This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
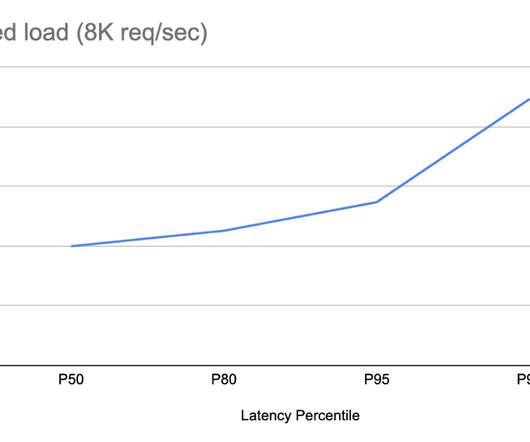
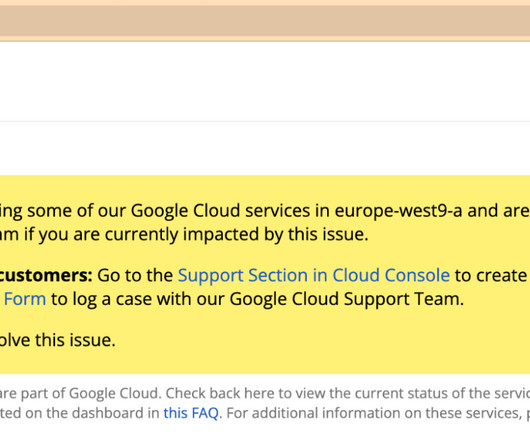
On March 25, 2021, between 14:39 UTC and 18:46 UTC we had a significant outage that caused around 5% of our global traffic to stop being served from one of several loadbalancers and disrupted service for a portion of our customers. At 18:46 UTC we restored all traffic remaining on the Google loadbalancer. What happened.
Loadbalancer – Another option is to use a loadbalancer that exposes an HTTPS endpoint and routes the request to the orchestrator. You can use AWS services such as Application LoadBalancer to implement this approach. API Gateway also provides a WebSocket API.
Region Evacuation with DNS approach: At this point, we will deploy the previous web server infrastructure in several regions, and then we will start reviewing the DNS-based approach to regional evacuation, leveraging the power of AWS Route 53. We’ll study the advantages and limitations associated with this technique.
The public cloud infrastructure is heavily based on virtualization technologies to provide efficient, scalable computing power and storage. Cloud adoption also provides businesses with flexibility and scalability by not restricting them to the physical limitations of on-premises servers. Scalability and Elasticity.
How to use a Virtual Machine in your Computer System? In simple words, If we use a Computer machine over the internet which has its own infrastructure i.e. So once a client wants a game to be developed which should run on All of the operating Systems (i.e. So this was an example in terms of operating systems. Management.
The easiest way to use Citus is to connect to the coordinator node and use it for both schema changes and distributed queries, but for very demanding applications, you now have the option to loadbalance distributed queries across the worker nodes in (parts of) your application by using a different connection string and factoring a few limitations.
Amazon SageMaker AI provides a managed way to deploy TGI-optimized models, offering deep integration with Hugging Faces inference stack for scalable and cost-efficient LLM deployment. Optimizing these metrics directly enhances user experience, system reliability, and deployment feasibility at scale.
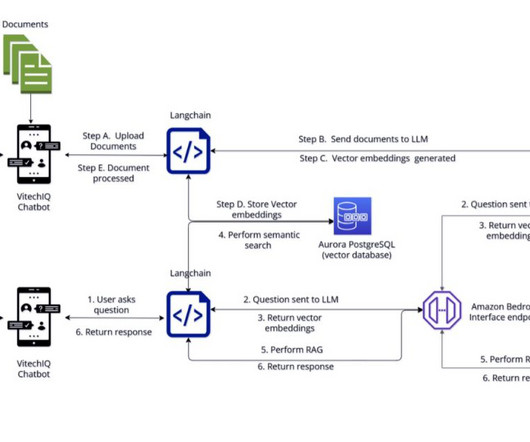
Prompt engineering Prompt engineering is crucial for the knowledge retrieval system. The Streamlit app is hosted on an Amazon Elastic Cloud Compute (Amazon EC2) fronted with Elastic LoadBalancing (ELB), allowing Vitech to scale as traffic increases. Prompts also help ground the model.
With AWS generative AI services like Amazon Bedrock , developers can create systems that expertly manage and respond to user requests. An AI assistant is an intelligent system that understands natural language queries and interacts with various tools, data sources, and APIs to perform tasks or retrieve information on behalf of the user.
