This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Thinking refers to an internal reasoning process using the first output tokens, allowing it to solve more complex tasks. Native Multi-Agent Architecture: Build scalable applications by composing specialized agents in a hierarchy. BigFrames provides a Pythonic DataFrame and machinelearning (ML) API powered by the BigQuery engine.
Refer to Supported Regions and models for batch inference for current supporting AWS Regions and models. To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. Select the created stack and choose Delete , as shown in the following screenshot.
Software-as-a-service (SaaS) applications with tenant tiering SaaS applications are often architected to provide different pricing and experiences to a spectrum of customer profiles, referred to as tiers. The user prompt is then routed to the LLM associated with the task category of the reference prompt that has the closest match.
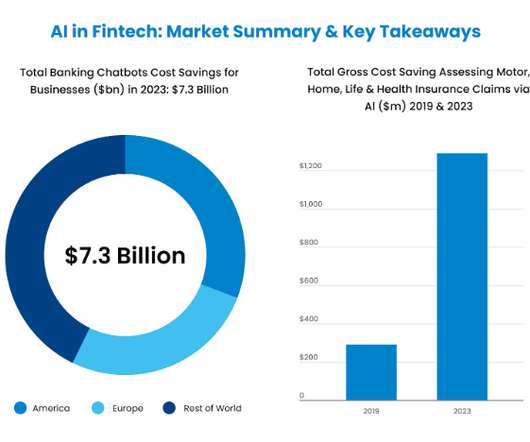
The banking landscape is constantly changing, and the application of machinelearning in banking is arguably still in its early stages. Machinelearning solutions are already rooted in the finance and banking industry. Machinelearning solutions are already rooted in the finance and banking industry.
Model customization refers to adapting a pre-trained language model to better fit specific tasks, domains, or datasets. Refer to Guidelines for preparing your data for Amazon Nova on best practices and example formats when preparing datasets for fine-tuning Amazon Nova models.
We then guide you through getting started with Container Caching, explaining its automatic enablement for SageMaker provided DLCs and how to reference cached versions. It addresses a critical bottleneck in the deployment process, empowering organizations to build more responsive, cost-effective, and scalable AI systems.
Shared components refer to the functionality and features shared by all tenants. Refer to Perform AI prompt-chaining with Amazon Bedrock for more details. Additionally, contextual grounding checks can help detect hallucinations in model responses based on a reference source and a user query.
For more information on generating JSON using the Converse API, refer to Generating JSON with the Amazon Bedrock Converse API. For more information on Mistral AI models available on Amazon Bedrock, refer to Mistral AI models now available on Amazon Bedrock. Additionally, Pixtral Large supports the Converse API and tool usage.
Powered by Precision AI™ – our proprietary AI system – this solution combines machinelearning, deep learning and generative AI to deliver advanced, real-time protection. Machinelearning analyzes historical data for accurate threat detection, while deep learning builds predictive models that detect security issues in real time.
Finally, use the generated images as reference material for 3D artists to create fully realized game environments. For instructions, refer to Clean up Amazon SageMaker notebook instance resources. Shes passionate about machinelearning technologies and environmental sustainability.
Data analysis and machinelearning techniques are great candidates to help secure large-scale streaming platforms. Although model-based anomaly detection approaches are more scalable and suitable for real-time analysis, they highly rely on the availability of (often labeled) context-specific data.
Give each secret a clear name, as youll use these names to reference them in Synapse. Add a Linked Service to the pipeline that references the Key Vault. When setting up a linked service for these sources, reference the names of the secrets stored in Key Vault instead of hard-coding the credentials.
Example: “Imagine you’re explaining how machinelearning works to a client with no technical background. Example: Ask a group of candidates to design an architecture for a scalable web application. Feedback and Reference checks Use references and peer feedback to validate interpersonal skills.
Observability refers to the ability to understand the internal state and behavior of a system by analyzing its outputs, logs, and metrics. For a detailed breakdown of the features and implementation specifics, refer to the comprehensive documentation in the GitHub repository.
Large Medium – This refers to the material or technique used in creating the artwork. This might involve incorporating additional data such as reference images or rough sketches as conditioning inputs alongside your text prompts. She’s passionate about machinelearning technologies and environmental sustainability.
The map functionality in Step Functions uses arrays to execute multiple tasks concurrently, significantly improving performance and scalability for workflows that involve repetitive operations. We're more than happy to provide further references upon request. after our text key to reference a node in this state’s JSON input.
With offices in Tel Aviv and New York, Datagen “is creating a complete CV stack that will propel advancements in AI by simulating real world environments to rapidly train machinelearning models at a fraction of the cost,” Vitus said. ” Investors that had backed Datagen’s $18.5
It is designed to handle the demanding computational and latency requirements of state-of-the-art transformer models, including Llama, Falcon, Mistral, Mixtral, and GPT variants for a full list of TGI supported models refer to supported models. For a complete list of runtime configurations, please refer to text-generation-launcher arguments.
The architectures modular design allows for scalability and flexibility, making it particularly effective for training LLMs that require distributed computing capabilities. To learn more details about these service features, refer to Generative AI foundation model training on Amazon SageMaker.
As successful proof-of-concepts transition into production, organizations are increasingly in need of enterprise scalable solutions. For details on all the fields and providing configuration of various vector stores supported by Knowledge Bases for Amazon Bedrock, refer to AWS::Bedrock::KnowledgeBase.
Readers will learn the key design decisions, benefits achieved, and lessons learned from Hearst’s innovative CCoE team. This solution can serve as a valuable reference for other organizations looking to scale their cloud governance and enable their CCoE teams to drive greater impact. About the Authors Steven Craig is a Sr.
