This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Observability refers to the ability to understand the internal state and behavior of a system by analyzing its outputs, logs, and metrics. For a detailed breakdown of the features and implementation specifics, refer to the comprehensive documentation in the GitHub repository.
Model customization refers to adapting a pre-trained language model to better fit specific tasks, domains, or datasets. Under Input data , enter the location of the source S3 bucket (training data) and target S3 bucket (model outputs and training metrics), and optionally the location of your validation dataset.
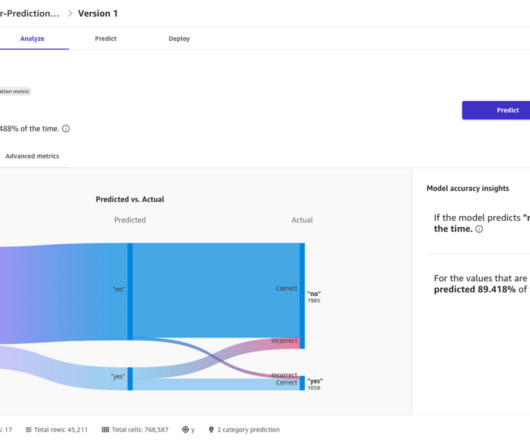
We also provide insights on how to achieve optimal results for different dataset sizes and use cases, backed by experimental data and performance metrics. The evaluation metric is the F1 score that measures the word-to-word matching of the extracted content between the generated output and the ground truth answer.
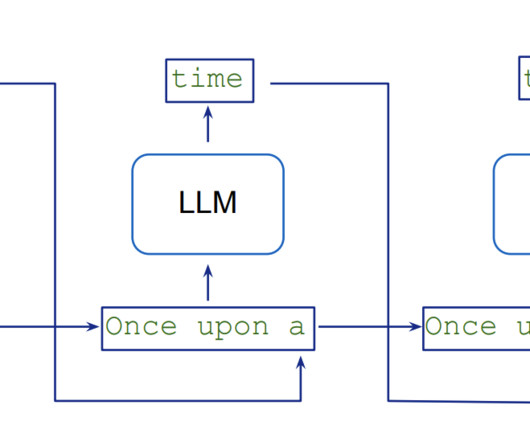
When speaking of machinelearning, we typically discuss data preparation or model building. The fusion of terms “machinelearning” and “operations”, MLOps is a set of methods to automate the lifecycle of machinelearning algorithms in production — from initial model training to deployment to retraining against new data.
Data analysis and machinelearning techniques are great candidates to help secure large-scale streaming platforms. That’s up to the machinelearning model to discover and avoid such false-positive incidents. For the one-class as well as binary anomaly detection task, such metrics are accuracy, precision, recall, f0.5,
To evaluate the transcription accuracy quality, the team compared the results against ground truth subtitles on a large test set, using the following metrics: Word error rate (WER) – This metric measures the percentage of words that are incorrectly transcribed compared to the ground truth. A lower MER signifies better accuracy.
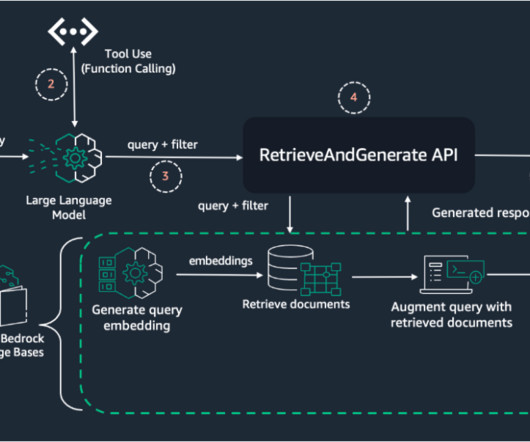
For a comprehensive overview of metadata filtering and its benefits, refer to Amazon Bedrock Knowledge Bases now supports metadata filtering to improve retrieval accuracy. To evaluate the effectiveness of a RAG system, we focus on three key metrics: Answer relevancy – Measures how well the generated answer addresses the user’s query.
