This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Aquarium , a startup from two former Cruise employees, wants to help companies refine their machinelearning model data more easily and move the models into production faster. investment to build intelligent machinelearning labeling platform. Today the company announced a $2.6 Aquarium aims to solve this issue.
Data scientists and AI engineers have so many variables to consider across the machinelearning (ML) lifecycle to prevent models from degrading over time. RAG is an increasingly popular approach for improving LLM inferences, and the RAG with Knowledge Graph AMP takes this further by empowering users to maximize RAG system performance.
Training a frontier model is highly compute-intensive, requiring a distributed system of hundreds, or thousands, of accelerated instances running for several weeks or months to complete a single job. For example, pre-training the Llama 3 70B model with 15 trillion training tokens took 6.5 During the training of Llama 3.1
Called OpenBioML , the endeavor’s first projects will focus on machinelearning-based approaches to DNA sequencing, protein folding and computational biochemistry. Stability AI’s ethically questionable decisions to date aside, machinelearning in medicine is a minefield. Predicting protein structures.
Across diverse industries—including healthcare, finance, and marketing—organizations are now engaged in pre-training and fine-tuning these increasingly larger LLMs, which often boast billions of parameters and larger input sequence length. This approach reduces memory pressure and enables efficient training of large models.
Several LLMs are publicly available through APIs from OpenAI , Anthropic , AWS , and others, which give developers instant access to industry-leading models that are capable of performing most generalized tasks. Given some example data, LLMs can quickly learn new content that wasn’t available during the initial training of the base model.
We are happy to share our learnings and what works — and what doesn’t. The whole idea is that with the apprenticeship program coupled with our 100 Experiments program , we can train a lot more local talent to enter the AI field — a different pathway from traditional academic AI training. And why that role?
Once the province of the data warehouse team, data management has increasingly become a C-suite priority, with data quality seen as key for both customer experience and business performance. But that’s exactly the kind of data you want to include when training an AI to give photography tips.
The Israel-based company announced today it has closed $30 million in a Series B round to help protect trains and metros. Cylus enables maximum interoperability (train-track coupling) while protecting stationary and moving systems in trains, Levintal continued. The latest capital brings its total funding to over $57 million.
Before LLMs and diffusion models, organizations had to invest a significant amount of time, effort, and resources into developing custom machine-learning models to solve difficult problems. In many cases, this eliminates the need for specialized teams, extensive data labeling, and complex machine-learning pipelines.
The reasons include higher than expected costs, but also performance and latency issues; security, data privacy, and compliance concerns; and regional digital sovereignty regulations that affect where data can be located, transported, and processed. That said, 2025 is not just about repatriation. Judes Research Hospital St.
The gap between emerging technological capabilities and workforce skills is widening, and traditional approaches such as hiring specialized professionals or offering occasional training are no longer sufficient as they often lack the scalability and adaptability needed for long-term success.
The company has post-trained its new Llama Nemotron family of reasoning models to improve multistep math, coding, reasoning, and complex decision-making. Post-training is a set of processes and techniques for refining and optimizing a machinelearning model after its initial training on a dataset.
Unfortunately, the blog post only focuses on train-serve skew. Feature stores solve more than just train-serve skew. This becomes more important when a company scales and runs more machinelearning models in production. In a naive setup features are (re-)computed each time you train a new model.
Roughly a year ago, we wrote “ What machinelearning means for software development.” Karpathy suggests something radically different: with machinelearning, we can stop thinking of programming as writing a step of instructions in a programming language like C or Java or Python. Instead, we can program by example.
At its core, an epoch represents one complete pass over the entire training dataseta cycle in which our model learns from every available example. Conversely, too many epochs can lead to overfitting, where the model becomes so tailored to the training data that it struggles to generalize to new, unseen data.
Scalable infrastructure – Bedrock Marketplace offers configurable scalability through managed endpoints, allowing organizations to select their desired number of instances, choose appropriate instance types, define custom auto scaling policies that dynamically adjust to workload demands, and optimize costs while maintaining performance.
Fed enough data, the conventional thinking goes, a machinelearning algorithm can predict just about anything — for example, which word will appear next in a sentence. Given that potential, it’s not surprising that enterprising investment firms have looked to leverage AI to inform their decision-making.
Today, enterprises are in a similar phase of trying out and accepting machinelearning (ML) in their production environments, and one of the accelerating factors behind this change is MLOps. Similar to cloud-native startups, many startups today are ML native and offer differentiated products to their customers.
A 2020 IDC survey found that a shortage of data to train AI and low-quality data remain major barriers to implementing it, along with data security, governance, performance and latency issues. “The main challenge in building or adopting infrastructure for machinelearning is that the field moves incredibly quickly.
AI models not only take time to build and train, but also to deploy in an organization’s workflow. That’s where MLOps (machinelearning operations) companies come in, helping clients scale their AI technology. Enterprise companies find MLOps critical for reliability and performance.
However, today’s startups need to reconsider the MVP model as artificial intelligence (AI) and machinelearning (ML) become ubiquitous in tech products and the market grows increasingly conscious of the ethical implications of AI augmenting or replacing humans in the decision-making process. These algorithms have already been trained.
Fine-tuning is a powerful approach in natural language processing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. This process involves updating the model’s weights to improve its performance on targeted applications. Sonnet across various tasks.
In this post, we demonstrate how to effectively perform model customization and RAG with Amazon Nova models as a baseline. Demystifying RAG and model customization RAG is a technique to enhance the capability of pre-trained models by allowing the model access to external domain-specific data sources.
Wetmur says Morgan Stanley has been using modern data science, AI, and machinelearning for years to analyze data and activity, pinpoint risks, and initiate mitigation, noting that teams at the firm have earned patents in this space. I am excited about the potential of generative AI, particularly in the security space, she says.
