This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Add to this the escalating costs of maintaining legacy systems, which often act as bottlenecks for scalability. The latter option had emerged as a compelling solution, offering the promise of enhanced agility, reduced operational costs, and seamless scalability. Scalability. Scalability. Cost forecasting. The results?
Incorporating AI into API and microservice architecture design for the Cloud can bring numerous benefits. Automated scaling : AI can monitor usage patterns and automatically scale microservices to meet varying demands, ensuring efficient resource utilization and cost-effectiveness.
Below we outline common approaches to distributed tracing, the challenges these methods pose and how OverOps can help deliver greater insights when troubleshooting across microservices. The accelerated adoption of microservices and increasingly distributed systems brings the promise of greater speed, scalability and flexibility.
In today’s DevOps landscape, microservices—the cloud-native approach to designing scalable, independently delivered services—allow teams to prioritize each […]. The post Hooked on Service Metrics appeared first on DevOps.com.
This thoughtful approach doesnt just address immediate hurdles; it builds the resilience and scalability needed for the future. Title Health encompasses various metrics and indicators that reflect how well a title is performing, in terms of discoverability and member engagement. Lets explore how this mindset drivesresults.
Each component in the previous diagram can be implemented as a microservice and is multi-tenant in nature, meaning it stores details related to each tenant, uniquely represented by a tenant_id. This in itself is a microservice, inspired the Orchestrator Saga pattern in microservices.
If you think of the shift to microservices and containers as an evolution rather than a revolution then you’ve reached the right place! Challenges such as: Managing the transition from a monolithic application to microservices. Dealing with polyglot programming across microservices. Logging across microservices.
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? The complexity of these operational demands underscored the urgent need for a scalable solution.
Microservices architecture has become popular over the last several years. Many organizations have seen significant improvements in critical metrics such as time to market, quality, and productivity as a result of implementing microservices. Recently, however, there has been a noticeable backlash against microservices.
Whether migrating from a monolithic architecture or building a distributed system from ground zero, there are many benefits to leverage from a microservices architecture–faster software deployment cycles, enhanced scalability, improved isolation of risk. The […].
If you’re in the technology field and you live on planet earth, you’ve probably heard the term “microservices” thrown around. The purpose of this article will be to give you a familiarity with microservices and what it (not “they”) does. Microservices. Microservices is not just a buzzword. Microservices are more secure.
At Imperva, we took advantage of Kafka Streams to build shared state microservices that serve as fault-tolerant, highly available single sources of truth about the state of objects in our system. Scalability, high availability, and fault tolerance. Benefits and challenges of moving from one microservice to a cluster.
Microservices architecture has become popular over the last several years. Many organizations have seen significant improvements in critical metrics such as time to market, quality, and productivity as a result of implementing microservices. Recently, however, there has been a noticeable backlash against microservices.
HCL Commerce Containers provide a modular and scalable approach to managing ecommerce applications. Scalability : Each Container can be scaled independently based on demand, ensuring the system can handle high traffic. It facilitates service discovery and load balancing within the microservices architecture.
Microservices architecture has become popular over the last several years. Many organizations have seen significant improvements in critical metrics such as time to market, quality, and productivity as a result of implementing microservices. Recently, however, there has been a noticeable backlash against microservices.
In particular, the VMAF metric lies at the core of improving the Netflix member’s streaming video quality. As VMAF evolves and is integrated with more encoding and streaming workflows within Netflix, we need scalable ways of fostering video quality innovations. We call this system Cosmos. VMAF and SSIM ).
Today a startup that’s built a scalable platform to manage that is announcing a big round of funding to continue its own scaling journey. The underlying large-scale metrics storage technology they built was eventually open sourced as M3.
Honeycomb’s SLOs allow teams to define, measure, and manage reliability based on real user impact, rather than relying on traditional system metrics like CPU or memory usage. Instead, they consolidate logs, metrics, and traces into a unified workflow. For OneFootball, this shift was transformative. Interested in learning more?
