This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
There are two main approaches: Reference-based metrics: These metrics compare the generated response of a model with an ideal reference text. A classic example is BLEU, which measures how closely the word sequences in the generated response match those of the reference text.
Agentic AI is the next leap forward beyond traditional AI to systems that are capable of handling complex, multi-step activities utilizing components called agents. He believes these agentic systems will make that possible, and he thinks 2025 will be the year that agentic systems finally hit the mainstream. They have no goal.
Understanding and tracking the right software delivery metrics is essential to inform strategic decisions that drive continuous improvement. This means creating environments that enable innovation while ensuring system integrity and sustainability. Documentation and diagrams transform abstract discussions into something tangible.
Ground truth data in AI refers to data that is known to be factual, representing the expected use case outcome for the system being modeled. By providing an expected outcome to measure against, ground truth data unlocks the ability to deterministically evaluate system quality.
This post shows how DPG Media introduced AI-powered processes using Amazon Bedrock and Amazon Transcribe into its video publication pipelines in just 4 weeks, as an evolution towards more automated annotation systems. The project focused solely on audio processing due to its cost-efficiency and faster processing time.
Model customization refers to adapting a pre-trained language model to better fit specific tasks, domains, or datasets. On the Review and create page, review the settings and choose Create Knowledge Base. To do so, we create a knowledge base. Choose Next. For Job name , enter a name for the fine-tuning job.
By monitoring utilization metrics, organizations can quantify the actual productivity gains achieved with Amazon Q Business. Tracking metrics such as time saved and number of queries resolved can provide tangible evidence of the services impact on overall workplace productivity.
When possible, refer all matters to committees for “further study and consideration” Attempt to make committees as large as possible — never less than five. Refer back to matters decided upon at the last meeting and attempt to re-open the question of the advisability of that decision. What are some things you can do?
Training a frontier model is highly compute-intensive, requiring a distributed system of hundreds, or thousands, of accelerated instances running for several weeks or months to complete a single job. As cluster sizes grow, the likelihood of failure increases due to the number of hardware components involved. million H100 GPU hours.
While traditional search systems are bound by the constraints of keywords, fields, and specific taxonomies, this AI-powered tool embraces the concept of fuzzy searching. One of the most compelling features of LLM-driven search is its ability to perform "fuzzy" searches as opposed to the rigid keyword match approach of traditional systems.
This learning practice aims to create a system of learning by which both students and educators learn from each other and create a system of knowledge capital. Knowledge capital is often referred to as the intangible assets of a company. Understanding Knowledge Capital. How is the team different from the others?
In short, observability costs are spiking because were gathering more signals and more data to describe our increasingly complex systems, and the telemetry data itself has gone from being an operational concern that only a few people care about to being an integral part of the development processsomething everyone has to care about.
Customer reviews can reveal customer experiences with a product and serve as an invaluable source of information to the product teams. By continually monitoring these reviews over time, businesses can recognize changes in customer perceptions and uncover areas of improvement.
We also provide insights on how to achieve optimal results for different dataset sizes and use cases, backed by experimental data and performance metrics. The evaluation metric is the F1 score that measures the word-to-word matching of the extracted content between the generated output and the ground truth answer.
For a comprehensive overview of metadata filtering and its benefits, refer to Amazon Bedrock Knowledge Bases now supports metadata filtering to improve retrieval accuracy. To evaluate the effectiveness of a RAG system, we focus on three key metrics: Answer relevancy – Measures how well the generated answer addresses the user’s query.
It empowers team members to interpret and act quickly on observability data, improving system reliability and customer experience. It allows you to inquire about specific services, hosts, or system components directly. This comprehensive approach speeds up troubleshooting, minimizes downtime, and boosts overall system reliability.
The code has been reviewed, and all the tests pass. Or they deal with external data fed into the system. If the new feature has not been explored in a test system, there is a risk that it is not working properly. The main reason for this is that the environment in production is more complex than in the test system.
Although GPT-4o has gained traction in the AI community, enterprises are showing increased interest in Amazon Nova due to its lower latency and cost-effectiveness. This is a crucial requirement for enterprises that want their AI systems to provide responses strictly within a defined scope. Each provisioned node was r7g.4xlarge,
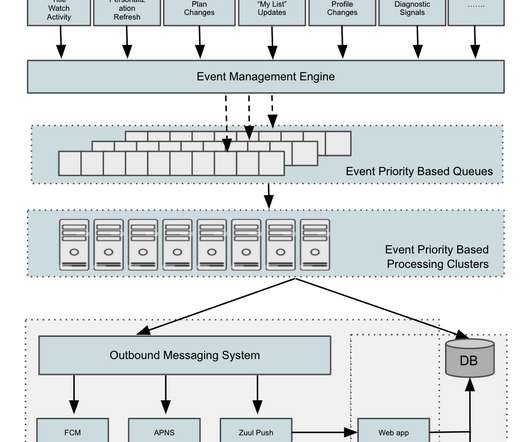
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. In this blog post, we will give an overview of the Rapid Event Notification System at Netflix and share some of the learnings we gained along the way.
For instance, Pixtral Large is highly effective at spotting irregularities or insightful trends within training loss curves or performance metrics, enhancing the accuracy of data-driven decision-making. It can effortlessly identify trends, anomalies, and key data points within graphical visualizations.
Amazon Bedrock also allows you to choose various models for different use cases, making it an obvious choice for the solution due to its flexibility. The human-in-the-loop UI plus Ragas metrics proved effective to evaluate outputs of FMs used throughout the pipeline. In addition, traditional ML metrics were used for Yes/No answers.
