This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
From data masking technologies that ensure unparalleled privacy to cloud-native innovations driving scalability, these trends highlight how enterprises can balance innovation with accountability. With machinelearning, these processes can be refined over time and anomalies can be predicted before they arise.
To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. Review the stack details and select I acknowledge that AWS CloudFormation might create AWS IAM resources , as shown in the following screenshot. Choose Submit.
Data architecture definition Data architecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). AI and machinelearning models. Scalable data pipelines. Application programming interfaces.
TRECIG, a cybersecurity and IT consulting firm, will spend more on IT in 2025 as it invests more in advanced technologies such as artificial intelligence, machinelearning, and cloud computing, says Roy Rucker Sr., We’re consistently evaluating our technology needs to ensure our platforms are efficient, secure, and scalable,” he says.
to identify opportunities for optimizations that reduce cost, improve efficiency and ensure scalability. Software architecture: Designing applications and services that integrate seamlessly with other systems, ensuring they are scalable, maintainable and secure and leveraging the established and emerging patterns, libraries and languages.
Without a scalable approach to controlling costs, organizations risk unbudgeted usage and cost overruns. This scalable, programmatic approach eliminates inefficient manual processes, reduces the risk of excess spending, and ensures that critical applications receive priority.
This new feature brings several key benefits for generative AI inference workloads: dramatically faster scaling to handle traffic spikes, improved resource utilization on GPU instances, and potential cost savings through more efficient scaling and reduced idle time during scale-up events.
Traditionally, building frontend and backend applications has required knowledge of web development frameworks and infrastructure management, which can be daunting for those with expertise primarily in data science and machinelearning. The deployment process may take 5–10 minutes. See the README.md
The ease of access, while empowering, can lead to usage patterns that inadvertently inflate costsespecially when organizations lack a clear strategy for tracking and managing resource consumption. Scalability and Flexibility: The Double-Edged Sword of Pay-As-You-Go Models Pay-as-you-go pricing models are a game-changer for businesses.
The ease of access, while empowering, can lead to usage patterns that inadvertently inflate costsespecially when organizations lack a clear strategy for tracking and managing resource consumption. Scalability and Flexibility: The Double-Edged Sword of Pay-As-You-Go Models Pay-as-you-go pricing models are a game-changer for businesses.
This allows organizations to maximize resources and accelerate time to market. Many believe that responsible AI use will help achieve these goals, though they also recognize that the systems powering AI algorithms are resource-intensive themselves. AI applications rely heavily on secure data, models, and infrastructure.
This approach consumed considerable time and resources and delayed deriving actionable insights from data. The ideal solution should be scalable and flexible, capable of evolving alongside your organization’s needs. Opt for platforms that can be deployed within a few months, with easily integrated AI and machinelearning capabilities.
Depending on the use case and data isolation requirements, tenants can have a pooled knowledge base or a siloed one and implement item-level isolation or resource level isolation for the data respectively. Take Retrieval Augmented Generation (RAG) as an example. It’s serverless so you don’t have to manage the infrastructure.
Maintaining legacy systems can consume a substantial share of IT budgets up to 70% according to some analyses diverting resources that could otherwise be invested in innovation and digital transformation. The financial and security implications are significant. In my view, the issue goes beyond merely being a legacy system.
Azure Key Vault Secrets integration with Azure Synapse Analytics enhances protection by securely storing and dealing with connection strings and credentials, permitting Azure Synapse to enter external data resources without exposing sensitive statistics. Resource Group: Select an existing resource group or create a new one for your workspace.
As a result, the following data resources will become more and more important: Data contracts Data catalogs Data quality and observability tools Semantic layers One of the most important questions will therefore be: How can we make data optimally accessible to non-technical users within organizations?
Although the implementation is straightforward, following best practices is crucial for the scalability, security, and maintainability of your observability infrastructure. You can follow the steps provided in the Deleting a stack on the AWS CloudFormation console documentation to delete the resources created for this solution.
there is an increasing need for scalable, reliable, and cost-effective solutions to deploy and serve these models. This configuration allows for the efficient utilization of the hardware resources while enabling multiple concurrent inference requests. You can test the inference server by making a request from your local machine.
