This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To solve the problem, the company turned to gen AI and decided to use both commercial and opensource models. With security, many commercial providers use their customers data to train their models, says Ringdahl. So we augment with opensource, he says. Its possible to opt-out, but there are caveats.
The move relaxes Meta’s acceptable use policy restricting what others can do with the large language models it develops, and brings Llama ever so slightly closer to the generally accepted definition of open-source AI. As long as Meta keeps the training data confidential, CIOs need not be concerned about data privacy and security.
In a step toward solving it, OpenAI today open-sourced Whisper, an automatic speech recognition system that the company claims enables “robust” transcription in multiple languages as well as translation from those languages into English. Speech recognition remains a challenging problem in AI and machine learning.
Media outlets and entertainers have already filed several AI copyright cases in US courts, with plaintiffs accusing AI vendors of using their material to train AI models or copying their material in outputs, notes Jeffrey Gluck, a lawyer at IP-focused law firm Panitch Schwarze. How was the AI trained?
The founders of Speckle , an early-stage startup based in London, are both trained architects and engineers, probably a rare combination. They wanted to make it easier by building an opensource platform to exchange and collaborate on these files. ” The two founders began looking at this problem in 2015.
Jorge Torres is CEO and co-founder of MindsDB , an opensource AI layer for existing databases. Adam Carrigan is a co-founder and COO of MindsDB , an opensource AI layer for existing databases. Open-source software gave birth to a slew of useful software in recent years. Contributor. Share on Twitter.
For many, ChatGPT and the generative AI hype train signals the arrival of artificial intelligence into the mainstream. Just last year, a similar proposition to Qdrant called Pinecone nabbed $28 million , though Zayarni considers Qdrant’s opensource foundation as a major selling point for would-be customers.
With Together, Prakash, Zhang, Re and Liang are seeking to create opensource generative AI models and services that, in their words, “help organizations incorporate AI into their production applications.” The number of opensource models both from community groups and large labs grows by the day , practically.
Even if you don’t have the training data or programming chops, you can take your favorite opensource model, tweak it, and release it under a new name. According to Stanford’s AI Index Report, released in April, 149 foundation models were released in 2023, two-thirds of them opensource.
On Thursday, a large group of university and private industry researchers unveiled Genesis, a new opensource computer simulation system that lets robots practice tasks in simulated reality 430,000 times faster than in the real world. Researchers can also use an AI agent to generate 3D physics simulations from text prompts.
But so far, only a handful of such AI systems have been made freely available to the public and opensourced — reflecting the commercial incentives of the companies building them. billion parameters) — using ServiceNow’s in-house graphics card cluster.
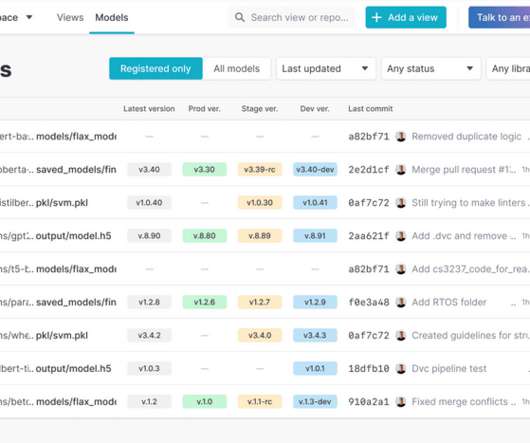
MLOps platform Iterative , which announced a $20 million Series A round almost exactly a year ago, today launched MLEM, an open-source git-based machine learning model management and deployment tool. For highly regulated industries, a system like this also offers a single source of truth for figuring out the lineage of a given model.
The nonpartisan think tank Brookings this week published a piece decrying the bloc’s regulation of opensource AI, arguing it would create legal liability for general-purpose AI systems while simultaneously undermining their development. “In the end, the [E.U.’s] “In the end, the [E.U.’s]
Training a frontier model is highly compute-intensive, requiring a distributed system of hundreds, or thousands, of accelerated instances running for several weeks or months to complete a single job. For example, pre-training the Llama 3 70B model with 15 trillion training tokens took 6.5 During the training of Llama 3.1
Opensource has seen a great deal of momentum among mainframers, making collaboration easier and providing greater transparency. But for all of its benefits, opensource is not without risks. By its very nature, open-source code is accessible to whoever wants to see it—including potential attackers.
Now, another new company has entered the community-led growth fray with a slightly different approach to the existing players, one focused on developer communities and with opensource at its core. The opensource factor. Transitioning to an opensource platform may hold other benefits, too. million ($2.2
Given the tremendous barrier to entry, is it worth considering whether opensource foundation models could level the playing field and also address concerns about privacy and bias?
Heartex, a startup that bills itself as an “opensource” platform for data labeling, today announced that it landed $25 million in a Series A funding round led by Redpoint Ventures. When asked, Heartex says that it doesn’t collect any customer data and opensources the core of its labeling platform for inspection.
Last April, Google launched Grow with Google Career Readiness for Reentry, a program created in partnership with nonprofits to offer job readiness and digital skills training for formerly incarcerated individuals. ” Meanwhile, Google.org, Google’s charitable arm, will provide $4.25 ”
Generative AI companies continue to raise huge amounts of capital to fuel their commercial — and, in some cases, opensource — ambitions. See Together, a startup creating opensource generative AI and AI model development infrastructure, which today announced that it closed a $102.5
Two companies behind popular AI art tools, Midjourney and Stability AI, are entangled in a legal case that alleges they infringed on the rights of millions of artists by training their tools on web-scraped images. Bria isn’t the only venture exploring a revenue-sharing business model for generative AI.
