This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For all the excitement about machinelearning (ML), there are serious impediments to its widespread adoption. In addition to newer innovations, the practice borrows from model risk management, traditional model diagnostics, and software testing. Not least is the broadening realization that ML models can fail.
Across diverse industries—including healthcare, finance, and marketing—organizations are now engaged in pre-training and fine-tuning these increasingly larger LLMs, which often boast billions of parameters and larger input sequence length. This approach reduces memory pressure and enables efficient training of large models.
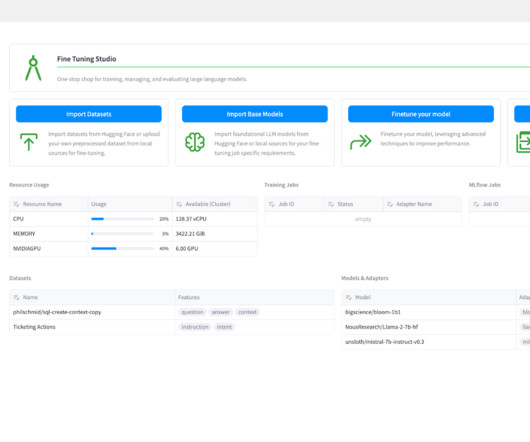
Fine tuning involves another round of training for a specific model to help guide the output of LLMs to meet specific standards of an organization. Given some example data, LLMs can quickly learn new content that wasn’t available during the initial training of the base model. Build and testtraining and inference prompts.
technology, machinelearning, hardware, software — and yes, lasers! Founded by a team whose backgrounds include physics, stem cell biology, and machinelearning, Cellino operates in the regenerative medicine industry. — could eventually democratize access to cell therapies.
Ive spent more than 25 years working with machinelearning and automation technology, and agentic AI is clearly a difficult problem to solve. One of the best is a penetration test that checks for ways someone could access a network. Could it work through complex, dynamic branch points, make autonomous decisions and act on them?
After months of crunching data, plotting distributions, and testing out various machinelearning algorithms you have finally proven to your stakeholders that your model can deliver business value. For the sake of argumentation, we will assume the machinelearning model is periodically trained on a finite set of historical data.
This a revolutionary new capability within Amazon Bedrock that serves as a centralized hub for discovering, testing, and implementing foundation models (FMs). Nemotron-4 15B, with its impressive 15-billion-parameter architecture trained on 8 trillion text tokens, brings powerful multilingual and coding capabilities to the Amazon Bedrock.
The pressure is on for CIOs to deliver value from AI, but pressing ahead with AI implementations without the necessary workforce training in place is a recipe for falling short of their goals. For many IT leaders, being central to organization-wide training initiatives may be new territory. “At
Delta Lake: Fueling insurance AI Centralizing data and creating a Delta Lakehouse architecture significantly enhances AI model training and performance, yielding more accurate insights and predictive capabilities. A critical consideration emerges regarding enterprise AI platform implementation.
Wetmur says Morgan Stanley has been using modern data science, AI, and machinelearning for years to analyze data and activity, pinpoint risks, and initiate mitigation, noting that teams at the firm have earned patents in this space. I am excited about the potential of generative AI, particularly in the security space, she says.
Fine-tuning is a powerful approach in natural language processing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. The TAT-QA dataset has been divided into train (28,832 rows), dev (3,632 rows), and test (3,572 rows).
Demystifying RAG and model customization RAG is a technique to enhance the capability of pre-trained models by allowing the model access to external domain-specific data sources. Unlike fine-tuning, in RAG, the model doesnt undergo any training and the model weights arent updated to learn the domain knowledge.
Tuning model architecture requires technical expertise, training and fine-tuning parameters, and managing distributed training infrastructure, among others. However, customizing DeepSeek models effectively while managing computational resources remains a significant challenge.
The company has post-trained its new Llama Nemotron family of reasoning models to improve multistep math, coding, reasoning, and complex decision-making. Post-training is a set of processes and techniques for refining and optimizing a machinelearning model after its initial training on a dataset.
