This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the quest to reach the full potential of artificial intelligence (AI) and machinelearning (ML), there’s no substitute for readily accessible, high-quality data. By partnering with industry leaders, businesses can acquire the resources needed for efficient data discovery, multi-environment management, and strong data protection.
Called OpenBioML , the endeavor’s first projects will focus on machinelearning-based approaches to DNA sequencing, protein folding and computational biochemistry. Stability AI’s ethically questionable decisions to date aside, machinelearning in medicine is a minefield. ” Generating DNA sequences.
Data architecture definition Data architecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). It includes data collection, refinement, storage, analysis, and delivery. Cloud storage. Cloud computing.
TRECIG, a cybersecurity and IT consulting firm, will spend more on IT in 2025 as it invests more in advanced technologies such as artificial intelligence, machinelearning, and cloud computing, says Roy Rucker Sr., Spending on advanced IT Some business and IT leaders say they also anticipate IT spending increases during 2025.
The ease of access, while empowering, can lead to usage patterns that inadvertently inflate costsespecially when organizations lack a clear strategy for tracking and managing resource consumption. They provide unparalleled flexibility, allowing organizations to scale resources up or down based on real-time demands.
The ease of access, while empowering, can lead to usage patterns that inadvertently inflate costsespecially when organizations lack a clear strategy for tracking and managing resource consumption. They provide unparalleled flexibility, allowing organizations to scale resources up or down based on real-time demands.
Azure Key Vault Secrets offers a centralized and secure storage alternative for API keys, passwords, certificates, and other sensitive statistics. Azure Key Vault is a cloud service that provides secure storage and access to confidential information such as passwords, API keys, and connection strings. What is Azure Key Vault Secret?
With the advent of generative AI and machinelearning, new opportunities for enhancement became available for different industries and processes. It doesn’t retain audio or output text, and users have control over data storage with encryption in transit and at rest. This can lead to more personalized and effective care.
This approach consumed considerable time and resources and delayed deriving actionable insights from data. Consolidating data and improving accessibility through tenanted access controls can typically deliver a 25-30% reduction in data storage expenses while driving more informed decisions.
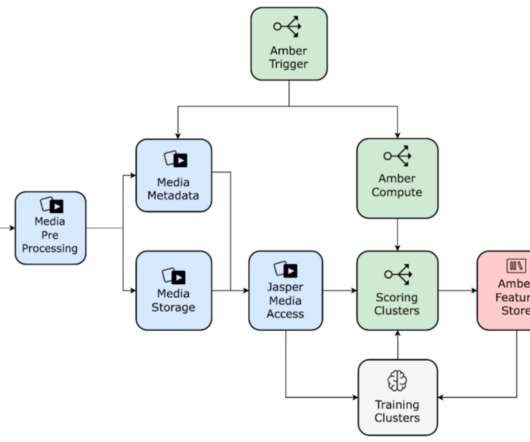
We have been leveraging machinelearning (ML) models to personalize artwork and to help our creatives create promotional content efficiently. Media Feature Storage: Amber Storage Media feature computation tends to be expensive and time-consuming. Why should members care about any particular show that we recommend?
Similarly, organizations are fine-tuning generative AI models for domains such as finance, sales, marketing, travel, IT, human resources (HR), procurement, healthcare and life sciences, and customer service. These models are tailored to perform specialized tasks within specific domains or micro-domains.
data center spending increase, covering servers, external storage, and network equipment, in 2024. The shortage is exacerbated because AI and machinelearning workloads will require modern hardware. Many data center operators appear to be thinking the same way, with Gartner projecting a 24.1%
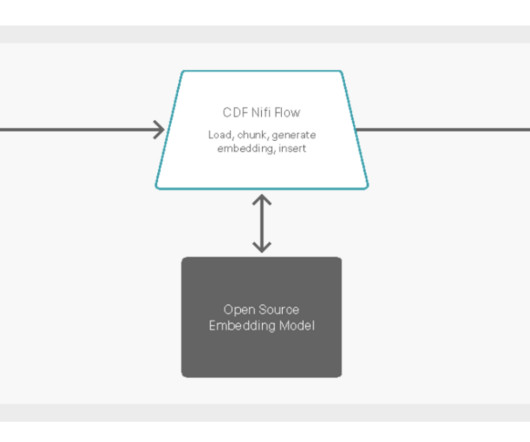
Depending on the use case and data isolation requirements, tenants can have a pooled knowledge base or a siloed one and implement item-level isolation or resource level isolation for the data respectively. Take Retrieval Augmented Generation (RAG) as an example. It’s serverless so you don’t have to manage the infrastructure.
Exclusive to Amazon Bedrock, the Amazon Titan family of models incorporates 25 years of experience innovating with AI and machinelearning at Amazon. Vector databases often use specialized vector search engines, such as nmslib or faiss , which are optimized for efficient storage, retrieval, and similarity calculation of vectors.
