This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Refer to Supported Regions and models for batch inference for current supporting AWS Regions and models. To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. An AWS Region from the list of batch inference supported Regions for Amazon Bedrock.
“AI deployment will also allow for enhanced productivity and increased span of control by automating and scheduling tasks, reporting and performance monitoring for the remaining workforce which allows remaining managers to focus on more strategic, scalable and value-added activities.”
The company says it can achieve PhD-level performance in challenging benchmark tests in physics, chemistry, and biology. In these uses case, we have enough reference implementations to point to and say, Theres value to be had here.' If it goes through all of those gates, only then do you let the agent do it autonomously, says Hodjat.
Tech roles are rarely performed in isolation. Example: A candidate might perform well in a calm, structured interview environment but struggle to collaborate effectively in high-pressure, real-world scenarios like product launches or tight deadlines. Why interpersonal skills matter in tech hiring ?
Proving that graphs are more accurate To substantiate the accuracy improvements of graph-enhanced RAG, Lettria conducted a series of benchmarks comparing their GraphRAG solutiona hybrid RAG using both vector and graph storeswith a baseline vector-only RAG reference.
Sovereign AI refers to a national or regional effort to develop and control artificial intelligence (AI) systems, independent of the large non-EU foreign private tech platforms that currently dominate the field. high-performance computing GPU), data centers, and energy.
Building applications from individual components that each perform a discrete function helps you scale more easily and change applications more quickly. Inline mapping The inline map functionality allows you to perform parallel processing of array elements within a single Step Functions state machine execution.
A recent evaluation conducted by FloTorch compared the performance of Amazon Nova models with OpenAIs GPT-4o. Amazon Nova is a new generation of state-of-the-art foundation models (FMs) that deliver frontier intelligence and industry-leading price-performance. Hemant Joshi, CTO, FloTorch.ai Each provisioned node was r7g.4xlarge,
While multi-cloud generally refers to the use of multiple cloud providers, hybrid encompasses both cloud and on-premises integrations, as well as multi-cloud setups. The scalable cloud infrastructure optimized costs, reduced customer churn, and enhanced marketing efficiency through improved customer segmentation and retention models.
In todays fast-paced digital landscape, the cloud has emerged as a cornerstone of modern business infrastructure, offering unparalleled scalability, agility, and cost-efficiency. Cracking this code or aspect of cloud optimization is the most critical piece for enterprises to strike gold with the scalability of AI solutions.
Alex Tabor, Paul Ascher and Juan Pascual met each other on the engineering team of Peixe Urbano, a company Tabor co-founded and he referred to as a “Groupon for Brazil.” Tuna is on a mission to “fine tune” the payments space in Latin America and has raised two seed rounds totaling $3 million, led by Canary and by Atlantico.
As successful proof-of-concepts transition into production, organizations are increasingly in need of enterprise scalable solutions. For details on all the fields and providing configuration of various vector stores supported by Knowledge Bases for Amazon Bedrock, refer to AWS::Bedrock::KnowledgeBase.
Key features of the release include: Customizable project templates for LLM output evaluation with support for HTML content, including hyperlinks to references. Two modes are supported: individual and side-by-side response evaluation. Inter-Annotator Agreement (IAA) charts are also available for those projects.
We present the reinforcement learning process and the benchmarking results to demonstrate the LLM performance improvement. You can refer to further explanations in the following resources:** * ARS GEN 10.0/05.01.02. Design Criteria & Appendices/Performance Package AR Sortable Design Criteria v20.1.1.pdf
How does High-Performance Computing on AWS differ from regular computing? For this HPC will bring massive parallel computing, cluster and workload managers and high-performance components to the table. It provides a powerful and scalable platform for executing large-scale batch jobs with minimal setup and management overhead.
Types of Workflows Types of workflows refer to the method or structure of task execution, while categories of workflows refer to the purpose or context in which they are used. Define the order in which tasks are performed. Manual Workflows: These are processes that require human intervention at each step.
Shared components refer to the functionality and features shared by all tenants. If it leads to better performance, your existing default prompt in the application is overridden with the new one. Refer to Perform AI prompt-chaining with Amazon Bedrock for more details. This logic sits in a hybrid search component.
Give each secret a clear name, as youll use these names to reference them in Synapse. Add a Linked Service to the pipeline that references the Key Vault. When setting up a linked service for these sources, reference the names of the secrets stored in Key Vault instead of hard-coding the credentials.
The following figure illustrates the performance of DeepSeek-R1 compared to other state-of-the-art models on standard benchmark tests, such as MATH-500 , MMLU , and more. To learn more about Hugging Face TGI support on Amazon SageMaker AI, refer to this announcement post and this documentation on deploy models to Amazon SageMaker AI.
In this post, we explore advanced prompt engineering techniques that can enhance the performance of these models and facilitate the creation of compelling imagery through text-to-image transformations. Large Medium – This refers to the material or technique used in creating the artwork. A photo of a (red:1.2)
If you don’t have an AWS account, refer to How do I create and activate a new Amazon Web Services account? If you don’t have an existing knowledge base, refer to Create an Amazon Bedrock knowledge base. Performance optimization The serverless architecture used in this post provides a scalable solution out of the box.
The agents also automatically call APIs to perform actions and access knowledge bases to provide additional information. Effective agent instructions are crucial for optimizing the performance of AI-powered assistants. For more information, refer to the PowerTools documentation on Amazon Bedrock Agents.
Their DeepSeek-R1 models represent a family of large language models (LLMs) designed to handle a wide range of tasks, from code generation to general reasoning, while maintaining competitive performance and efficiency. 70B-Instruct ), offer different trade-offs between performance and resource requirements.
