This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Meet Taktile , a new startup that is working on a machinelearning platform for financial services companies. This isn’t the first company that wants to leverage machinelearning for financial products. They could use that data to train new models and roll out machinelearning applications.
We’re living in a phenomenal moment for machinelearning (ML), what Sonali Sambhus , head of developer and ML platform at Square, describes as “the democratization of ML.” When it comes to recruiting for ML, hire experts when you can, but also look into how training can help you meet your talent needs. ML recruiting strategy.
Tecton.ai , the startup founded by three former Uber engineers who wanted to bring the machinelearning feature store idea to the masses, announced a $35 million Series B today, just seven months after announcing their $20 million Series A. “We help organizations put machinelearning into production.
One of the more tedious aspects of machinelearning is providing a set of labels to teach the machinelearning model what it needs to know. It also announced a new tool called Application Studio that provides a way to build common machinelearning applications using templates and predefined components.
Due to the success of this libary, Hugging Face quickly became the main repository for all things related to machinelearning models — not just natural language processing. Essentially, Hugging Face is building the GitHub of machinelearning. It’s a community-driven platform with a ton of repositories.
Adam Oliner, co-founder and CEO of Graft used to run machinelearning at Slack, where he helped build the company’s internal artificial intelligence infrastructure. These are essentially very large pre-trained models that encode a lot of semantic and structural knowledge about a domain of data.
Data scientists and AI engineers have so many variables to consider across the machinelearning (ML) lifecycle to prevent models from degrading over time. It guides users through training and deploying an informed chatbot, which can often take a lot of time and effort.
Called OpenBioML , the endeavor’s first projects will focus on machinelearning-based approaches to DNA sequencing, protein folding and computational biochemistry. Stability AI’s ethically questionable decisions to date aside, machinelearning in medicine is a minefield. Predicting protein structures.
Training a frontier model is highly compute-intensive, requiring a distributed system of hundreds, or thousands, of accelerated instances running for several weeks or months to complete a single job. For example, pre-training the Llama 3 70B model with 15 trillion training tokens took 6.5 During the training of Llama 3.1
Thats why were moving from Cloudera MachineLearning to Cloudera AI. Why AI Matters More Than ML Machinelearning (ML) is a crucial piece of the puzzle, but its just one piece. Renaming our platform Cloudera AI acknowledges that our customers arent just training modelstheyre embedding intelligence across their business.
Across diverse industries—including healthcare, finance, and marketing—organizations are now engaged in pre-training and fine-tuning these increasingly larger LLMs, which often boast billions of parameters and larger input sequence length. This approach reduces memory pressure and enables efficient training of large models.
At its re:Invent conference today, Amazon’s AWS cloud arm announced the launch of SageMaker HyperPod, a new purpose-built service for training and fine-tuning large language models (LLMs). SageMaker HyperPod is now generally available. All rights reserved.
Recent research shows that 67% of enterprises are using generative AI to create new content and data based on learned patterns; 50% are using predictive AI, which employs machinelearning (ML) algorithms to forecast future events; and 45% are using deep learning, a subset of ML that powers both generative and predictive models.
We are happy to share our learnings and what works — and what doesn’t. The whole idea is that with the apprenticeship program coupled with our 100 Experiments program , we can train a lot more local talent to enter the AI field — a different pathway from traditional academic AI training. And why that role?
Fine tuning involves another round of training for a specific model to help guide the output of LLMs to meet specific standards of an organization. Given some example data, LLMs can quickly learn new content that wasn’t available during the initial training of the base model. Build and test training and inference prompts.
But it’s important to understand that AI is an extremely broad field and to expect non-experts to be able to assist in machinelearning, computer vision, and ethical considerations simultaneously is just ridiculous.” Tkhir calls on organizations to invest in AI training.
Educate and train help desk analysts. Equip the team with the necessary training to work with AI tools. Ivanti’s service automation offerings have incorporated AI and machinelearning. This helps reduce manual effort and improves response times.” These technologies handle ticket classification, improving accuracy.
AI and machinelearning are poised to drive innovation across multiple sectors, particularly government, healthcare, and finance. AI and machinelearning evolution Lalchandani anticipates a significant evolution in AI and machinelearning by 2025, with these technologies becoming increasingly embedded across various sectors.
As Artificial Intelligence (AI)-powered cyber threats surge, INE Security , a global leader in cybersecurity training and certification, is launching a new initiative to help organizations rethink cybersecurity training and workforce development.
While LLMs are trained on large amounts of information, they have expanded the attack surface for businesses. From prompt injections to poisoning training data, these critical vulnerabilities are ripe for exploitation, potentially leading to increased security risks for businesses deploying GenAI.
To help address the problem, he says, companies are doing a lot of outsourcing, depending on vendors and their client engagement engineers, or sending their own people to training programs. In the Randstad survey, for example, 35% of people have been offered AI training up from just 13% in last years survey.
Both the tech and the skills are there: MachineLearning technology is by now easy to use and widely available. So then let me re-iterate: why, still, are teams having troubles launching MachineLearning models into production? No longer is MachineLearning development only about training a ML model.
Unfortunately, the blog post only focuses on train-serve skew. Feature stores solve more than just train-serve skew. This becomes more important when a company scales and runs more machinelearning models in production. In a naive setup features are (re-)computed each time you train a new model.
In these cases, the AI sometimes fabricated unrelated phrases, such as “Thank you for watching!” — likely due to its training on a large dataset of YouTube videos. Another machinelearning engineer reported hallucinations in about half of over 100 hours of transcriptions inspected.