The consulting giant reportedly paid around $50 million for Iguazio, a Tel Aviv-based company offering an MLOps platform for large-scale businesses — “MLOps” referring to a set of tools to deploy and maintain machinelearning models in production.
If you don’t have an AWS account, refer to How do I create and activate a new Amazon Web Services account? If you don’t have an existing knowledge base, refer to Create an Amazon Bedrock knowledge base. Performance optimization The serverless architecture used in this post provides a scalable solution out of the box.
From human genome mapping to Big Data Analytics, Artificial Intelligence (AI),MachineLearning, Blockchain, Mobile digital Platforms (Digital Streets, towns and villages),Social Networks and Business, Virtual reality and so much more. What is MachineLearning? MachineLearning delivers on this need.
As DPG Media grows, they need a more scalable way of capturing metadata that enhances the consumer experience on online video services and aids in understanding key content characteristics. To evaluate the metadata quality, the team used reference-free LLM metrics, inspired by LangSmith.
This challenge is further compounded by concerns over scalability and cost-effectiveness. You can run vLLM inference containers using Amazon SageMaker , as demonstrated in Efficient and cost-effective multi-tenant LoRA serving with Amazon SageMaker in the AWS MachineLearning Blog. vLLM also has limited quantization support.
Governance in the context of generative AI refers to the frameworks, policies, and processes that streamline the responsible development, deployment, and use of these technologies. For a comprehensive read about vector store and embeddings, you can refer to The role of vector databases in generative AI applications.
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. This scalability allows for more frequent and comprehensive reviews.
Machinelearning is now being used to solve many real-time problems. This table can be massively scaled to any use-case and this is why HBase is superior in this application as it’s a distributed, scalable, big data store. Make sure you read Part 1 and Part 2 before reading this installment. Background / Overview.
Sovereign AI refers to a national or regional effort to develop and control artificial intelligence (AI) systems, independent of the large non-EU foreign private tech platforms that currently dominate the field. Talent shortages AI development requires specialized knowledge in machinelearning, data science, and engineering.
Trained on the Amazon SageMaker HyperPod , Dream Machine excels in creating consistent characters, smooth motion, and dynamic camera movements. To accelerate iteration and innovation in this field, sufficient computing resources and a scalable platform are essential. accelerate launch train_stage_1.py py --config configs/train/stage1.yaml
It often requires managing multiple machinelearning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats. With Amazon Bedrock Data Automation, enterprises can accelerate AI adoption and develop solutions that are secure, scalable, and responsible.
Raj specializes in MachineLearning with applications in Generative AI, Natural Language Processing, Intelligent Document Processing, and MLOps. He is passionate about building scalable software solutions that solve customer problems. Krishna Gourishetti is a Senior Software Engineer for the Bedrock Agents team in AWS.
Machinelearning and other artificial intelligence applications add even more complexity. “With a step-function increase in folks working/studying from home and relying on cloud-based SaaS/PaaS applications, the deployment of scalable hardware infrastructure has accelerated,” Gajendra said in an email to TechCrunch.
While multi-cloud generally refers to the use of multiple cloud providers, hybrid encompasses both cloud and on-premises integrations, as well as multi-cloud setups. The scalable cloud infrastructure optimized costs, reduced customer churn, and enhanced marketing efficiency through improved customer segmentation and retention models.
The Asure team was manually analyzing thousands of call transcripts to uncover themes and trends, a process that lacked scalability. Staying ahead in this competitive landscape demands agile, scalable, and intelligent solutions that can adapt to changing demands. Architecture The following diagram illustrates the solution architecture.
Asaf has more than six years of both academic and industry experience in applying state-of-the-art and novel machinelearning methods to the domain of networking and cybersecurity. Daniel Pienica is a Data Scientist at Cato Networks with a strong passion for large language models (LLMs) and machinelearning (ML).
The commissioning of a series or film, which we refer to as a title , is a creative decision. In this post we explore how machinelearning and statistical modeling can aid creative decision makers in tackling these questions at a global scale. Our job is to support them. box office, Nielsen ratings).
DARPA also funded Verma’s research into in-memory computing for machinelearning computations — “in-memory,” here, referring to running calculations in RAM to reduce the latency introduced by storage devices. sets of AI algorithms) while remaining scalable.
In this post, we explore how to deploy distilled versions of DeepSeek-R1 with Amazon Bedrock Custom Model Import, making them accessible to organizations looking to use state-of-the-art AI capabilities within the secure and scalable AWS infrastructure at an effective cost. For more information, refer to the Amazon Bedrock User Guide.
is helping enterprise customers design and manage agentic workflows in a secure and scalable manner. FloTorch offers an open source version for customers with scalable experimentation with different chunking, embedding, retrieval, and inference strategies. About FloTorch FloTorch.ai You can connect with Prasanna on LinkedIn.
“We’re engineering the AI platform to help overcome this access barrier … [by] delivering a game-changing, user-friendly and scalable technology with superior performance and efficiency at a fraction of the cost of existing players to accelerate computing vision and natural language processing at the edge.”
Refer to the following considerations related to AWS Control Tower upgrades from 2.x As AI and machinelearning capabilities continue to evolve, finding the right balance between security controls and innovation enablement will remain a key challenge for organizations. If youre using a version less than 3.x
there is an increasing need for scalable, reliable, and cost-effective solutions to deploy and serve these models. For more information on how to view and increase your quotas, refer to Amazon EC2 service quotas. For production use, make sure that load balancing and scalability considerations are addressed appropriately.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content