Over the past several months, we drove several improvements in intelligent prompt routing based on customer feedback and extensive internal testing. In this blog post, we detail various highlights from our internal testing, how you can get started, and point out some caveats and best practices. Lets dive in! v1, Haiku 3.5, Sonnet 3.5
DeepSeek-R1 , developed by AI startup DeepSeek AI , is an advanced large language model (LLM) distinguished by its innovative, multi-stage training process. Instead of relying solely on traditional pre-training and fine-tuning, DeepSeek-R1 integrates reinforcement learning to achieve more refined outputs.
What was once a preparatory task for training AI is now a core part of a continuous feedback and improvement cycle. Training compact, domain-specialized models that outperform general-purpose LLMs in areas like healthcare, legal, finance, and beyond. Todays annotation tools are no longer just for labeling datasets.
But that’s exactly the kind of data you want to include when training an AI to give photography tips. Conversely, some of the other inappropriate advice found in Google searches might have been avoided if the origin of content from obviously satirical sites had been retained in the training set.
You can try these models with SageMaker JumpStart, a machinelearning (ML) hub that provides access to algorithms and models that can be deployed with one click for running inference. Both pre-trained base and instruction-tuned checkpoints are available under the Apache 2.0
Automation: Maximizing tools and practices in the delivery environments like IAC, CICD, DevOps, SecOps and Test Automation aligned with the technology and cloud provider stacks and enable sustainable agile delivery. This requires close attention to the detail, auditing/testing, planning and designing upfront.
In 2013, I was fortunate to get into artificial intelligence (more specifically, deep learning) six months before it blew up internationally. It started when I took a course on Coursera called “Machinelearning with neural networks” by Geoffrey Hinton. It was like being love struck.
Amazon Bedrock provides two primary methods for preparing your training data: uploading JSONL files to Amazon S3 or using historical invocation logs. Tool specification format requirements For agent function calling distillation, Amazon Bedrock requires that tool specifications be provided as part of your training data.
Today it was FireEye’s turn, snagging Respond Software , a company that helps customers investigate and understand security incidents, while reducing the need for highly trained (and scarce) security analysts. The acquisition gives them a quick influx of machinelearning-fueled software.
The use of synthetic data to train AI models is about to skyrocket, as organizations look to fill in gaps in their internal data, build specialized capabilities, and protect customer privacy, experts predict. Gartner, for example, projects that by 2028, 80% of data used by AIs will be synthetic, up from 20% in 2024.
Smart Snippet Model in Coveo The Coveo MachineLearning Smart Snippets model shows users direct answers to their questions on the search results page. Navigate to Recommendations : In the left-hand menu, click “models” under the “MachineLearning” section.
Kakkar and his IT teams are enlisting automation, machinelearning, and AI to facilitate the transformation, which will require significant innovation, especially at the edge. Kakkar’s litmus test for pursuing a project depends on whether it has a clear purpose, goal, and measurable objectives.
At the core of Union is Flyte , an open source tool for building production-grade workflow automation platforms with a focus on data, machinelearning and analytics stacks. But there was always friction between the software engineers and machinelearning specialists. ” Image Credits: Union.ai
The generative AI playground is a UI provided to tenants where they can run their one-time experiments, chat with several FMs, and manually test capabilities such as guardrails or model evaluation for exploration purposes. This in itself is a microservice, inspired the Orchestrator Saga pattern in microservices.