Training large language models (LLMs) models has become a significant expense for businesses. However, companies are discovering that performing full fine tuning for these models with their data isnt cost effective. In addition to cost, performing fine tuning for LLMs at scale presents significant technical challenges.
But you can stay tolerably up to date on the most interesting developments with this column, which collects AI and machinelearning advancements from around the world and explains why they might be important to tech, startups or civilization. The results are a little loose but definitely recognizable. Image Credits: Shlizerman, et.
We’ve had folks working with machinelearning and AI algorithms for decades,” says Sam Gobrail, the company’s senior director for product and technology. But for practical learning of the same technologies, we rely on the internal learning academy we’ve established.”
Speech recognition remains a challenging problem in AI and machinelearning. But what makes Whisper different, according to OpenAI, is that it was trained on 680,000 hours of multilingual and “multitask” data collected from the web, which lead to improved recognition of unique accents, background noise and technical jargon.
Machinelearning can provide companies with a competitive advantage by using the data they’re collecting — for example, purchasing patterns — to generate predictions that power revenue-generating products (e.g. e-commerce recommendations). One of its proponents is Mike Del Balso, the CEO of Tecton.
Cosmos enables AI models to simulate environments and generate real-world scenarios, accelerating training for humanoid robots. NVIDIA also introduced the Isaac GR00T Blueprint, a tool for generating synthetic motion that supports the training of humanoid robots using imitation learning.
The spectrum is broad, ranging from process automation using machinelearning models to setting up chatbots and performing complex analyses using deep learning methods. They examine existing data sources and select, train and evaluate suitable AI models and algorithms. Model and data analysis.
I don’t have any experience working with AI and machinelearning (ML). We also read Grokking Deep Learning in the book club at work. Seeing a neural network that starts with random weights and, after training, is able to make good predictions is almost magical. These systems require labeled images for training.
enterprise architects ensure systems are performing at their best, with mechanisms (e.g. Cross-cutting perspectives The enterprise architect must also address and trade-off on: Performance: Ensuring that systems perform efficiently and meet business expectations. Technology can stretch deep into the business (including IT!)
In 2013, I was fortunate to get into artificial intelligence (more specifically, deep learning) six months before it blew up internationally. It started when I took a course on Coursera called “Machinelearning with neural networks” by Geoffrey Hinton. It was like being love struck.
Bailey expects there will soon be an AI transformation from personal assistant to digital colleague, with AI performing end-to-end automation tasks alongside the traditional workforce. With AI agents on the horizon, there will be a significant number of business processes that will be a much better fit for AI then we have previously seen.
Its improved architecture, based on the Multimodal Diffusion Transformer (MMDiT), combines multiple pre-trained text encoders for enhanced text understanding and uses QK-normalization to improve training stability. The model demonstrates improved performance in image quality, typography, and complex prompt understanding.
For generative AI models requiring multiple instances to handle high-throughput inference requests, this added significant overhead to the total scaling time, potentially impacting application performance during traffic spikes. We ran 5+ scaling simulations and observed consistent performance with low variations across trials.
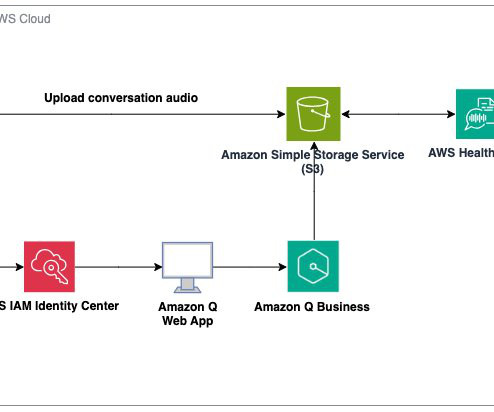
With the advent of generative AI and machinelearning, new opportunities for enhancement became available for different industries and processes. Importantly, AWS never uses customer content from Amazon Q to train its underlying AI models, making sure that company information remains private and secure.
To achieve optimal performance for specific use cases, customers are adopting and adapting these FMs to their unique domain requirements. Tuning model architecture requires technical expertise, training and fine-tuning parameters, and managing distributed training infrastructure, among others.
According to a recent Skillable survey of over 1,000 IT professionals, it’s highly likely that your IT training isn’t translating into job performance. Four in 10 IT workers say that the learning opportunities offered by their employers don’t improve their job performance. Learning is failing IT.
WhyLabs , a machinelearning startup that was spun out of the Allen Institute last year, helps data teams monitor the health of their AI models and the data pipelines that fuel them. Today, the post-deployment maintenance of machinelearning models, I think, is a bigger challenge than the actual building and deployment of models.
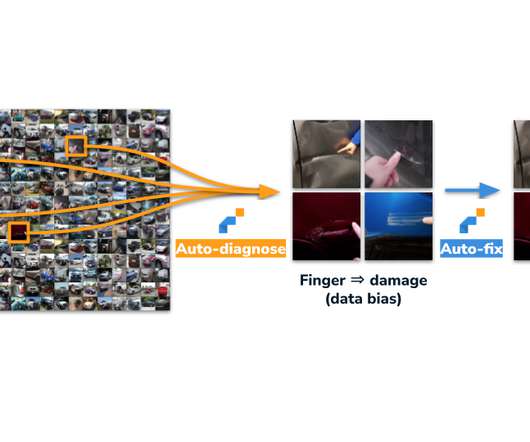
LatticeFlow , a startup that was spun out of Zurich’s ETH in 2020, helps machinelearning teams improve their AI vision models by automatically diagnosing issues and improving both the data and the models themselves. LatticeFlow uncovers a bias in data for training car damage inspection AI models.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content