Python in Web Application Development Python web projects often require rapid development, high scalability to handle high traffic, and secure coding practices with built-in protections against vulnerabilities. This way, Pythons rich ecosystem and scalability make it integral to Netflixs AI innovation.
Loadbalancing and scheduling are at the heart of every distributed system, and Apache Kafka ® is no different. Kafka clients—specifically the Kafka consumer, Kafka Connect, and Kafka Streams, which are the focus in this post—have used a sophisticated, paradigmatic way of balancing resources since the very beginning.
While it is impossible to completely rule out the possibility of downtime, IT teams can implement strategies to minimize the risk of business interruptions due to system unavailability. High availability is often synonymous with high-availability systems, high-availability environments or high-availability servers.
If you’re implementing complex RAG applications into your daily tasks, you may encounter common challenges with your RAG systems such as inaccurate retrieval, increasing size and complexity of documents, and overflow of context, which can significantly impact the quality and reliability of generated answers. We use an ml.t3.medium
Most scenarios require a reliable, scalable, and secure end-to-end integration that enables bidirectional communication and data processing in real time. Different teams can develop, maintain, and change integration to devices and machines without being dependent on other sources or the sink systems that process and analyze the data.
Agile Project Management: Agile management is considered the best practice in DevOps when operating in the cloud due to its ability to enhance collaboration, efficiency, and adaptability. By breaking down complex applications into smaller, independent components, microservices allow for better scalability, flexibility, and fault tolerance.
An important part of ensuring a system is continuing to run properly is around gathering relevant metrics about the system so that they can either have alerts triggered on them, or graphed to aid diagnosing problems. Introduction. The metrics are stored in blocks encompassing a configured period of time (by default 2 hours).
Similarly, the issue of scalability is truly solved as each team has its own dedicated ArgoCD instance that can manage as many cluster(s) as they want – without compromising the resource and algorithmic integrity of ArgoCD within the Kubernetes cluster and within the entire ArgoCD ecosystem as well.
Its principles were formulated in 2000 by computer scientist Roy Fielding and gained popularity as a scalable and flexible alternative to older methods of machine-to-machine communication. Operating within these constraints, the system gains desirable properties. ?lient-server It still remains the gold standard for public APIs.
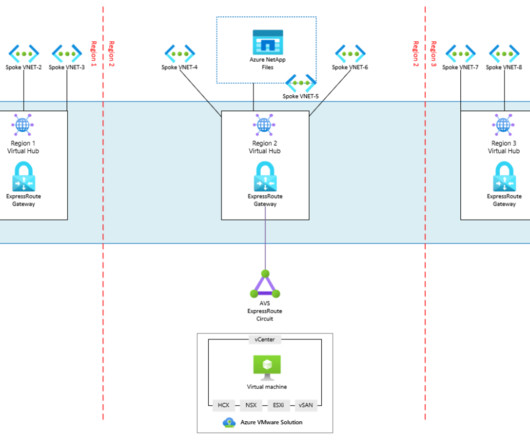
In this article, we’ll review network connections for integrating AVS into other Azure services and systems outside of Azure. Management systems within the AVS environment will not honor the 0.0.0.0/0 Azure Public IP addresses can be consumed by NSX Edge and leveraged for NSX services like SNAT, DNAT, or LoadBalancing.
So, developers often build bridges – Application Programming Interfaces – to have one system get access to the information or functionality of another. Remote Procedure Call (RPC): invoking a function on another system. Tight coupling to the underlying system. Four major API styles compared. How RPC works.
Advantages: Scalability: Services can be scaled independently according to their specific load and performance requirements. This isolation improves overall system reliability and availability. Data Consistency: Maintaining data consistency across services can be challenging due to the decentralized nature of data management.
Making sure you have valid unit test and regression test coverage also prevents problems that arise due to any changes to the codebase required later for scaling. Partition tolerance — the system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes. Scaling file storage.
As the number of Titus users increased over the years, the load and pressure on the system increased substantially. cell): Titus Job Coordinator is a leader elected process managing the active state of the system. When a new leader is elected it loads all data from external storage.
I needed something to manage the containers, because they needed to be connected to the outside world for tasks such as loadbalancing, distribution and scheduling. It provides developers and DevOps with the software they need to build and deploy distributed, scalable, and reliable systems.
Key management systems handle encryption keys. System metadata is reviewed and updated regularly. The secure cluster is one in which all data, both data-at-rest and data-in-transit, is encrypted and the key management system is fault-tolerant. Auditing procedures keep track of who accesses the cluster (and how).
Competitors with agile, modern platforms can gain a market advantage by offering capabilities that are too cost-prohibitive or technically complex for aging systems to implement. A performance bottleneck in a single area necessitates complex refactoring or the acquisition of additional infrastructure to bolster the entire system.