Before LLMs and diffusion models, organizations had to invest a significant amount of time, effort, and resources into developing custom machine-learning models to solve difficult problems. In many cases, this eliminates the need for specialized teams, extensive data labeling, and complex machine-learning pipelines.
With those tools involved, users can build new AI models on relatively low-powered machines, saving heavy-duty units for the compute-intensive process of model training. Deploying AI Many modern AI systems are capable of leveraging machine-to-machine connections to automate data ingestion and initiate responsive activity.
The pressure is on for CIOs to deliver value from AI, but pressing ahead with AI implementations without the necessary workforce training in place is a recipe for falling short of their goals. For many IT leaders, being central to organization-wide training initiatives may be new territory. “At
The team opted to build out its platform on Databricks for analytics, machinelearning (ML), and AI, running it on both AWS and Azure. Gen AI agenda Beswick has an ambitious gen AI agenda but everything being developed and trained today is for internal use only to guard against hallucinations and data leakage.
Job titles like data engineer, machinelearning engineer, and AI product manager have supplanted traditional software developers near the top of the heap as companies rush to adopt AI and cybersecurity professionals remain in high demand. The job will evolve as most jobs have evolved.
With AI models demanding vast amounts of structured and unstructured data for training, data lakehouses offer a highly flexible approach that is ideally suited to support them at scale. Then there’s the data lakehouse—an analytics system that allows data to be processed, analyzed, and stored in both structured and unstructured forms.
The Austin, Texas-based startup has developed a platform that uses artificial intelligence and machinelearningtrained on ransomware to reverse the effects of a ransomware attack — making sure businesses’ operations are never actually impacted by an attack.
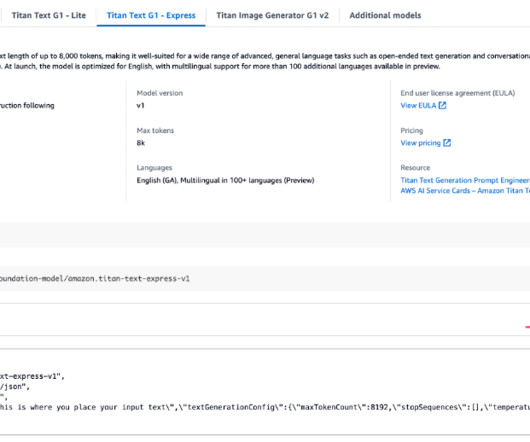
About the NVIDIA Nemotron model family At the forefront of the NVIDIA Nemotron model family is Nemotron-4, as stated by NVIDIA, it is a powerful multilingual large language model (LLM) trained on an impressive 8 trillion text tokens, specifically optimized for English, multilingual, and coding tasks. You can find him on LinkedIn.
These powerful models, trained on vast amounts of data, can generate human-like text, answer questions, and even engage in creative writing tasks. However, training and deploying such models from scratch is a complex and resource-intensive process, often requiring specialized expertise and significant computational resources.
If you’re not familiar with Dataiku, the platform lets you turn raw data into advanced analytics, run some data visualization tasks, create data-backed dashboards and trainmachinelearning models. In particular, Dataiku can be used by data scientists, but also business analysts and less technical people.
AI and MachineLearning will drive innovation across the government, healthcare, and banking/financial services sectors, strongly focusing on generative AI and ethical regulation. How do you foresee artificial intelligence and machinelearning evolving in the region in 2025?
Fed enough data, the conventional thinking goes, a machinelearning algorithm can predict just about anything — for example, which word will appear next in a sentence. Given that potential, it’s not surprising that enterprising investment firms have looked to leverage AI to inform their decision-making.
Ive spent more than 25 years working with machinelearning and automation technology, and agentic AI is clearly a difficult problem to solve. Its also possible to train agentic AI to recognize itself and determine that responses during a verification are likely coming from a computer.
The gap between emerging technological capabilities and workforce skills is widening, and traditional approaches such as hiring specialized professionals or offering occasional training are no longer sufficient as they often lack the scalability and adaptability needed for long-term success.
To regularly train models needed for use cases specific to their business, CIOs need to establish pipelines of AI-ready data, incorporating new methods for collecting, cleansing, and cataloguing enterprise information. Now with agentic AI, the need for quality data is growing faster than ever, giving more urgency to the existing trend.
The Kingdom has committed significant resources to developing a robust cybersecurity ecosystem, encompassing threat detection systems, incident response frameworks, and cutting-edge defense mechanisms powered by artificial intelligence and machinelearning.
We know that cybersecurity training is no longer optional for businesses – it is essential. Our mission is to provide accessible, effective, and affordable training to these businesses so they can close the gap, ultimately enhancing their defensive capabilities.”
The team opted to build out its platform on Databricks for analytics, machinelearning (ML), and AI, running it on both AWS and Azure. Gen AI agenda Beswick has an ambitious gen AI agenda but everything being developed and trained today is for internal use only to guard against hallucinations and data leakage.
Today, enterprises are in a similar phase of trying out and accepting machinelearning (ML) in their production environments, and one of the accelerating factors behind this change is MLOps. Similar to cloud-native startups, many startups today are ML native and offer differentiated products to their customers.
The company has post-trained its new Llama Nemotron family of reasoning models to improve multistep math, coding, reasoning, and complex decision-making. Post-training is a set of processes and techniques for refining and optimizing a machinelearning model after its initial training on a dataset.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content