This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For all the excitement about machinelearning (ML), there are serious impediments to its widespread adoption. 8] Data about individuals can be decoded from ML models long after they’ve trained on that data (through what’s known as inversion or extraction attacks, for example). ML security audits.
Training a frontier model is highly compute-intensive, requiring a distributed system of hundreds, or thousands, of accelerated instances running for several weeks or months to complete a single job. For example, pre-training the Llama 3 70B model with 15 trillion training tokens took 6.5 During the training of Llama 3.1
New survey results highlight the ways organizations are handling machinelearning's move to the mainstream. As machinelearning has become more widely adopted by businesses, O’Reilly set out to survey our audience to learn more about how companies approach this work. What metrics are used to evaluate success?
Although machinelearning (ML) can produce fantastic results, using it in practice is complex. For example, Uber and Facebook have built Michelangelo and FBLearner Flow to manage data preparation, model training, and deployment. Machinelearning workflow challenges. algorithm) to see whether it improves results.
Today, just 15% of enterprises are using machinelearning, but double that number already have it on their roadmaps for the upcoming year. However, in talking with CEOs looking to implement machinelearning in their organizations, there seems to be a common problem in moving machinelearning from science to production.
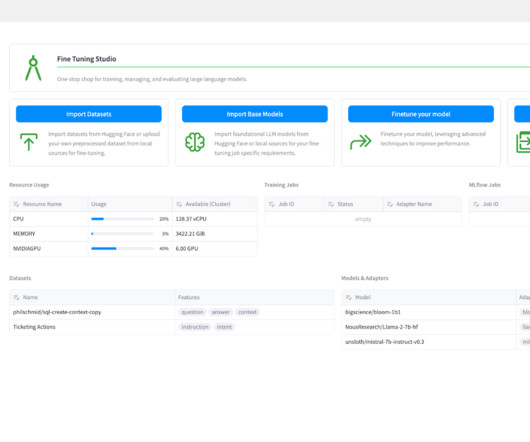
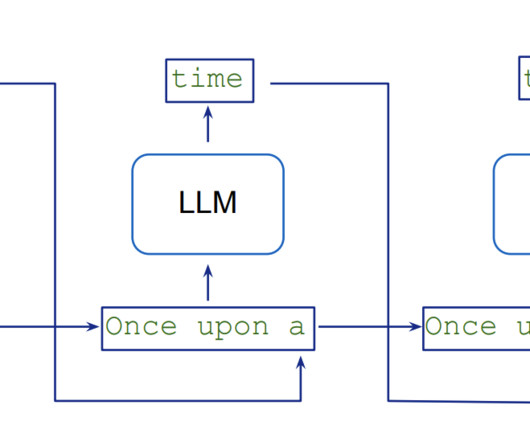
Fine tuning involves another round of training for a specific model to help guide the output of LLMs to meet specific standards of an organization. Given some example data, LLMs can quickly learn new content that wasn’t available during the initial training of the base model. Build and test training and inference prompts.
From Google and Spotify to Siri and Facebook, all of them use MachineLearning (ML), one of AI’s subsets. Whatever your motivation, you’ve come to the right place to learn the basics of the most popular machinelearning models. 5 MachineLearning Models Every Data Scientist Should Know.
The biggest problem facing machinelearning today isn’t the need for better algorithms; it isn’t the need for more computing power to train models; it isn’t even the need for more skilled practitioners. It’s getting machinelearning from the researcher’s laptop to production.
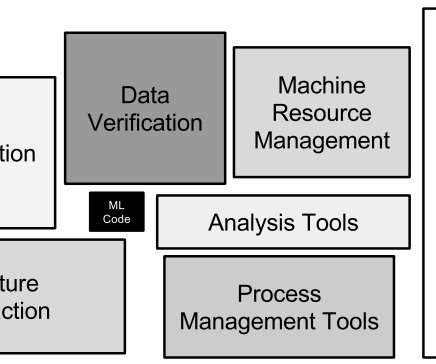
When speaking of machinelearning, we typically discuss data preparation or model building. The fusion of terms “machinelearning” and “operations”, MLOps is a set of methods to automate the lifecycle of machinelearning algorithms in production — from initial model training to deployment to retraining against new data.