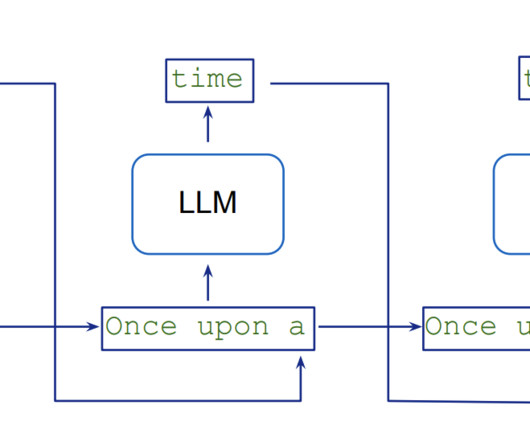
Trained on broad, generic datasets spanning a wide range of topics and domains, LLMs use their parametric knowledge to perform increasingly complex and versatile tasks across multiple business use cases. This blog post is co-written with Moran beladev, Manos Stergiadis, and Ilya Gusev from Booking.com. times on the same dataset.
Amazon SageMaker Canvas is a no-code machinelearning (ML) service that empowers business analysts and domain experts to build, train, and deploy ML models without writing a single line of code. You can review the model status and test the model on the Predict tab.
However, any customer-facing genAI apps need to be extensively and continuously tested and trained to ensure accuracy and a high-quality experience. Creating a superior customer experience: Organizations can supercharge the customer experience with genAI analysis of customer feedback, personalized chatbots, and tailored engagement.
I don’t have any experience working with AI and machinelearning (ML). We also read Grokking Deep Learning in the book club at work. Seeing a neural network that starts with random weights and, after training, is able to make good predictions is almost magical. These systems require labeled images for training.
“As a developer, you want to test an idea or build a new feature, and it can take weeks to get access to the data you need. The first product is an open source, synthetic machinelearning library for developers that strips out personally identifiable information. to train AI with synthetic data.
We need to train the organization to leverage AI to solve business problems, not just to create something new. Navigating the AI and machinelearning journey will become an even bigger focus for IT leaders over the next year, according to three quarters of IT leader respondents. Direction is being set by the executive suite.
The Education and Training Quality Authority (BQA) plays a critical role in improving the quality of education and training services in the Kingdom Bahrain. BQA oversees a comprehensive quality assurance process, which includes setting performance standards and conducting objective reviews of education and training institutions.
Refer to Supported models and Regions for fine-tuning and continued pre-training for updates on Regional availability and quotas. The required training dataset (and optional validation dataset) prepared and stored in Amazon Simple Storage Service (Amazon S3). As of writing this post, Meta Llama 3.2
And 20% of IT leaders say machinelearning/artificial intelligence will drive the most IT investment. Insights gained from analytics and actions driven by machinelearning algorithms can give organizations a competitive advantage, but mistakes can be costly in terms of reputation, revenue, or even lives.
Protect AI claims to be one of the few security companies focused entirely on developing tools to defend AI systems and machinelearning models from exploits. “We have researched and uncovered unique exploits and provide tools to reduce risk inherent in [machinelearning] pipelines.”
In our tests, we’ve seen substantial improvements in scaling times for generative AI model endpoints across various frameworks. AI and ML engineers can now move from model training to production deployment with unprecedented speed, reducing time-to-market for new AI features and improvements. gpu-py311-cu124-ubuntu22.04-sagemaker",
As companies increasingly move to take advantage of machinelearning to run their business more efficiently, the fact is that it takes an abundance of energy to build, test and run models in production. an energy-efficient solution for customers to build machinelearning models using its solution.
“Ninety percent of the data is used as a training set, and 10% for algorithm validation and testing. According to the data-centric AI we attach great importance to the test sets to be sure that they contain the best possible representation of signals from our clients. When a human interprets an ECG, they see a curve.
Finding the right learning platform can be difficult, especially as companies look to upskill and reskill their talent to meet demand for certain technological capabilities, like data science, machinelearning and artificial intelligence roles.
“The idea is to create a fictional version of a real dataset that can be used safely for a variety of purposes including safeguarding confidential data, reducing bias and also improving machinelearning models,” he said. Programmatic synthetic data helps developers in many ways.
With offices in Tel Aviv and New York, Datagen “is creating a complete CV stack that will propel advancements in AI by simulating real world environments to rapidly trainmachinelearning models at a fraction of the cost,” Vitus said. ” Investors that had backed Datagen’s $18.5
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content