The interplay of distributed architectures, microservices, cloud-native environments, and massive data flows requires an increasingly critical approach : observability. Observability starts by collecting system telemetry data, such as logs, metrics, and traces.
The OpenTelemetry project was announced in 2019 as the coming together of two efforts that existed prior to that — OpenTracing and OpenCensus , with the goal of becoming a single open standard for extracting telemetry from distributed microservice-based applications.
With a shift towards microservices and highly modular architectures, the importance of application integration testing has never been greater. In this discussion, we take a different approach to dissect this subject by emphasizing the need for strategic planning, scalability considerations, and ROI metrics.
Monitoring and Logging : Kong offers detailed metrics and logs to help monitor API performance and identify issues. Microservice Architecture : Kong is designed to work with microservice architecture, providing a central point of control for API traffic and security.
A few years ago, we were paged by our SRE team due to our Metrics Alerting System falling behind — critical application health alerts reached engineers 45 minutes late! It became clear to us that we needed to solve the scalability problem with a fundamentally different approach. OK, Results?
The project involved decommissioning an extensive monolith Scala application into smaller microservices. The team used the Strangler Fig pattern to decommission the legacy system gradually in new Scala and modern microservices running in Kubernetes. JVM metrics. What can we do to identify the OOMKilled issue?
Why do companies use microservices with DevOps/cloud solutions, and what are the advantages and possible pitfalls of microservices integration? Microservices in a Nutshell. The sole build pipeline creates a bottleneck for releasing too big and too complex products, and here’s where microservices come into play.
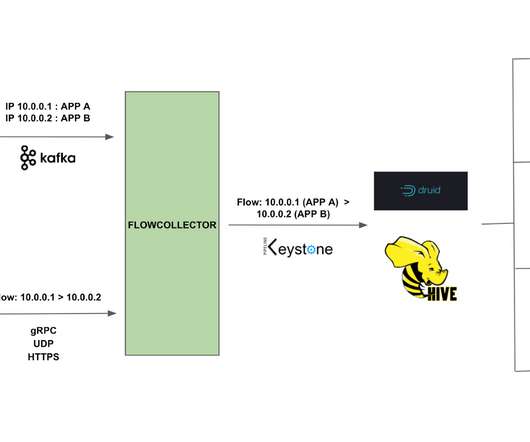
Flow Exporter The Flow Exporter is a sidecar that uses eBPF tracepoints to capture TCP flows at near real time on instances that power the Netflix microservices architecture. The Flow Exporter also publishes various operational metrics to Atlas. These metrics are visualized using Lumen , a self-service dashboarding infrastructure.
In the current digital environment, migration to the cloud has emerged as an essential tactic for companies aiming to boost scalability, enhance operational efficiency, and reinforce resilience. Our checklist guides you through each phase, helping you build a secure, scalable, and efficient cloud environment for long-term success.
Distributed Tracing: the missing context in troubleshooting services at scale Prior to Edgar, our engineers had to sift through a mountain of metadata and logs pulled from various Netflix microservices in order to understand a specific streaming failure experienced by any of our members. Trace Instrumentation: how will it impact our service?
Schema-based sharding gives an easy path for scaling out several important classes of applications that can divide their data across schemas: Multi-tenant SaaS applications Microservices that use the same database Vertical partitioning by groups of tables Each of these scenarios can now be enabled on Citus using regular CREATE SCHEMA commands.
Horizontal team members own the platforms to ensure their robustness, reliability, latency and scalability so engineers can be productive. They have full autonomy to decide whatever they want to do… to drive that goal, that mission and move that [business] metric in the way we expect.”
Kubernetes helps teams of all sizes optimize their microservices architecture by enabling seamless automated containerized app deployment, easy scalability, and efficient operations. In addition, as FireHydrant’s app grew over time, the team adopted more microservices, and it needed a way to orchestrate them.
