This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
On March 25, 2021, between 14:39 UTC and 18:46 UTC we had a significant outage that caused around 5% of our global traffic to stop being served from one of several loadbalancers and disrupted service for a portion of our customers. At 18:46 UTC we restored all traffic remaining on the Google loadbalancer. What happened.
As EVs continue to gain popularity, they place a substantial load on the grid, necessitating infrastructure upgrades and improved demand response solutions. In addition, renewable energy sources such as wind and solar further complicate grid management due to their intermittent nature and decentralized generation.
Loadbalancer – Another option is to use a loadbalancer that exposes an HTTPS endpoint and routes the request to the orchestrator. You can use AWS services such as Application LoadBalancer to implement this approach. API Gateway also provides a WebSocket API.
Region Evacuation with DNS approach: At this point, we will deploy the previous web server infrastructure in several regions, and then we will start reviewing the DNS-based approach to regional evacuation, leveraging the power of AWS Route 53. We’ll study the advantages and limitations associated with this technique.
To share your thoughts, join the AoAD2 open review mailing list. Evolutionary System Architecture. What about your system architecture? By system architecture, I mean all the components that make up your deployed system. Your network gateways and loadbalancers. Your feedback is appreciated!
Network flapping is a kind of malfunction that is generated due to an extra advanced mechanism of traffic control in the network. So, when it alternates randomly during a broadcast of a single data item, then extra pressure puts on the network due to unnecessary routing traffic. So, what we can conclude: We can’t go anywhere.
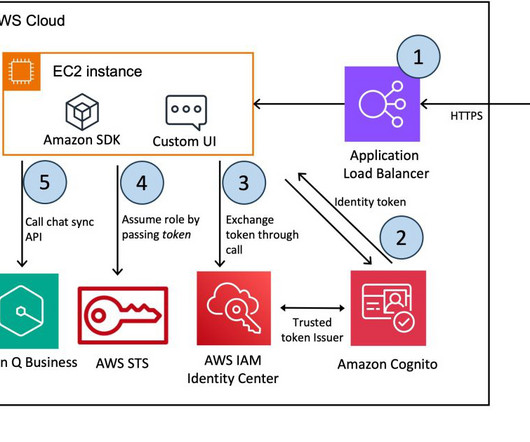
Amazon Q can help you get fast, relevant answers to pressing questions, solve problems, generate content, and take actions using the data and expertise found in your company’s information repositories and enterprise systems. Review all the steps and create the application. The following diagram illustrates the solution architecture.
How to use a Virtual Machine in your Computer System? In simple words, If we use a Computer machine over the internet which has its own infrastructure i.e. So once a client wants a game to be developed which should run on All of the operating Systems (i.e. So this was an example in terms of operating systems. Management.
The easiest way to use Citus is to connect to the coordinator node and use it for both schema changes and distributed queries, but for very demanding applications, you now have the option to loadbalance distributed queries across the worker nodes in (parts of) your application by using a different connection string and factoring a few limitations.
In addition, you can also take advantage of the reliability of multiple cloud data centers as well as responsive and customizable loadbalancing that evolves with your changing demands. Cloud adoption also provides businesses with flexibility and scalability by not restricting them to the physical limitations of on-premises servers.
Cloud Systems Engineer, Amazon Web Services. Ansible is a powerful automation tool that can be used for managing configuration state or even performing coordinated multi-system deployments. Setting Up an Application LoadBalancer with an Auto Scaling Group and Route 53 in AWS. ” – Mohammad Iqbal.
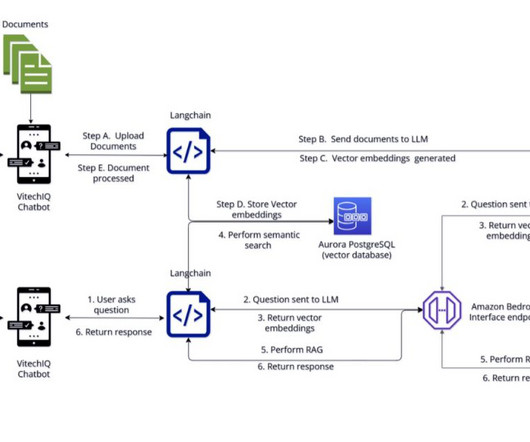
Prompt engineering Prompt engineering is crucial for the knowledge retrieval system. The Streamlit app is hosted on an Amazon Elastic Cloud Compute (Amazon EC2) fronted with Elastic LoadBalancing (ELB), allowing Vitech to scale as traffic increases. Prompts also help ground the model.