Review the official Atlassian Licensing FAQs as this is subject to change. Server doesn’t support clustering and high-availability, which is crucial for ensuring a mission-critical system is accessible 24/7. When systems go down, loss of productivity translates into extra cost for your company.
This blog post provides an overview of best practice for the design and deployment of clusters incorporating hardware and operating system configuration, along with guidance for networking and security as well as integration with existing enterprise infrastructure. Please review the full networking and security requirements. .
Coupling all components requires extra effort; moreover, in a few cases, vulnerabilities increase to respond to the changes in the system. is an open-source server environment that can run on multiple operating systems like Windows, Linux, Unix, MacOS, and many more. 6) Integration with existing systems: Node.js Employing Node.js
Camille offers a holistic definition of platform engineering: “ a product approach to developing internal platforms that create leverage by abstracting away complexity , being operated to provide reliable and scalable foundations , and by enabling application engineers to focus on delivering great products and user experiences.”
Data migration projects range from a mundane database upgrade to a global shift of the enterprise system to the cloud. Among cons of the do-it-yourself approach is the need for coding skills, extra time your engineers have to spend on scripting, and scalability issues. Performance and scalability. Types of data migration tools.
Scaling Push Messaging for Millions of Netflix Devices Susheel Aroskar , Senior Software Engineer Abstract: Netflix built Zuul Push, a massively scalable push messaging service that handles millions of always-on, persistent connections to proactively push time-sensitive data, like personalized movie recommendations, from the AWS Cloud to devices.
No wonder Amazon Web Services has become one of the pillars of todays digital economy, as it delivers flexibility, scalability, and agility. AWS cost optimization: The basic things to know AWS provides flexibility and scalability, making it an almost irreplaceable tool for businesses, but these same benefits often lead to inefficiencies.
It offers unparalleled scalability, flexibility, and cost-effectiveness. In this blog, we will highlight five specific strategies for Cloud FinOps, focusing on autoscaling, budgets, reservations, monitoring for under-utilized resources, and architecting systems for cost efficiency. Docker) allows for better resource utilization.
Through AWS, Azure, and GCP’s respective cloud platforms, customers have access to a variety of storage, computation, and networking options.Some of the features shared by all three systems include fast provisioning, self-service, autoscaling, identity management, security, and compliance. You will pay $5.32
Outsourcing QA has become the norm on account of its ability to address the scalability of testing initiatives and bring in a sharper focus on outcome-based engagements. Due care needs to be exercised to know if their recommendations are grounded in delivery experience. An often overlooked area is the partner’s integrity.
Here are a few examples of potential unintended side effects of relying on multizonal infrastructure for resiliency: Split-brain scenario : In a multizonal deployment with redundant components, such as loadbalancers or routers, a split-brain scenario can occur. I wrote an article a while ago addressing latency.
I also had to read a lot, not only about technologies, but also about operating systems, volumes, and Unix sockets, among others things. The concept is quite simple, instead of attacking 30 nations at the same time, they devised an adoption system in which each of the tribes could adhere to the empire and obtain its benefits.
In this post we will provide details of the NMDB system architecture beginning with the system requirements?—?these A fundamental requirement for any lasting data system is that it should scale along with the growth of the business applications it wishes to serve. key value stores generally allow storing any data under a key).
They want to deploy a powerful content management solution on a scalable and highly available platform and also shift focus from infrastructure management so that their IT teams focus on content delivery. AEM serves as a hybrid Content Management System (CMS) that enables you to deliver and manage context-optimized omnichannel experiences.
Allocate scan ranges to nodes based on data locality and the scheduler’s loadbalancing heuristics. This trade-off can be managed by changing –admission_control_slots to be greater than, or equal to the number of cores on the system. The process is summarized below. Impact to Resource Consumption. Analytic Functions.
Let’s first review a few basic Kubernetes concepts: Pod: “A pod is the basic building block of Kubernetes,” which encapsulates containerized apps, storage, a unique network IP, and instructions on how to run those containers. It is a network solution for Kubernetes and is described as simple, scalable and secure.
Replication is a crucial capability in distributed systems to address challenges related to fault tolerance, high availability, loadbalancing, scalability, data locality, network efficiency, and data durability. It forms a foundational element for building robust and reliable distributed architectures.
Scalability and capacity planning: Moreover, capacity planning is difficult for businesses in the growth stage due to cyclical change in demand that places an unpredictable load on IT infrastructure. Easy scalability. Cloud services offer high scalability and availability to their users. Hybrid Cloud.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content