Shared components refer to the functionality and features shared by all tenants. Refer to Perform AI prompt-chaining with Amazon Bedrock for more details. Additionally, contextual grounding checks can help detect hallucinations in model responses based on a reference source and a user query.
In recognition of the diverse workload that data scientists face, Cloudera’s library of Applied ML Prototypes (AMPs) provide Data Scientists with pre-built reference examples and end-to-end solutions, using some of the most cutting edge ML methods, for a variety of common data science projects. AutoML with TPOT.
It is designed to handle the demanding computational and latency requirements of state-of-the-art transformer models, including Llama, Falcon, Mistral, Mixtral, and GPT variants for a full list of TGI supported models refer to supported models. For a complete list of runtime configurations, please refer to text-generation-launcher arguments.
For instance, Pixtral Large is highly effective at spotting irregularities or insightful trends within training loss curves or performance metrics, enhancing the accuracy of data-driven decision-making. For more information on generating JSON using the Converse API, refer to Generating JSON with the Amazon Bedrock Converse API.
We then guide you through getting started with Container Caching, explaining its automatic enablement for SageMaker provided DLCs and how to reference cached versions. With its growing feature set, TorchServe is a popular choice for deploying and scaling machinelearning models among inference customers.
Lack of standardized metrics Interpersonal skills are inherently difficult to measure, and many organizations lack standardized methods or benchmarks for assessing them. Example: “Imagine you’re explaining how machinelearning works to a client with no technical background. How would you describe it?”
To assess system reliability, engineering teams often rely on key metrics such as mean time between failures (MTBF), which measures the average operational time between hardware failures and serves as a valuable indicator of system robustness. The time taken to determine the root cause is referred to as mean time to detect (MTTD).
Amazon Bedrock offers fine-tuning capabilities that allow you to customize these pre-trained models using proprietary call transcript data, facilitating high accuracy and relevance without the need for extensive machinelearning (ML) expertise. In addition, traditional ML metrics were used for Yes/No answers.
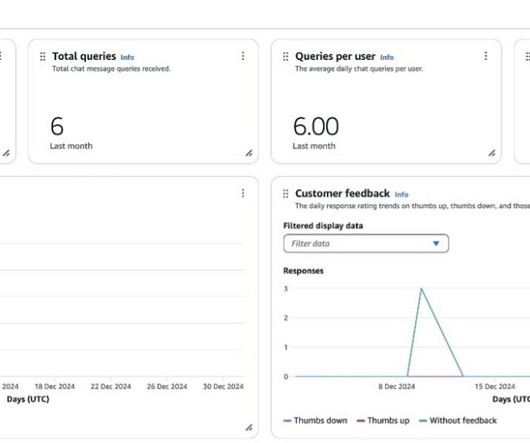
By monitoring utilization metrics, organizations can quantify the actual productivity gains achieved with Amazon Q Business. Tracking metrics such as time saved and number of queries resolved can provide tangible evidence of the services impact on overall workplace productivity.
Although automated metrics are fast and cost-effective, they can only evaluate the correctness of an AI response, without capturing other evaluation dimensions or providing explanations of why an answer is problematic. Human evaluation, although thorough, is time-consuming and expensive at scale.
Amazon SageMaker Canvas is a no-code machinelearning (ML) service that empowers business analysts and domain experts to build, train, and deploy ML models without writing a single line of code. For instructions to catalog the data, refer to Populating the AWS Glue Data Catalog. You can monitor the progress of model creation.
Today, we have AI and machinelearning to extract insights, inaudible to human beings, from speech, voices, snoring, music, industrial and traffic noise, and other types of acoustic signals. At the same time, keep in mind that neither of those and other audio files can be fed directly to machinelearning models.
To learn more details about these service features, refer to Generative AI foundation model training on Amazon SageMaker. This design simplifies the complexity of distributed training while maintaining the flexibility needed for diverse machinelearning (ML) workloads, making it an ideal solution for enterprise AI development.
