This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Factors such as precision, reliability, and the ability to perform convincingly in practice are taken into account. These are standardized tests that have been specifically developed to evaluate the performance of language models. They not only test whether a model works, but also how well it performs its tasks.
Although an individual LLM can be highly capable, it might not optimally address a wide range of use cases or meet diverse performance requirements. In contrast, more complex questions might require the application to summarize a lengthy dissertation by performing deeper analysis, comparison, and evaluation of the research results.
The company says it can achieve PhD-level performance in challenging benchmark tests in physics, chemistry, and biology. In these uses case, we have enough reference implementations to point to and say, Theres value to be had here.' If it goes through all of those gates, only then do you let the agent do it autonomously, says Hodjat.
AI deployment will also allow for enhanced productivity and increased span of control by automating and scheduling tasks, reporting and performance monitoring for the remaining workforce which allows remaining managers to focus on more strategic, scalable and value-added activities.”
You can use these agents through a process called chaining, where you break down complex tasks into manageable tasks that agents can perform as part of an automated workflow. It’s important to break it down this way so you can see beyond the hype and understand what is specifically being referred to. Do you see any issues?
Deepak Jain, 49, of Potomac, was the CEO of an information technology services company (referred to in the indictment as Company A) that provided data center services to customers, including the SEC,” the US DOJ said in a statement. From 2012 through 2018, the SEC paid Company A approximately $10.7
Aftermarket performance is also not following a dramatic storyline. Top tech performers Among larger tech offerings, the faraway winner this year is Reddit. Top biotech performers Biotech companies that debuted on public markets this year also saw plenty of ups and downs. Just a handful of U.S. tech unicorns made it to market.
Tech roles are rarely performed in isolation. Example: A candidate might perform well in a calm, structured interview environment but struggle to collaborate effectively in high-pressure, real-world scenarios like product launches or tight deadlines. Why interpersonal skills matter in tech hiring ?
Samsung, in particular, is in a bind as it has struggled to gain a foothold in AI and now has to give up one of its largest markets in China,” said Park, referring to the significant share of Samsung’s HBM chip sales generated in the Chinese market.
It is intended to improve a models performance and efficiency and sometimes includes fine-tuning a model on a smaller, more specific dataset. These improvements in inference performance make the family of models capable of handling more complex reasoning tasks, Briski said, which in turn reduce operational costs for enterprises.
These changes can cause many more unexpected performance and availability issues. IT leaders are looking for good AI content that their employees can reference, plus opportunities for employees to develop AI skills. At the same time, the scale of observability data generated from multiple tools exceeds human capacity to manage.
Thinking refers to an internal reasoning process using the first output tokens, allowing it to solve more complex tasks. Built-in Evaluation: Systematically assess agent performance. In this post, I’m excited to share some of my personal highlights and key takeaways from the conference. Gemini 2.5
In this post, we demonstrate how to effectively perform model customization and RAG with Amazon Nova models as a baseline. Model customization refers to adapting a pre-trained language model to better fit specific tasks, domains, or datasets. Optimized for cost-effective performance, they are trained on data in over 200 languages.
This process involves updating the model’s weights to improve its performance on targeted applications. The result is a significant improvement in task-specific performance, while potentially reducing costs and latency. However, achieving optimal performance with fine-tuning requires effort and adherence to best practices.
And to ensure a strong bench of leaders, Neudesic makes a conscious effort to identify high performers and give them hands-on leadership training through coaching and by exposing them to cross-functional teams and projects. “But for practical learning of the same technologies, we rely on the internal learning academy we’ve established.”
The term “ghost work,” popularized by researchers Mary Gray and Siddartha Suri in 2019 , refers to work performed remotely in the digital space, such as content marketing or proofreading, without formal employment status.
If you don’t have an AWS account, refer to How do I create and activate a new Amazon Web Services account? If you don’t have an existing knowledge base, refer to Create an Amazon Bedrock knowledge base. Performance optimization The serverless architecture used in this post provides a scalable solution out of the box.
An abundance of choice In the most general definition, open source here refers to the code thats available, and that the model can be modified and used for free in a variety of contexts. Agus Huerta, SVP of digital innovation and VP of technology at Globant, says hes seen better performance on code generation using Llama 3 than ChatGPT.
However, in today’s dynamic markets, past performance alone is no longer a reliable predictor of future success. What previously was referred to as soft skills are becoming core skills and are increasingly seen as necessary in navigating uncertain markets and leading teams through periods of intense growth.
However, some top-performing companies manage to fill positions in as little as 14 days, especially when leveraging automated screening tools and skill-based assessments. It evaluates how well new employees perform in their roles and how they contribute to the organization.
Refer to Supported Regions and models for batch inference for current supporting AWS Regions and models. For instructions on how to start your Amazon Bedrock batch inference job, refer to Enhance call center efficiency using batch inference for transcript summarization with Amazon Bedrock.
The agents also automatically call APIs to perform actions and access knowledge bases to provide additional information. Effective agent instructions are crucial for optimizing the performance of AI-powered assistants. For more information, refer to the PowerTools documentation on Amazon Bedrock Agents.
In this post, we explore advanced prompt engineering techniques that can enhance the performance of these models and facilitate the creation of compelling imagery through text-to-image transformations. Large Medium – This refers to the material or technique used in creating the artwork. A photo of a (red:1.2)
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
In Agile environments, maintaining focus is crucial to achieving optimal performance, especially in complex tasks like software development. Whether in physical activity or intellectual work, there is a strong correlation between the right level of arousal and optimal performance. References Robert M. Yerkes & John D.
The following figure illustrates the performance of DeepSeek-R1 compared to other state-of-the-art models on standard benchmark tests, such as MATH-500 , MMLU , and more. To learn more about Hugging Face TGI support on Amazon SageMaker AI, refer to this announcement post and this documentation on deploy models to Amazon SageMaker AI.