In these cases, the AI sometimes fabricated unrelated phrases, such as “Thank you for watching!” — likely due to its training on a large dataset of YouTube videos. million downloads on the open-source AI platform HuggingFace in the past month, Whisper has become one of the most popular speech recognition models. With over 4.2
With those tools involved, users can build new AI models on relatively low-powered machines, saving heavy-duty units for the compute-intensive process of model training. In other cases, the model might scan and process open-source data.
It’s only as good as the models and data used to train it, so there is a need for sourcing and ingesting ever-larger data troves. But annotating and manipulating that training data takes a lot of time and money, slowing down the work or overall effectiveness, and maybe both. V7’s specific USP is automation.
Explosion , a company that has combined an opensource machine learning library with a set of commercial developer tools, announced a $6 million Series A today on a $120 million valuation. Since then, that opensource project has been downloaded over 40 million times. .
Check out a new framework for better securing opensource projects. 1 - New cybersecurity framework for opensource projects Heres the latest industry effort aimed at boosting open-source software security. Plus, learn how AI is making ransomware harder to detect and mitigate.
There are two main considerations associated with the fundamentals of sovereign AI: 1) Control of the algorithms and the data on the basis of which the AI is trained and developed; and 2) the sovereignty of the infrastructure on which the AI resides and operates.
You pull an open-source large language model (LLM) to train on your corporate data so that the marketing team can build better assets, and the customer service team can provide customer-facing chatbots. And all of that data is stored on premises, but your training is taking place on the cloud where your GPUs live.
Stability AI, the company funding the development of opensource music- and image-generating systems like Dance Diffusion and Stable Diffusion , today announced that it raised $101 million in a funding round led by Coatue and Lightspeed Venture Partners with participation from O’Shaughnessy Ventures LLC. Image Credits: Daniel Jeffries.
Different ways to customize an LLM include fine-tuning an off-the-shelf model or building a custom one using an open-source LLM like Meta ’s Llama. Vertical-specific training data Does the startup have access to a large volume of proprietary, vertical-specific data to train its LLMs?
The legal spats between artists and the companies training AI on their artwork show no sign of abating. Generative AI models “learn” to create art, code and more by “training” on sample images and text, usually scraped indiscriminately from the web. By late April, that figure had eclipsed 1 billion.
Reentering society after years in prison is difficult for many reasons, among which perhaps the most prosaic is simply that it’s hard to get a job — and what training and transition programs exist are far from sufficient. “There’s already money for training, but it’s under-utilized,” explained Saruhashi.
. “[We are] introducing a database for AI, specifically a storage layer that helps to very efficiently store the data and then stream this to machine learning applications or training models to do computer vision, audio processing, NLP (natural language processing) and so on,” Buniatyan explained. Activeloop image database.
Stability AI , the startup behind the generative AI art tool Stable Diffusion , today open-sourced a suite of text-generating AI models intended to go head to head with systems like OpenAI’s GPT-4. But Stability AI claims it created a custom training set that expands the size of the standard Pile by 3x. make up) facts.
Google is open-sourcing SynthID, a system for watermarking text so AI-generated documents can be traced to the LLM that generated them. Unlike many of Mistral’s previous small models, these are not opensource. This model is based on the opensource Llama, and it’s relatively small (70B parameters).
Webiny , an early-stage startup that launched in 2019 with an open-source, serverless CMS, had also developed a framework to help build the CMS, and found that customers were also interested in that to help build their own serverless apps. Webiny announces $348K seed to build open-source serverless CMS.
Check out why memory vulnerabilities are widespread in opensource projects. The agencies analyzed 172 projects that the OpenSource Security Foundation has identified as being critically important in the opensource ecosystem. And learn how confidential data from U.S. And much more!
It uses OpenAI’s Codex, a language model trained on a vast amount of code from public repositories on GitHub. Cons Privacy Concerns : Since it is trained on public repositories, there may be concerns about code privacy and intellectual property. OpenSource : Being open-source, it is freely available for use and customization.
Natural language processing ( NLP ), while hardly a new discipline, has catapulted into the public consciousness these past few months thanks in large part to the generative AI hype train that is ChatGPT. The company also says that its basic opensource incarnation has been used by data scientists at companies such as Samsung and DocuSign.
LLM or large language models are deep learning models trained on vast amounts of linguistic data so they understand and respond in natural language (human-like texts). It is an open-source model that offers extensive fine-tuning capabilities using reinforcement learning (based on human response).
Lorna Mitchell is head of Developer Relations at Aiven , a software company that combines the best opensource technologies with cloud infrastructure. Some companies offer generous training budgets or time off. Many developers give much of their time to opensource projects. Lessons from opensource.
Key to its success is that its open-source project Seldon Core has more than 700,000 models deployed to date, drastically reducing friction for users deploying ML models. Seldon has been able to build an impressive open-source community and add immediate productivity value to some of the world’s leading companies.”
Weve also seen the emergence of agentic AI, multi-modal AI, reasoning AI, and open-source AI projects that rival those of the biggest commercial vendors. Developers must comply by the start of 2026, meaning theyll have a little over a year to put systems in place to track the provenance of their training data.
Onehouse emerged last year with a cloud data lake product built on top of the opensource Apache Hudi project. Company founder and CEO Vinoth Chandar came up with the idea for Hudi while he was an engineer at Uber in 2016, and eventually decided to start a company based on the opensource project.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content