With Power BI, you can pull data from almost any data source and create dashboards that track the metrics you care about the most. You can also use Power BI to prepare and manage high-quality data to use across the business in other tools, from low-code apps to machinelearning.
From human genome mapping to Big Data Analytics, Artificial Intelligence (AI),MachineLearning, Blockchain, Mobile digital Platforms (Digital Streets, towns and villages),Social Networks and Business, Virtual reality and so much more. What is MachineLearning? MachineLearning delivers on this need.
Machinelearning (ML) history can be traced back to the 1950s, when the first neural networks and ML algorithms appeared. Analysis of more than 16.000 papers on data science by MIT technologies shows the exponential growth of machinelearning during the last 20 years pumped by big data and deep learning advancements.
For automatic model evaluation jobs, you can either use built-in datasets across three predefined metrics (accuracy, robustness, toxicity) or bring your own datasets. It refers to the ability to manage, guide, and constrain AI systems to make sure they operate within desired parameters.
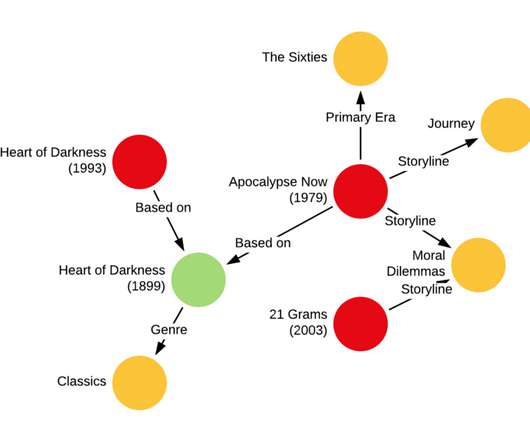
The commissioning of a series or film, which we refer to as a title , is a creative decision. The increasing vastness and diversity of what our members are watching make answering these questions particularly challenging using conventional methods, which draw on a limited set of comparable titles and their respective performance metrics (e.g.,
In this post, we demonstrate a few metrics for online LLM monitoring and their respective architecture for scale using AWS services such as Amazon CloudWatch and AWS Lambda. Overview of solution The first thing to consider is that different metrics require different computation considerations. The function invokes the modules.
Ground truth data in AI refers to data that is known to be factual, representing the expected use case outcome for the system being modeled. With deterministic evaluation processes such as the Factual Knowledge and QA Accuracy metrics of FMEval , ground truth generation and evaluation metric implementation are tightly coupled.
Review the model response and metrics provided. Amazon CloudWatch provides metrics for your imported models, helping you track usage patterns and performance. For more information, refer to the Amazon Bedrock User Guide. Consider implementing monitoring and observability. You can monitor costs with AWS Cost Explorer.
For a detailed explanation of the concept, refer to the paper Accelerating Large Language Model Decoding with Speculative Sampling. For details, refer to Creating an AWS account. For more information, refer Configure the AWS CLI. We use JupyterLab in Amazon SageMaker Studio running on an ml.t3.medium
But a particular category of startup stood out: those applying AI and machinelearning to solve problems, especially for business-to-business clients. The platform is powered by large language models (think GPT-3) that reference several sources to find the most likely answers, according to co-founder Michael Royzen.
Beyond this, LibLab monitors and updates the SDK “when the language evolves,” according to Ofek, and shows metrics that indicate how the API is being used. But it’s true that code-generating systems have become more capable in recent years with the advent of sophisticated machinelearning techniques.
How do Amazon Nova Micro and Amazon Nova Lite perform against GPT-4o mini in these same metrics? Vector database FloTorch selected Amazon OpenSearch Service as a vector database for its high-performance metrics. How well do these models handle RAG use cases across different industry domains? Each provisioned node was r7g.4xlarge,
self.config) self.next(self.end) @step def end(self): pass if __name__ == "__main__": ConfigurableFlow() There is a lot going on in the code above, a few highlights: you can refer to configs before they have been defined using config_expr. From the developers point of view, Configs behave like dictionary-like artifacts.