Shared components refer to the functionality and features shared by all tenants. If it leads to better performance, your existing default prompt in the application is overridden with the new one. Refer to Perform AI prompt-chaining with Amazon Bedrock for more details. This logic sits in a hybrid search component.
A recent evaluation conducted by FloTorch compared the performance of Amazon Nova models with OpenAIs GPT-4o. Amazon Nova is a new generation of state-of-the-art foundation models (FMs) that deliver frontier intelligence and industry-leading price-performance. Hemant Joshi, CTO, FloTorch.ai Each provisioned node was r7g.4xlarge,
Building applications from individual components that each perform a discrete function helps you scale more easily and change applications more quickly. Inline mapping The inline map functionality allows you to perform parallel processing of array elements within a single Step Functions state machine execution.
Digital experience interruptions can harm customer satisfaction and business performance across industries. NR AI responds by analyzing current performance data and comparing it to historical trends and best practices. This report provides clear, actionable recommendations and includes real-time application performance insights.
These models are tailored to perform specialized tasks within specific domains or micro-domains. They can host the different variants on a single EC2 instance instead of a fleet of model endpoints, saving costs without impacting performance. For the full list of available kernels, refer to available Amazon SageMaker kernels.
This is particularly beneficial for tasks like automatically processing receipts or invoices, where it can perform calculations and context-aware evaluations, streamlining processes such as expense tracking or financial analysis. It can effortlessly identify trends, anomalies, and key data points within graphical visualizations.
Observability refers to the ability to understand the internal state and behavior of a system by analyzing its outputs, logs, and metrics. For a detailed breakdown of the features and implementation specifics, refer to the comprehensive documentation in the GitHub repository.
Security and compliance regulations require that security teams audit the actions performed by systems administrators using privileged credentials. Video recordings cant be easily parsed like log files, requiring security team members to playback the recordings to review the actions performed in them.
However, improper memory handling can lead to memory leaks, causing your application to consume more memory than necessary and eventually degrade in performance. Monitor Performance Record memory usage using the Performance tab to detect increasing trends. What are Memory Leaks? Happy coding!
Performing an intelligent search on emails with co-workers can help you find answers to questions, improving productivity and enhancing the overall customer experience for the organization. The user’s credentials from the IdP or IAM Identity Center are referred to here as the federated user credentials. Scopes for Google APIs.
For generative AI models requiring multiple instances to handle high-throughput inference requests, this added significant overhead to the total scaling time, potentially impacting application performance during traffic spikes. We ran 5+ scaling simulations and observed consistent performance with low variations across trials.
Authentication is performed against the Amazon Cognito user pool. For more details about the authentication and authorization flows, refer to Accessing AWS services using an identity pool after sign-in. For additional details, refer to Creating a new user in the AWS Management Console.
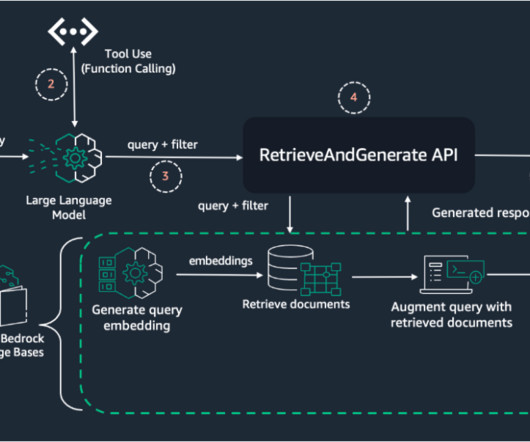
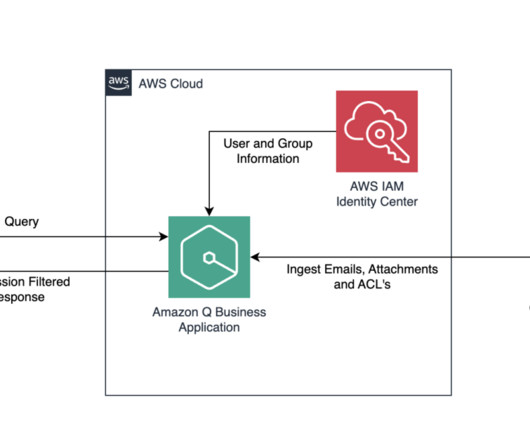
For more on MuleSofts journey to cloud computing, refer to Why a Cloud Operating Model? The following diagram shows the reference architecture for various personas, including developers, support engineers, DevOps, and FinOps to connect with internal databases and the web using Amazon Q Business.
” “[Foundry allows] inference at scale with full control over the model configuration and performance profile,” the documentation reads. The context window refers to the text that the model considers before generating additional text; longer context windows allow the model to “remember” more text essentially.)
You may check out additional reference notebooks on aws-samples for how to use Meta’s Llama models hosted on Amazon Bedrock. I will supply multiple instances with features and the corresponding label for reference. High five-year return**: Funds with higher fiveyearreturncur indicate better performance over the past 5 years.
Types of Workflows Types of workflows refer to the method or structure of task execution, while categories of workflows refer to the purpose or context in which they are used. Define the order in which tasks are performed. Manual Workflows: These are processes that require human intervention at each step.
The model demonstrates improved performance in image quality, typography, and complex prompt understanding. Finally, use the generated images as reference material for 3D artists to create fully realized game environments. For instructions, refer to Clean up Amazon SageMaker notebook instance resources.
.” Anthropic describes the frontier model as a “next-gen algorithm for AI self-teaching,” making reference to an AI training technique it developed called “constitutional AI.” “These models could begin to automate large portions of the economy,” the pitch deck reads.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content