Flexible logging –You can use this solution to store logs either locally or in Amazon Simple Storage Service (Amazon S3) using Amazon Data Firehose, enabling integration with existing monitoring infrastructure. She leads machinelearning projects in various domains such as computer vision, natural language processing, and generative AI.
However, customizing DeepSeek models effectively while managing computational resources remains a significant challenge. The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling.
70B-Instruct ), offer different trade-offs between performance and resource requirements. We focus on importing the variants currently supported DeepSeek-R1-Distill-Llama-8B and DeepSeek-R1-Distill-Llama-70B, which offer an optimal balance between performance and resource efficiency. An S3 bucket prepared to store the custom model.
Manually managing such complexity can often be counter-productive and take away valuable resources from your businesses AI development. Shared Volume: FSx for Lustre is used as the shared storage volume across nodes to maximize data throughput. Its mounted at /fsx on the head and compute nodes. The Neuron 2.20 architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
The academic community expects data to be close to its high-performance compute resources, so they struggle with these egress fees pretty regularly, he says. Secure storage, together with data transformation, monitoring, auditing, and a compliance layer, increase the complexity of the system. Adding vaults is needed to secure secrets.
As more enterprises migrate to cloud-based architectures, they are also taking on more applications (because they can) and, as a result of that, more complex workloads and storage needs. Machinelearning and other artificial intelligence applications add even more complexity.
The solution also uses Amazon Cognito user pools and identity pools for managing authentication and authorization of users, Amazon API Gateway REST APIs, AWS Lambda functions, and an Amazon Simple Storage Service (Amazon S3) bucket. The summary is stored inside an S3 bucket, which can be emptied using the extension’s Clean Up feature.
Amazon SageMaker Canvas is a no-code machinelearning (ML) service that empowers business analysts and domain experts to build, train, and deploy ML models without writing a single line of code. Clean up We recommend deleting any potentially unused resources to avoid incurring unexpected costs.
Utilizing Pinecone for vector data storage over an in-house open-source vector store can be a prudent choice for organizations. Conversely, self-managed solutions may demand significant time and resources to maintain and optimize, making Pinecone a more efficient and reliable choice.
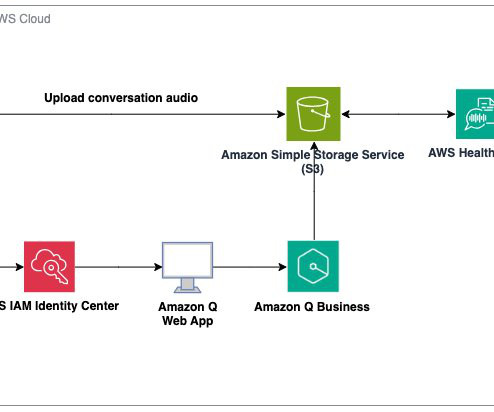
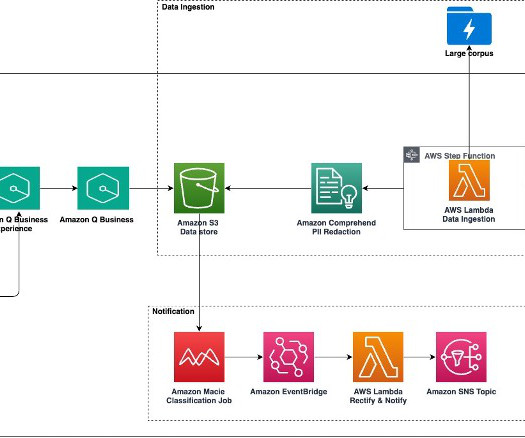
The Amazon Q Business pre-built connectors like Amazon Simple Storage Service (Amazon S3), document retrievers, and upload capabilities streamlined data ingestion and processing, enabling the team to provide swift, accurate responses to both basic and advanced customer queries. Full Macie finding event: {. }
Designed with a serverless, cost-optimized architecture, the platform provisions SageMaker endpoints dynamically, providing efficient resource utilization while maintaining scalability. Multiple specialized Amazon Simple Storage Service Buckets (Amazon S3 Bucket) store different types of outputs.
based company, which claims to be the top-ranked supplier of renewable energy sales to corporations, turned to machinelearning to help forecast renewable asset output, while establishing an automation framework for streamlining the company’s operations in servicing the renewable energy market. To achieve that, the Arlington, Va.-based
Prior to AWS, Flora earned her Masters degree in Computer Science from the University of Minnesota, where she developed her expertise in machinelearning and artificial intelligence. She has a strong background in computer vision, machinelearning, and AI for healthcare. and Metas Llama 3.1
First, it can lead to lower costs to convergence, allowing for more efficient use of resources during the training process. The training data, securely stored in Amazon Simple Storage Service (Amazon S3), is copied to the cluster. To learn more about cleaning up your resources provisioned, check out Clean up.