In this blog post, we’ll dive deeper into the concept of multi-tenancy and explore how Django-multitenant can help you build scalable, secure, and maintainable multi-tenant applications on top of PostgreSQL and the Citus database extension. Distribute ( "Country" , reference = True ), tenant_migrations.
It arrives alongside the announcement of SAP’s Open Reference Architecture project as part of the EU’s IPCEI-CIS initiative. Organizations are choosing these platforms based on effective cost, performance, and scalability.”
there is an increasing need for scalable, reliable, and cost-effective solutions to deploy and serve these models. AWS Trainium and AWS Inferentia based instances, combined with Amazon Elastic Kubernetes Service (Amazon EKS), provide a performant and low cost framework to run LLMs efficiently in a containerized environment.
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. This scalability allows for more frequent and comprehensive reviews.
Governance in the context of generative AI refers to the frameworks, policies, and processes that streamline the responsible development, deployment, and use of these technologies. For a comprehensive read about vector store and embeddings, you can refer to The role of vector databases in generative AI applications.
The model demonstrates improved performance in image quality, typography, and complex prompt understanding. Finally, use the generated images as reference material for 3D artists to create fully realized game environments. For instructions, refer to Clean up Amazon SageMaker notebook instance resources.
They are committed to enhancing the performance and capabilities of AI models, with a particular focus on large language models (LLMs) for use with Einstein product offerings. LMI containers are a set of high-performance Docker Containers purpose built for LLM inference. When the team initially deployed CodeGen 2.5,
AWS Prototyping successfully delivered a scalable prototype, which solved CBRE’s business problem with a high accuracy rate (over 95%) and supported reuse of embeddings for similar NLQs, and an API gateway for integration into CBRE’s dashboards. CBRE, in parallel, completed UAT testing to confirm it performed as expected.
To accelerate iteration and innovation in this field, sufficient computing resources and a scalable platform are essential. With these capabilities, customers are adopting SageMaker HyperPod as their innovation platform for more resilient and performant model training, enabling them to build state-of-the-art models faster.
For some content, additional screening is performed to generate subtitles and captions. As DPG Media grows, they need a more scalable way of capturing metadata that enhances the consumer experience on online video services and aids in understanding key content characteristics.
But when the size of a dbt project grows, and the number of developers increases, then an automated approach is often the only scalable way forward. What other checks can dbt-bouncer perform? check_exposure_based_on_view ensures exposures are not based on views as this may result in poor performance for data consumers.
Distillation refers to a process of training smaller, more efficient models to mimic the behavior and reasoning patterns of the larger DeepSeek-R1 model, using it as a teacher model. For example, DeepSeek-R1-Distill-Llama-8B offers an excellent balance of performance and efficiency. For details, refer to Create an AWS account.
As these AI technologies become more sophisticated and widely adopted, maintaining consistent quality and performance becomes increasingly complex. For applications requiring high performance content generation with lower latency and costs, model distillation can be an effective solution to use for creating a generator model, for example.
Asure anticipated that generative AI could aid contact center leaders to understand their teams support performance, identify gaps and pain points in their products, and recognize the most effective strategies for training customer support representatives using call transcripts. For example, Anthropics Claude Sonnet 3.5
Observability refers to the ability to understand the internal state and behavior of a system by analyzing its outputs, logs, and metrics. For a detailed breakdown of the features and implementation specifics, refer to the comprehensive documentation in the GitHub repository.
They provide a direct, owned line of communication with your audience; nearly 40x return on investment (~$40 generated per every dollar spent), are infinitely scalable and virtually free. On average, they convert 3% of site visitors, and strategic, high-performing pop-ups can reach conversion of about 10%.
IaC enables developers to define infrastructure configurations using code, ensuring consistency, automation, and scalability. Scalability: Easily replicate infrastructure across multiple environments and regions. AWS CloudFormation Macros: Use macros to extend template functionality and perform custom transformations.
It enables marketers to build personalized emails, manage subscriber data, and monitor campaign performance, all within a unified platform. Analytics and Reporting Measure performance with detailed reports on key metrics like open, click-through, and conversion rates.
This counting service, built on top of the TimeSeries Abstraction, enables distributed counting at scale while maintaining similar low latency performance. In this context, they refer to a count very close to accurate, presented with minimal delays. Today, we’re excited to present the Distributed Counter Abstraction.
This capability enables Anthropics Claude models to identify whats on a screen, understand the context of UI elements, and recognize actions that should be performed such as clicking buttons, typing text, scrolling, and navigating between applications. He is passionate about building scalable software solutions that solve customer problems.
DARPA also funded Verma’s research into in-memory computing for machine learning computations — “in-memory,” here, referring to running calculations in RAM to reduce the latency introduced by storage devices. sets of AI algorithms) while remaining scalable.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














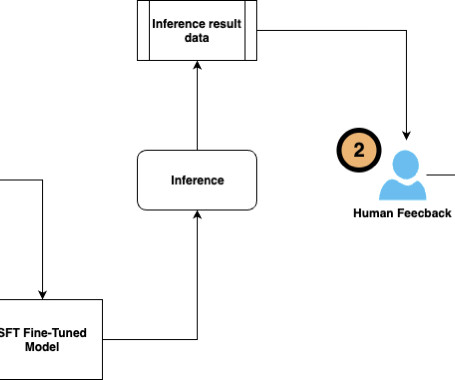






































Let's personalize your content