Choosing the machinelearning path when developing your software is half the success. Yes, it brings automation, so widely discussed machine intelligence, and other awesome perks. So, how would you measure the success of a machinelearning model? So, how would you measure the success of a machinelearning model?
Fine-tuning is a powerful approach in natural language processing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. We also provide insights on how to achieve optimal results for different dataset sizes and use cases, backed by experimental data and performance metrics.
Demystifying RAG and model customization RAG is a technique to enhance the capability of pre-trained models by allowing the model access to external domain-specific data sources. Unlike fine-tuning, in RAG, the model doesnt undergo any training and the model weights arent updated to learn the domain knowledge.
Data analysis and machinelearning techniques are great candidates to help secure large-scale streaming platforms. In semi-supervised anomaly detection models, only a set of benign examples are required for training. That’s up to the machinelearning model to discover and avoid such false-positive incidents.
A 2020 IDC survey found that a shortage of data to train AI and low-quality data remain major barriers to implementing it, along with data security, governance, performance and latency issues. “The main challenge in building or adopting infrastructure for machinelearning is that the field moves incredibly quickly.
Machinelearning has great potential for many businesses, but the path from a Data Scientist creating an amazing algorithm on their laptop, to that code running and adding value in production, can be arduous. Ideally, this would be automatic, so your data scientists aren’t caught up training and retraining the same model.
But that’s exactly the kind of data you want to include when training an AI to give photography tips. Conversely, some of the other inappropriate advice found in Google searches might have been avoided if the origin of content from obviously satirical sites had been retained in the training set.
The market for corporate training, which Allied Market Research estimates is worth over $400 billion, has grown substantially in recent years as companies realize the cost savings in upskilling their workers. By creating what Agley calls “knowledge spaces” rather than linear training courses. ” Image Credits: Obrizum.
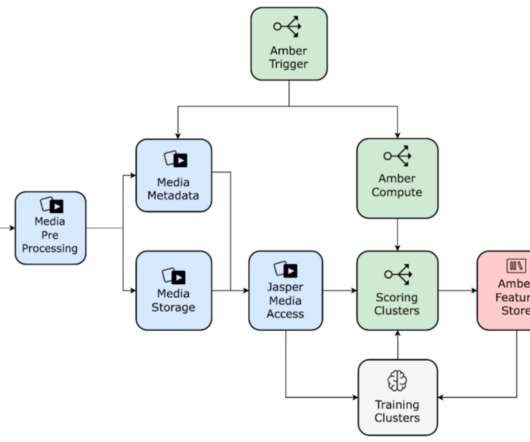
We have been leveraging machinelearning (ML) models to personalize artwork and to help our creatives create promotional content efficiently. Training Performance Media model training poses multiple system challenges in storage, network, and GPUs. Why should members care about any particular show that we recommend?
We are very excited to announce the release of five, yes FIVE new AMPs, now available in Cloudera MachineLearning (CML). In addition to the UI interface, Cloudera MachineLearning exposes a REST API that can be used to programmatically perform operations related to Projects, Jobs, Models, and Applications.
Download the MachineLearning Project Checklist. Planning MachineLearning Projects. Machinelearning and AI empower organizations to analyze data, discover insights, and drive decision making from troves of data. More organizations are investing in machinelearning than ever before.
AI and machinelearning enable recruiters to make data-driven decisions. Additionally, outlining growth opportunities within the organization, such as potential career advancement paths, training programs, and professional development resources, can make the position even more attractive to top talent.
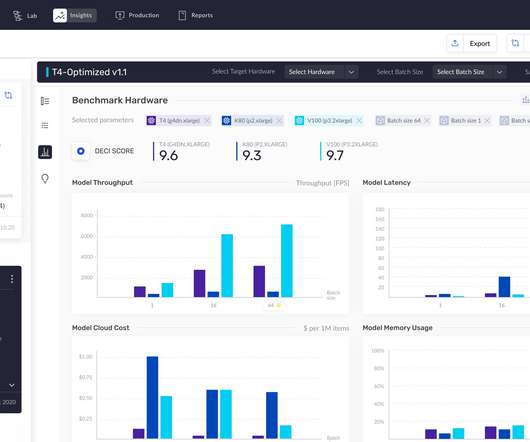
To enable this, the company built an end-to-end solution that allows engineers to bring in their pre-trained models and then have Deci manage, benchmark and optimize them before they package them up for deployment. Using its runtime container or Edge SDK, Deci users can also then serve those models on virtually any modern platform and cloud.