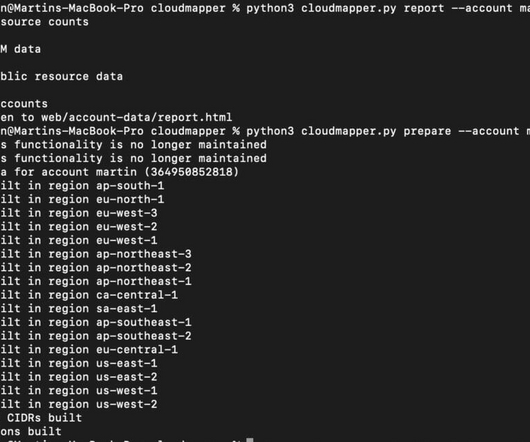
We define Observability as the set of practices for aggregating, correlating, and analyzing data from a system in order to improve monitoring, troubleshooting, and general security. One for my Disaster Recovery blog post ( vpc_demo ) depicting an ASG and two loadbalancers on different AZs. SLAs and warranty. python cloudmapper.py
With AWS generative AI services like Amazon Bedrock , developers can create systems that expertly manage and respond to user requests. An AI assistant is an intelligent system that understands natural language queries and interacts with various tools, data sources, and APIs to perform tasks or retrieve information on behalf of the user.
If you’re implementing complex RAG applications into your daily tasks, you may encounter common challenges with your RAG systems such as inaccurate retrieval, increasing size and complexity of documents, and overflow of context, which can significantly impact the quality and reliability of generated answers. We use an ml.t3.medium
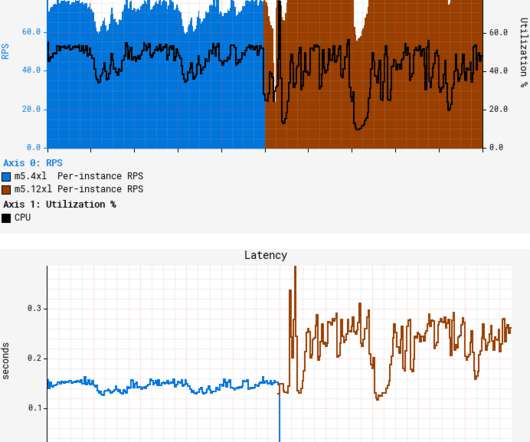
Additionally, SageMaker endpoints support automatic loadbalancing and autoscaling, enabling your LLM deployment to scale dynamically based on incoming requests. Optimizing these metrics directly enhances user experience, system reliability, and deployment feasibility at scale. 12xlarge suitable for performance comparison.
While it is impossible to completely rule out the possibility of downtime, IT teams can implement strategies to minimize the risk of business interruptions due to system unavailability. High availability is often synonymous with high-availability systems, high-availability environments or high-availability servers.
Convore pivoted into Grove, a chat service for workgroups, which she sold to Revolution Systems in October 2012. Tanya Reilly has been a Systems Administrator and Site Reliability Engineer at Google since 2005, working on low-level infrastructure like distributed locking, loadbalancing, and bootstrapping.
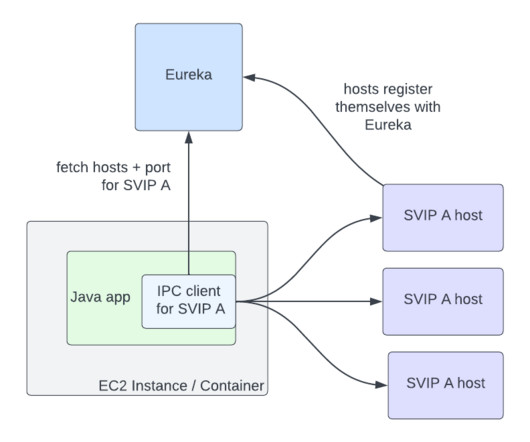
For Inter-Process Communication (IPC) between services, we needed the rich feature set that a mid-tier loadbalancer typically provides. To improve availability, we designed systems where components could fail separately and avoid single points of failure.