An ideal candidate has skills in the 3 fields: mathematics/ statistics/ machinelearning/ programming and business/ domain knowledge. . MachineLearning and Programming. Apart from the programming skills, the candidate should have a good understanding of machinelearning concepts like: Classification and Regression.
You can also use this model with Amazon SageMaker JumpStart , a machinelearning (ML) hub that provides access to algorithms and models that can be deployed with one click for running inference. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5%
It often requires managing multiple machinelearning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats. He leads machinelearning initiatives and projects across business domains, leveraging multimodal AI, generative models, computer vision, and natural language processing.
Distillation refers to a process of training smaller, more efficient models to mimic the behavior and reasoning patterns of the larger DeepSeek-R1 model, using it as a teacher model. Solution overview You can use DeepSeeks distilled models within the AWS managed machinelearning (ML) infrastructure.
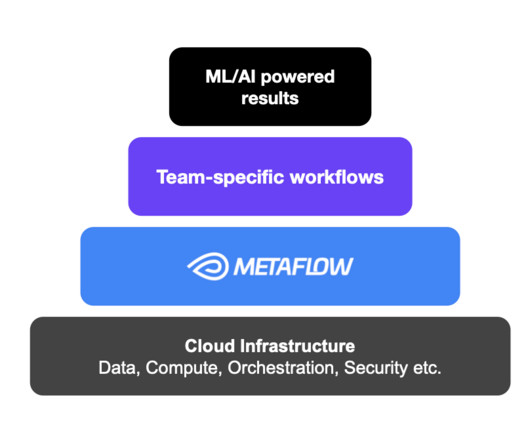
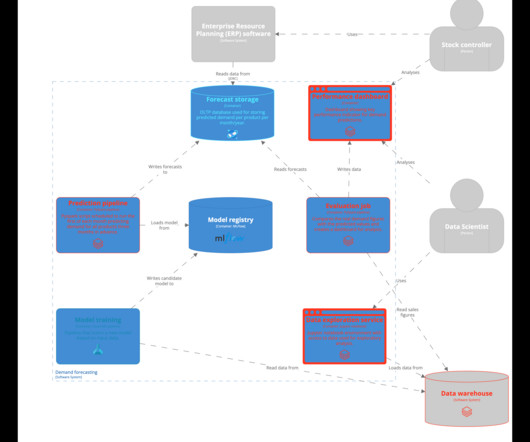
With the industry moving towards end-to-end ML teams to enable them to implement MLOPs practices, it is paramount to look past the model and view the entire system around your machinelearning model. Demand forecasting is chosen because it’s a very tangible problem and very suitable application for machinelearning.
Customer satisfaction score (CSAT) and Net Promoter Score (NPS) are the most important metrics for any insurance company. But it does need more advanced approaches that mimic human perception and judgment like AI, MachineLearning, and ML-based Robotic Process Automation. Hire machinelearning specialists on the team.
We’ll discuss collecting data about client relationship with a brand, characteristics of customer behavior that correlate the most with churn, and explore the logic behind selecting the best-performing machinelearning models. Identifying at-risk customers with machinelearning: problem-solving at a glance.
This feature provides users the ability to explore metrics with natural language. Tableau Pulse will then send insights for that metric directly to the executive’s preferred communications platform: Slack, email, mobile device, etc. Metrics Bootstrapping. Metric Goals.
Machinelearning (ML) research has proven that large language models (LLMs) trained with significantly large datasets result in better model quality. For more detailed information, refer to Getting Started with Fully Sharded Data Parallel (FSDP). For more information, refer to Getting started with Llama.
Governance in the context of generative AI refers to the frameworks, policies, and processes that streamline the responsible development, deployment, and use of these technologies. For a comprehensive read about vector store and embeddings, you can refer to The role of vector databases in generative AI applications.
Gen AI takes us from single-use models of machinelearning (ML) to AI tools that promise to be a platform with uses in many areas, but you still need to validate they’re appropriate for the problems you want solved, and that your users know how to use gen AI effectively. Now nearly half of code suggestions are accepted.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content