The company announced an impressive set of metrics this morning, including that from July 2020 to July 2021, it grew its annual recurring revenue (ARR) 4x. Then, after training models and staff, the company’s software can begin to provide support staff with answers to customer questions as they talk to customers in real time.
Model monitoring of key NLP metrics was incorporated and controls were implemented to prevent unsafe, unethical, or off-topic responses. The flexible, scalable nature of AWS services makes it straightforward to continually refine the platform through improvements to the machinelearning models and addition of new features.
Today, we have AI and machinelearning to extract insights, inaudible to human beings, from speech, voices, snoring, music, industrial and traffic noise, and other types of acoustic signals. At the same time, keep in mind that neither of those and other audio files can be fed directly to machinelearning models.
Technologies such as artificial intelligence and machinelearning allow for sophisticated segmentation and targeting, enhancing the relevance and impact of marketing messages. Joint Metrics: Developing shared key performance indicators (KPIs) to measure success collectively.
Trained on broad, generic datasets spanning a wide range of topics and domains, LLMs use their parametric knowledge to perform increasingly complex and versatile tasks across multiple business use cases. We added simplified Medusa training code, adapted from the original Medusa repository.
For automatic model evaluation jobs, you can either use built-in datasets across three predefined metrics (accuracy, robustness, toxicity) or bring your own datasets. Regular evaluations allow you to adjust and steer the AI’s behavior based on feedback and performance metrics.
In a world fueled by disruptive technologies, no wonder businesses heavily rely on machinelearning. Google, in turn, uses the Google Neural Machine Translation (GNMT) system, powered by ML, reducing error rates by up to 60 percent. The role of a machinelearning engineer in the data science team.
The Education and Training Quality Authority (BQA) plays a critical role in improving the quality of education and training services in the Kingdom Bahrain. BQA oversees a comprehensive quality assurance process, which includes setting performance standards and conducting objective reviews of education and training institutions.
Tuning model architecture requires technical expertise, training and fine-tuning parameters, and managing distributed training infrastructure, among others. Its a familiar NeMo-style launcher with which you can choose a recipe and run it on your infrastructure of choice (SageMaker HyperPod or training). recipes=recipe-name.
Additionally, investing in employee training and establishing clear ethical guidelines will ensure a smoother transition. We observe that the skills, responsibilities, and tasks of data scientists and machinelearning engineers are increasingly overlapping.
DeepSeek-R1 , developed by AI startup DeepSeek AI , is an advanced large language model (LLM) distinguished by its innovative, multi-stage training process. Instead of relying solely on traditional pre-training and fine-tuning, DeepSeek-R1 integrates reinforcement learning to achieve more refined outputs. serving workers on TGI.
Today, Artificial Intelligence (AI) and MachineLearning (ML) are more crucial than ever for organizations to turn data into a competitive advantage. Services like Hugging Face and the ONNX Model Zoo made it easy to access a wide range of pre-trained models. Data teams can use any metrics dashboarding tool to monitor these.
Real-time AI brings together streaming data and machinelearning algorithms to make fast and automated decisions; examples include recommendations, fraud detection, security monitoring, and chatbots. What metrics are used to understand the business impact of real-time AI? It isn’t easy.
. “Coho AI has developed a unique data consolidation platform that models the business value of a software-as-a-service company and maps it to the behavior of the customers in real time using machinelearning and advanced analytics,” Falcon told TechCrunch in an email interview.