Loadbalancing and scheduling are at the heart of every distributed system, and Apache Kafka ® is no different. Kafka clients—specifically the Kafka consumer, Kafka Connect, and Kafka Streams, which are the focus in this post—have used a sophisticated, paradigmatic way of balancing resources since the very beginning.
The best practice for security purposes is to use a Gateway Collector so production systems don’t need to communicate externally. However, that’s not always true, especially in larger systems. Due to the flexibility of deployment, the next three subsections talk about each deployment location. More in this in the next section.
An important part of ensuring a system is continuing to run properly is around gathering relevant metrics about the system so that they can either have alerts triggered on them, or graphed to aid diagnosing problems. Introduction. The metrics are stored in blocks encompassing a configured period of time (by default 2 hours).
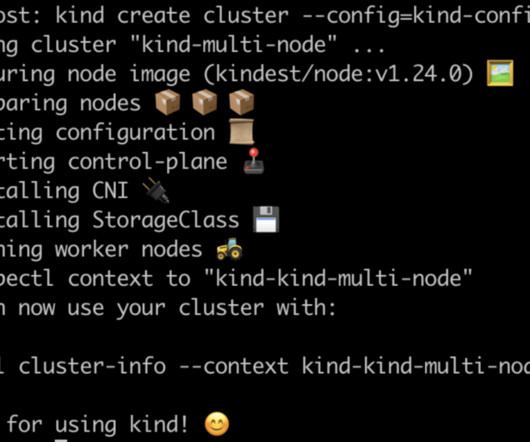
All of the above methods suffer from a few shortcomings, making it difficult to test a Kubernetes setup without modifying or circumventing part of the system to make it work. The two main problems I encountered frequently were a) running multiple nodes and b) using loadbalancers. So Kind was the starting point for my solution.
AEM structure includes instances that vary from environment to environment like Author Instance, Publish Instance, Dispatcher, and LoadBalancer. Any created content or page in AEM gets reviewed and confirmed in three stages i.e., Development, Stage, and Production environment.
Explaining the Architecture The ‘Master’ ArgoCD As per below, the master ArgoCD will be deployed 'manually' or through automation via any event-driven system into a dedicated Kubernetes cluster – hence it will not be managed by ArgoCD. The concept of Federation is a decentralization of power (i.e.,
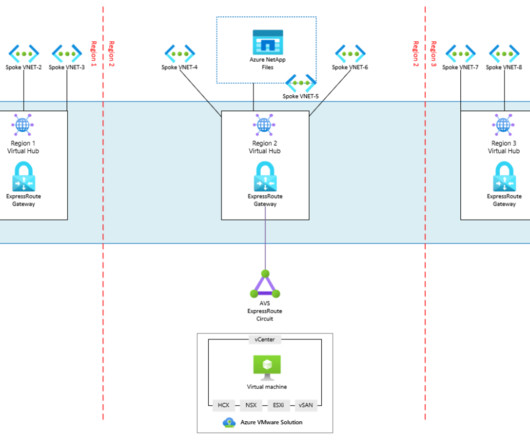
In this article, we’ll review network connections for integrating AVS into other Azure services and systems outside of Azure. Management systems within the AVS environment will not honor the 0.0.0.0/0 Azure Public IP addresses can be consumed by NSX Edge and leveraged for NSX services like SNAT, DNAT, or LoadBalancing.
Do you work with distributed software systems? They’re normally more robust and reliable than single systems, but they have a more complex network architecture. But these metrics usually are at an individual service level, like a particular internet gateway or loadbalancer. Distributed Systems Are Complex.
AWS Certified Solutions Architect Official Study Guide — This official study guide, written by AWS experts, covers exam concepts and provides key review on exam topics.
This includes reviewing computer science fundamentals like DBMS, Operating Systems, practicing data structures and algorithms (DSA), front-end languages and frameworks, back-end languages and frameworks, system design, database design and SQL, computer networks, and object-oriented programming (OOP).