Whether processing invoices, updating customer records, or managing human resource (HR) documents, these workflows often require employees to manually transfer information between different systems a process thats time-consuming, error-prone, and difficult to scale. Follow the instructions in the provided GitHub repository.
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. This time efficiency translates to significant cost savings and optimized resource allocation in the review process.
As successful proof-of-concepts transition into production, organizations are increasingly in need of enterprise scalable solutions. Cost Optimization – Well-Architected guidelines assist in optimizing resource usage, using cost-saving services, and monitoring expenses, resulting in long-term viability of generative AI projects.
About the Authors Mengdie (Flora) Wang is a Data Scientist at AWS Generative AI Innovation Center, where she works with customers to architect and implement scalable Generative AI solutions that address their unique business challenges. She has a strong background in computer vision, machinelearning, and AI for healthcare.
For instructions, refer to Clean up Amazon SageMaker notebook instance resources. She helps AWS Enterprise customers grow by understanding their goals and challenges, and guiding them on how they can architect their applications in a cloud-native manner while making sure they are resilient and scalable.
It is a very versatile, platform independent and scalable language because of which it can be used across various platforms. It is frequently used in developing web applications, data science, machinelearning, quality assurance, cyber security and devops. It is highly scalable and easy to learn.
The flexible, scalable nature of AWS services makes it straightforward to continually refine the platform through improvements to the machinelearning models and addition of new features. All AWS services are high-performing, secure, scalable, and purpose-built.
In this post, we explore how to deploy distilled versions of DeepSeek-R1 with Amazon Bedrock Custom Model Import, making them accessible to organizations looking to use state-of-the-art AI capabilities within the secure and scalable AWS infrastructure at an effective cost. 8B ) and DeepSeek-R1-Distill-Llama-70B (from base model Llama-3.3-70B-Instruct
Unmanaged cloud resources, human error, misconfigurations and the increasing sophistication of cyber threats, including those from AI-powered applications, create vulnerabilities that can expose sensitive data and disrupt business operations.
The map functionality in Step Functions uses arrays to execute multiple tasks concurrently, significantly improving performance and scalability for workflows that involve repetitive operations. The results of each iteration are collected and made available for subsequent steps in the state machine. But there are limitations.
Such a virtual assistant should support users across various business functions, such as finance, legal, human resources, and operations. This hybrid approach combines the scalability and flexibility of semantic search with the precision and context-awareness of classifier LLMs. However, it also presents some trade-offs.
Core challenges for sovereign AI Resource constraints Developing and maintaining sovereign AI systems requires significant investments in infrastructure, including hardware (e.g., Many countries face challenges in acquiring or developing the necessary resources, particularly hardware and energy to support AI capabilities.
However, customizing DeepSeek models effectively while managing computational resources remains a significant challenge. The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling.
Designed with a serverless, cost-optimized architecture, the platform provisions SageMaker endpoints dynamically, providing efficient resource utilization while maintaining scalability. Multiple documents are processed in batches while endpoints are active, maximizing resource utilization.
However, Cloud Center of Excellence (CCoE) teams often can be perceived as bottlenecks to organizational transformation due to limited resources and overwhelming demand for their support. Limited scalability – As the volume of requests increased, the CCoE team couldn’t disseminate updated directives quickly enough.
Machinelearning and other artificial intelligence applications add even more complexity. Astera Labs , a fabless semiconductor company that builds connectivity solutions that help remove bottlenecks around high-bandwidth applications and help better allocate resources around enterprise data, has raised $50 million.
Instead, the system dynamically routes traffic across multiple Regions, maintaining optimal resource utilization and performance. The following screenshot shows an example manifest.yaml that defines the resources targeting the Sandbox OU. Prepare a manifest.yaml file that defines your policies. Deploy your custom SCPs to specific OUs.
Fast-forward to today and CoreWeave provides access to over a dozen SKUs of Nvidia GPUs in the cloud, including H100s, A100s, A40s and RTX A6000s, for use cases like AI and machinelearning, visual effects and rendering, batch processing and pixel streaming. Intrator says it has over 30 members.)