Core challenges for sovereign AI Resource constraints Developing and maintaining sovereign AI systems requires significant investments in infrastructure, including hardware (e.g., Many countries face challenges in acquiring or developing the necessary resources, particularly hardware and energy to support AI capabilities.
In many companies, data is spread across different storage locations and platforms, thus, ensuring effective connections and governance is crucial. These digital workers will fill roles historically reserved for humans, providing capabilities like resolving support tickets, assisting in human resources, and automating complex workflows.
Addressing these challenges by integrating advanced Artificial Intelligence (AI) and MachineLearning (ML) technologies into data protection solutions can enhance data backup and recovery, providing real-world applications and highlighting the benefits of these technologies.
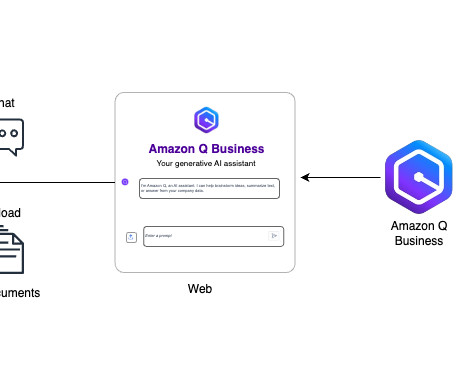
But these resources tend to become siloed over time and inaccessible across teams, resulting in reduced knowledge, duplication of work, and reduced productivity. Clean Up After trying the Amazon Q Business web experience, remember to remove any resources you created to avoid unnecessary charges. Sona Rajamani is a Sr.
11B-Vision-Instruct ) or Simple Storage Service (S3) URI containing the model files. During non-peak hours, the endpoint can scale down to zero , optimizing resource usage and cost efficiency. meta-llama/Llama-3.2-11B-Vision-Instruct For a complete list of runtime configurations, please refer to text-generation-launcher arguments.
It often requires managing multiple machinelearning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats. The result is expensive, brittle workflows that demand constant maintenance and engineering resources.
But implementing and maintaining the data pipelines necessary to keep AI systems from drifting to inaccuracy can require substantial technical resources. “We [founded Union] because we believe that machinelearning and data workflows are fundamentally different from software deployments. ” Taking Flyte.
Such a virtual assistant should support users across various business functions, such as finance, legal, human resources, and operations. Lambda uses 1024 MB of memory and 512 MB of ephemeral storage, with API Gateway configured as a REST API. He specializes in machinelearning and is a generative AI lead for NAMER startups team.
The flexible, scalable nature of AWS services makes it straightforward to continually refine the platform through improvements to the machinelearning models and addition of new features. Dr. Nicki Susman is a Senior MachineLearning Engineer and the Technical Lead of the Principal AI Enablement team.
Time-consuming and resource-intensive The process required dedicating significant time and resources to review the submissions manually and follow up with institutions to request additional information if needed to rectify the submissions, resulting in slowing down the overall review process.
Example 1: Enforce the use of a specific guardrail and its numeric version The following example illustrates the enforcement of exampleguardrail and its numeric version 1 during model inference: { "Version": "2012-10-17", "Statement": [ { "Sid": "InvokeFoundationModelStatement1", "Effect": "Allow", "Action": [ "bedrock:InvokeModel", "bedrock:InvokeModelWithResponseStream" (..)
Shankar notes that AI can also equip IT teams with the data-driven insights needed to optimize resource allocation, prioritize upgrades, and plan for the future. Many AI systems use machinelearning, constantly learning and adapting to become even more effective over time,” he says.
This architecture workflow includes the following steps: A user uploads files to be processed to an Amazon Simple Storage Service (Amazon S3) bucket br-batch-inference-{Account_Id}-{AWS-Region} in the to-process folder. Amazon S3 invokes the {stack_name}-create-batch-queue-{AWS-Region} Lambda function. Choose Submit.
This solution offers the following key benefits: Rapid analysis and resource optimization What previously took days of manual review can now be accomplished in minutes, allowing for faster iteration and improvement of architectures. Follow these steps to remove all associated resources: Navigate to the directory containing your AWS CDK code.
The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket. After you deploy the solution, you can verify the created resources on the Amazon Bedrock console. Ingestion flow The ingestion flow prepares and stores the necessary data for the AI agent to access.
Part of the problem is that data-intensive workloads require substantial resources, and that adding the necessary compute and storage infrastructure is often expensive. As a result, organizations are looking for solutions that free CPUs from computationally intensive storage tasks.” Marvell has its Octeon technology.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content