With the industry moving towards end-to-end ML teams to enable them to implement MLOPs practices, it is paramount to look past the model and view the entire system around your machine learning model. The classic article on Hidden Technical Debt in Machine Learning Systems explains how small the model is compared to the system it operates in.
Each OKR can also have initiatives that refer to the work required to do to drive progress. This concept is mainly a metricsystem where there is an initial or starting and target value measuring progress towards an objective or goal. You review these OKRs annually or quarterly to keep track of your progress.
Value streams refer to the set of processes by which an organization creates value for its customers, which can be internal users or external consumers or clients. Apply systems thinking into all facets of development. Base milestones on objective estimation and evaluation of working systems to ensure there is an economic benefit.
It is designed to handle the demanding computational and latency requirements of state-of-the-art transformer models, including Llama, Falcon, Mistral, Mixtral, and GPT variants for a full list of TGI supported models refer to supported models. For a complete list of runtime configurations, please refer to text-generation-launcher arguments.
Types of Workflows Types of workflows refer to the method or structure of task execution, while categories of workflows refer to the purpose or context in which they are used. Approval Workflow: Approval workflows are designed for tasks requiring review or authorization at various stages. Speed is critical when incidents occur.
This post focuses on evaluating and interpreting metrics using FMEval for question answering in a generative AI application. FMEval is a comprehensive evaluation suite from Amazon SageMaker Clarify , providing standardized implementations of metrics to assess quality and responsibility. Question Answer Fact Who is Andrew R.
Response latency refers to the time between the user finishing their speech and beginning to hear the AI assistants response. This latency can vary considerably due to geographic distance between users and cloud services, as well as the diverse quality of internet connectivity. Next, create a subnet inside each Local Zone.
A report by the Harvard Business Review states that companies that adopt Agile processes, experience 60% in revenue and profit growth. That said, businesses need to be acquainted with an aspect of Agile called the agile metrics to effectively reap the benefits. What exactly is Agile Metrics? . Agile Quality Metrics.
Shared components refer to the functionality and features shared by all tenants. Refer to Perform AI prompt-chaining with Amazon Bedrock for more details. Additionally, contextual grounding checks can help detect hallucinations in model responses based on a reference source and a user query.
According to a 2020 Statista survey , 41% of executives in the automotive and transportation industry alone said their company lost $50 to $100 million due to supply chain issues, a figure which has likely climbed higher since. But according to Komoni, most tracking is done manually via loose systems of emails, spreadsheets and phone calls.
Get a basic understanding of distributed systems and then go deeper with recommended resources. These always-on and always-available expectations are handled by distributed systems, which manage the inevitable fluctuations and failures of complex computing behind the scenes. “The Benefits of distributed systems.
Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5% You can review the Mistral published benchmarks Prerequisites To try out Pixtral 12B in Amazon Bedrock Marketplace, you will need the following prerequisites: An AWS account that will contain all your AWS resources.
That’s why we need metrics. When it comes to DevOps, the metrics should suit specific practices and processes, so the progress becomes measurable. In this article, we’ll explore some of the most important metrics used to track DevOps processes and measure their success. So let’s discuss it before we jump to actual metrics.
When multiple independent but interactive agents are combined, each capable of perceiving the environment and taking actions, you get a multiagent system. NASA’s Jet Propulsion Laboratory, for example, uses multiagent systems to ensure its clean rooms stay clean so nothing contaminates flight hardware bound for other planets.
She wasn’t referring to the sophistication of the tools, but the way in which the hardware production toolset is balkanized across both teams and tasks. To work around this problem, teams will usually hire a system engineer or a technical program manager to manually maintain a source of truth between the different tools.
The cloud CoE team of architects should work with the EA to align with the reference architecture patterns that the CoE team would like the application teams/product teams to follow in their solution design. First, the mean part.
The lens system proposed by Glass isn’t quite the same, but it uses similar principles and unusually shaped lenses. Here’s a little chart for casual reference: Image Credits: Devin Coldewey / TechCrunch. It started from the fundamental idea of how to add a larger sensor. Bigger, brighter and a bit weirder.
Gain clarity before committing: Interviews and references IT leaders need to make sure the consultants they’re hiring have extensive experience in the company’s industry and markets and will focus on its specific needs. Schedule regular check-in meetings to review progress, address any concerns, and ensure alignment with the client’s goals.
Governance in the context of generative AI refers to the frameworks, policies, and processes that streamline the responsible development, deployment, and use of these technologies. For a comprehensive read about vector store and embeddings, you can refer to The role of vector databases in generative AI applications.
Characteristics of Key Results : Refers to the “results” that you seek. Thus, it should include a Key Performance Indicator (KPI) that is quantified through a metric. Step #4: Review and analyse. You may find yourself revising your objectives or key results as you review your initial list. Must be measurable.
This framework explores how institutions can move beyond performative gestures toward authentic integration of responsible design principles throughout their operations, creating systems that consistently produce outcomes aligned with broader societal values and planetary boundaries. The Institutional Imperative What is Responsible Design?
Mean time to repair (MTTR), sometimes referred to as mean time to resolution, is a popular DevOps and site reliability engineering (SRE) team metric. Sometimes, MTTR refers to mean time to respond: the amount of time needed to react to a problem. MTTR tells us how much time it takes to return to a healthy and stable system.
Software systems are increasingly complex. Observability is not just a buzzword; it’s a fundamental shift in how we perceive and manage the health, performance, and behavior of software systems. Observability starts by collecting system telemetry data, such as logs, metrics, and traces.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content