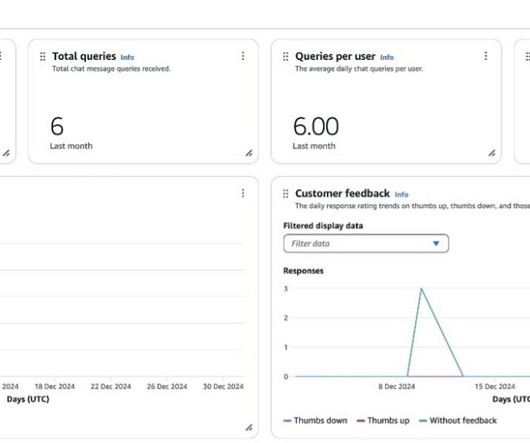
Your data is not used for training purposes, and the answers provided by Amazon Q Business are based solely on the data users have access to. By monitoring utilization metrics, organizations can quantify the actual productivity gains achieved with Amazon Q Business.
The source of this disparity may be partly attributed to a lack of diversity in the datasets used to train these systems. After all, if there are few black speakers in the data, the model will not learn those speech patterns as well. for black speakers compared with 0.19 for white speakers.” ” Not great!
Large language models (LLMs) are generally trained on large publicly available datasets that are domain agnostic. For example, Meta’s Llama models are trained on datasets such as CommonCrawl , C4 , Wikipedia, and ArXiv. The resulting LLM outperforms LLMs trained on non-domain-specific datasets when tested on finance-specific tasks.
For example, data scientists might focus on building complex machinelearning models, requiring significant compute resources. Tracking high-level metrics such as total monthly costs and identifying major cost contributors, including compute, storage, and services, allows organizations to quickly spot trends and anomalies.
SageMaker JumpStart is a machinelearning (ML) hub that provides a wide range of publicly available and proprietary FMs from providers such as AI21 Labs, Cohere, Hugging Face, Meta, and Stability AI, which you can deploy to SageMaker endpoints in your own AWS account. It’s serverless so you don’t have to manage the infrastructure.
Taylor adds that functional CIOs tend to concentrate on business-as-usual facets of IT such as system and services reliability; cost reduction and improving efficiency; risk management/ensuring the security and reliability of IT systems; and ongoing support of existing technology and tracking daily metrics.
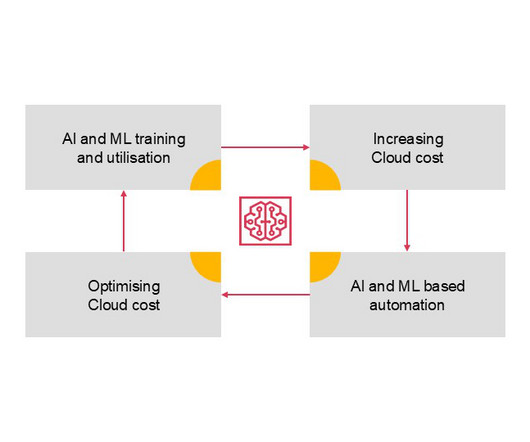
Accelerated adoption of artificial intelligence (AI) is fuelling rapid expansion in both the amount of stored data and the number of processes needed to train and run machinelearning models. AI’s impact on cloud costs – managing the challenge AI and machinelearning drive up cloud computing costs in various ways.
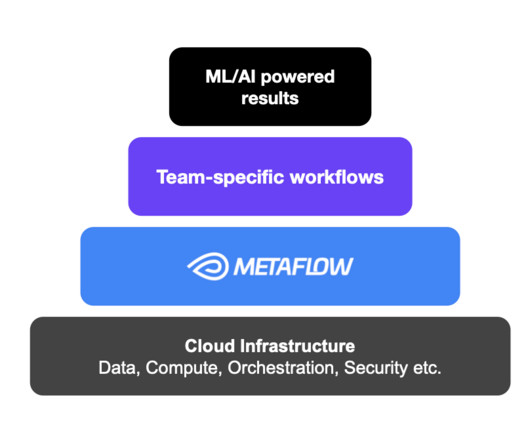
Metaboost serves as a single interface to three different internal platforms at Netflix that manage ETL/Workflows ( Maestro ), MachineLearning Pipelines ( Metaflow ) and Data Warehouse Tables ( Kragle ). training metaflows/training.py (binding=EXP_02): -> EXP_02 instance of training.py cluster=sandbox, workflow.id=demo.branch_demox.EXP_01.training
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content