Developer guide. The title is the only metadata we need to manually add for each audio file.
Key features of AWS Batch Efficient Resource Management: AWS Batch automatically provisions the required resources, such as compute instances and storage, based on job requirements. This enables you to build end-to-end workflows that leverage the full range of AWS capabilities for data processing, storage, and analytics.
With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using the Amazon Web Services (AWS) tools without having to manage infrastructure. Data to manage sessions is automatically purged after 24 hours.
From simple mechanisms for holding data like punch cards and paper tapes to real-time data processing systems like Hadoop, data storage systems have come a long way to become what they are now. The top tier is referred to as the front-end or client layer. Snowflake, Redshift, BigQuery, and Others: Cloud Data Warehouse Tools Compared.
Serverless architecture has grown more popular since Amazon Web Services (AWS) introduced Lambda. Serverless allows the developer to focus only on the code itself. The New LAMP Stack: Serverless on AWS. In this tutorial, I’ll be covering how to use Bref to build a serverless Laravel application. Step 1: AWS User.
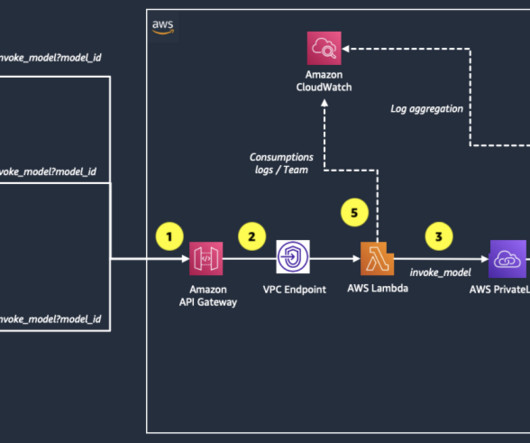
These logs can be delivered to multiple destinations, such as CloudWatch, Amazon Simple Storage Service (Amazon S3), or Amazon Data Firehose. Refer to Monitoring Amazon Q Business and Q Apps for more details. Guillermo has developed a keen interest in serverless architectures and generative AI applications.
This enables sales teams to interact with our internal sales enablement collateral, including sales plays and first-call decks, as well as customer references, customer- and field-facing incentive programs, and content on the AWS website, including blog posts and service documentation.
The output data is transformed to a standardized format and stored in a single location in Amazon S3 in Parquet format, a columnar and efficient storage format. Cost-effective – The solution should only invoke LLM to generate reusable code on an as-needed basis instead of manipulating the data directly to be as cost-effective as possible.
An Amazon Cognito identity pool grants temporary access to the Amazon Simple Storage Service (Amazon S3) bucket. DevOps From a DevOps perspective, the frontend uses Amplify to build and deploy, and the backend is uses AWS Serverless Application Model (AWS SAM) to build, package, and deploy the serverless applications.
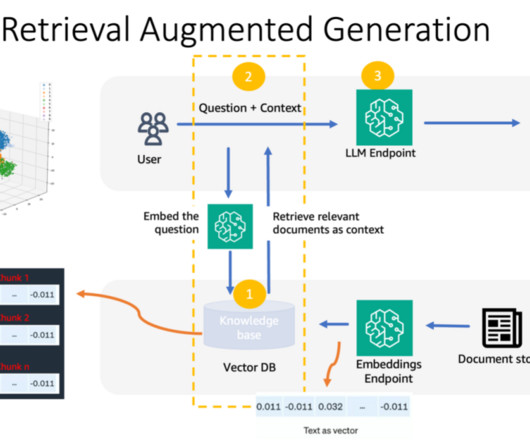
This domain knowledge is traditionally captured in reference manuals, service bulletins, quality ticketing systems, engineering drawings, and more, but the quantity and complexity of documents is growing and takes time to learn. In RAG, these knowledge sources are often referred to as a knowledge base. Try it out!
As the name suggests, a cloud service provider is essentially a third-party company that offers a cloud-based platform for application, infrastructure or storage services. In a public cloud, all of the hardware, software, networking and storage infrastructure is owned and managed by the cloud service provider. What Is a Public Cloud?
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content