If you choose not to use a cloud provider’s native services in order to remain agnostic, you lose many of the ‘better, cheaper, faster’ business case metrics,” says Holcombe. First, what services, such as microservices or serverless, are available from the cloud service providers to facilitate migration?
Java 11 introduced the Z Garbage Collector (ZGC), a new JDK garbage collector designed for low latency and high scalability. Metrics, logging, monitoring, and reliability. The Z Garbage Collector. Erik Österlund of the HotSpot Garbage Collection team at Oracle, is a contributor to the ZGC project. Functional Programming with Effects.
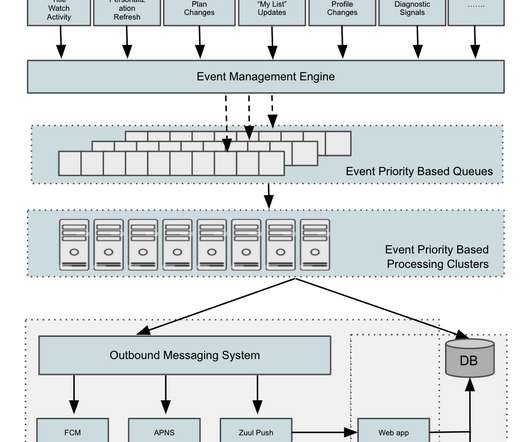
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. Furthermore, in addition to real-time alerting, we added trend analysis for important metrics to help catch longer term degradations.
Designing the microservices: Start with the business focus for each service. Domain-driven design (aka DDD) is the de facto architecture pattern for microservices. This helps break up the complex system into data-driven microservices that reflect the business problem. Go beyond the twelve-factor design for microservices.
We are thrilled to announce the general availability of the Cloudera AI Inference service, powered by NVIDIA NIM microservices , part of the NVIDIA AI Enterprise platform, to accelerate generative AI deployments for enterprises. This service supports a range of optimized AI models, enabling seamless and scalable AI inference.
In these open spaces, we discussed very interesting topics like “feature branches vs. continuous integration”, “ monoliths vs microservices “, “how to manage diversity in our workplace”, Also, we shared the disastrous experiences we have had in production. Microservices vs Monolithic architecture.
The backend for the streaming product utilizes a highly distributed microservices architecture; hence these migrations also happen at different points of the service call graph. The first phase involves validating functional correctness, scalability, and performance concerns and ensuring the new systems’ resilience before the migration.
We’re operating distributed microservice ecosystems on top of a deep stack of frameworks, abstractions and runtimes that are all running on other people’s servers (aka “the cloud”). This time, imagine that we are the on-call engineer for a large web app with a complex architecture consisting of hundreds of independent microservices.
Scalable and flexible. TheHive is a scalable incident response platform that you can use for case and alert management. It features dynamic dashboards for tracking metrics of cases, recording response progress, and automating response tasks. Scalable and flexible. OwlH is a scalable, network intrusion detection system.
Most successful organizations base their goals on improving some or all of the DORA or Accelerate metrics. DORA metrics are used by DevOps teams to measure their performance and find out whether they are “low performers” to “elite performers.” You want to maximize your deployment frequency while minimizing the other metrics.
Virtually all modern software and applications built today are distributed systems of some sort, says Sam Newman , director at Sam Newman & Associates and author of Building Microservices. Horizontal Scalability. Even a monolithic application talking to a database is a distributed system, he says, “just a very simple one.”.
He is a software engineer, consultant, and author of “Continuous Delivery”, “Modern Software Engineering,” “CD Pipelines,” and “ Software Architecture Metrics. “ Farley is synonymous with being at the forefront of modern software development practices.
For our federated architecture, we prioritized solving observability needs in a more scalable manner. debug why something isn’t working Our guiding metrics in this space are mean time to resolution (MTTR) and service level objectives and indicators (SLO/SLI). We prioritized three areas: Alerting ?—?report
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content