GS2 is a stateless service that receives traffic through a flavor of round-robin loadbalancer, so all nodes should receive nearly equal amounts of traffic. a contiguous chunk of data (typically 64 bytes on x86 systems) transferred to and from the cache. Cache line is a concept similar to memory page?—?a
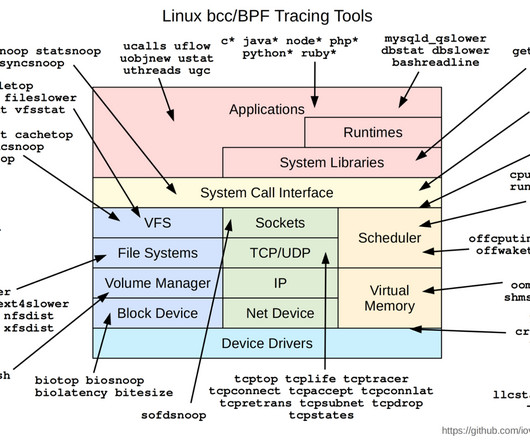
eBPF is a lightweight runtime environment that gives you the ability to run programs inside the kernel of an operating system, usually a recent version of Linux. Those calls could be for kernel services, network services, accessing the file system, and so on. This could be due to congestion or even errors on the remote NIC.
The language empowers ease of coding through its simple syntax, ORM support for seamless database management, robust cross-platform support, and efficient scalability tools like caching and loadbalancing. To better review Pythons application in enterprise and ERP software development, lets review a real-life use case.
So, developers often build bridges – Application Programming Interfaces – to have one system get access to the information or functionality of another. Remote Procedure Call (RPC): invoking a function on another system. Tight coupling to the underlying system. Four major API styles compared. How RPC works.
Is the system working? First, let’s talk about what makes a system “work.” If we don’t know that our system is running, then it’s not done. If we can’t find out how healthy our system is, we can’t give our stakeholders confidence that the system will continue functioning. What is instrumentation?
Operating within these constraints, the system gains desirable properties. ?lient-server Properties gained: modifiability, better system reliability. In the REST API system, the client and server work independently, using different tech stacks. Properties gained: improved system scalability and security. REST vs RPC.
Making sure you have valid unit test and regression test coverage also prevents problems that arise due to any changes to the codebase required later for scaling. Partition tolerance — the system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes. Scaling file storage.
Let’s review the code elements to gain a better understanding of what’s going on. Kubernetes gives pods their own IP addresses and a single DNS name for a set of pods, and can load-balance across them. In this example, we’re using the LoadBalancer type, which exposes the service externally using a cloud provider’s load-balancer.
Clearly, there must be a mechanism to coordinate the work of such complex distributed systems, and that’s exactly what Kubernetes was designed for by Google back in 2014. A ship loaded with containers, in our case. The unusual name came from an ancient Greek word for helmsman — someone steering a ship.
Review the official Atlassian Licensing FAQs as this is subject to change. Server doesn’t support clustering and high-availability, which is crucial for ensuring a mission-critical system is accessible 24/7. When systems go down, loss of productivity translates into extra cost for your company.
Key management systems handle encryption keys. System metadata is reviewed and updated regularly. The secure cluster is one in which all data, both data-at-rest and data-in-transit, is encrypted and the key management system is fault-tolerant. It scales linearly by adding more Knox nodes as the load increases.
ALB User Authentication: Identity Management at Scale with Netflix Will Rose , Senior Security Engineer Abstract: In the zero-trust security environment at Netflix, identity management has historically been a challenge due to the reliance on its VPN for all application access. 1:45pm NET404-R?—?Elastic November 27 3:15pm CMP377?—?Capacity
This blog post provides an overview of best practice for the design and deployment of clusters incorporating hardware and operating system configuration, along with guidance for networking and security as well as integration with existing enterprise infrastructure. Please review the full networking and security requirements. .
This isolation improves overall system reliability and availability. Data Consistency: Maintaining data consistency across services can be challenging due to the decentralized nature of data management. Configuration can be stored in a variety of sources, such as Git repositories, file systems, or databases.
Smart retail and customer 360: Real-time integration between mobile apps of customers and backend services like CRMs, loyalty systems, geolocation, and weather information creates a context-specific customer view and allows for better cross-selling, promotions, and other customer-facing services. Example: E.ON. Example: Target. Lightweight.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content