This scalability allows you to expand your business without needing a proportionally larger IT team.” Shankar notes that AI can also equip IT teams with the data-driven insights needed to optimize resource allocation, prioritize upgrades, and plan for the future. Easy access to constant improvement is another AI growth benefit.
The challenge: Scaling quality assessments EBSCOlearnings learning pathscomprising videos, book summaries, and articlesform the backbone of a multitude of educational and professional development programs. Scalability and robustness With EBSCOlearnings vast content library in mind, the team built scalability into the core of their solution.
Amazon SageMaker AI provides a managed way to deploy TGI-optimized models, offering deep integration with Hugging Faces inference stack for scalable and cost-efficient LLM deployment. During non-peak hours, the endpoint can scale down to zero , optimizing resource usage and cost efficiency. GenAI Data Scientist at AWS.
This marked the beginning of cloud computing's adolescence (with some early “terrible twos” no doubt) revolutionizing how businesses access and utilize computing resources. Cloud platforms offer dynamic and distributed resources that can rapidly scale, introducing new attack surfaces and security challenges.
These settings provide a solid foundation for generating high-quality images while efficiently utilizing your hardware resources, allowing for further adjustments based on specific requirements. She’s passionate about machinelearning technologies and environmental sustainability.
Trained on the Amazon SageMaker HyperPod , Dream Machine excels in creating consistent characters, smooth motion, and dynamic camera movements. To accelerate iteration and innovation in this field, sufficient computing resources and a scalable platform are essential.
As DPG Media grows, they need a more scalable way of capturing metadata that enhances the consumer experience on online video services and aids in understanding key content characteristics. Tom Lauwers is a machinelearning engineer on the video personalization team for DPG Media.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






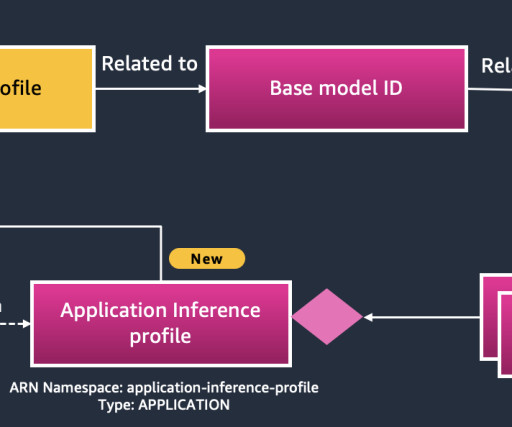

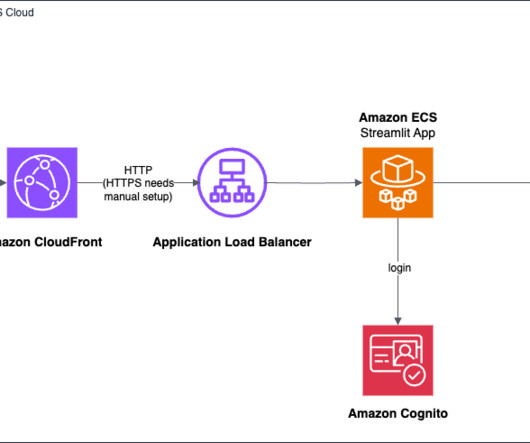














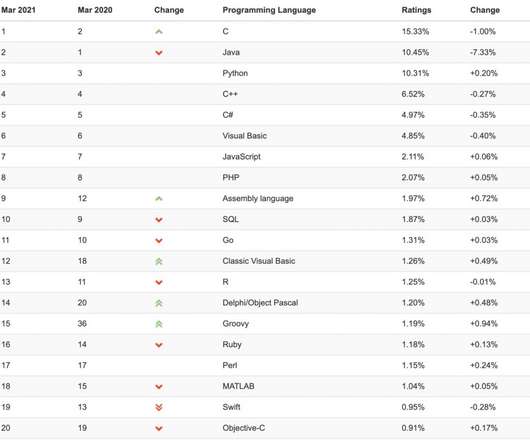





























Let's personalize your content