This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Architecting a multi-tenant generative AI environment on AWS A multi-tenant, generative AI solution for your enterprise needs to address the unique requirements of generative AI workloads and responsible AI governance while maintaining adherence to corporate policies, tenant and data isolation, access management, and cost control.
Knowing your project needs and tech capabilities results in great scalability, constant development speed, and long-term viability: Backend: Technologies like Node.js Cloud & infrastructure: Known providers like Azure, AWS, or Google Cloud offer storage, scalable hosting, and networking solutions. Frontend: Angular, React, or Vue.js
With cyber threats on the rise, enterprises require robust network security policy management solutions to protect their valuable data and infrastructure. Network security has never been more critical in the era of digital transformation.
Transit VPCs are a specific hub-and-spoke network topology that attempts to make VPC peering more scalable. This is a simple and often overlooked strategy that gives the best of both worlds: strict separation of IAM policies and cost attribution with simple inter-connection at the network level.
The goal is to deploy a highly available, scalable, and secure architecture with: Compute: EC2 instances with Auto Scaling and an Elastic LoadBalancer. Implement Role-Based Access Control (RBAC): Use IAM roles and policies to restrict access. Networking: A secure VPC with private and public subnets.
Additionally, it uses NVIDIAs parallel thread execution (PTX) constructs to boost training efficiency, and a combined framework of supervised fine-tuning (SFT) and group robust policy optimization (GRPO) makes sure its results are both transparent and interpretable.
and JWT, and can enforce authorization policies for APIs. Scalability : Kong is designed to scale horizontally, allowing it to handle large amounts of API traffic. Authentication and Authorization : Kong supports various authentication methods, including API key, OAuth 2.0,
They are portable, fast, secure, scalable, and easy to manage, making them the primary choice over traditional VMs. Loadbalancers. Docker Swarm clusters also include loadbalancing to route requests across nodes. Loadbalancing. Kubernetes does not have an auto load-balancing mechanism.
Consider integrating Amazon Bedrock Guardrails to implement safeguards customized to your application requirements and responsible AI policies. Performance optimization The serverless architecture used in this post provides a scalable solution out of the box.
Scalability and performance – The EMR Serverless integration automatically scales the compute resources up or down based on your workload’s demands, making sure you always have the necessary processing power to handle your big data tasks. By unlocking the potential of your data, this powerful integration drives tangible business results.
They can also augment their API endpoints with required authn/authz policy and rate limiting using the FilterPolicy and RateLimit custom resources. In Kubernetes, there are various choices for loadbalancing external traffic to pods, each with different tradeoffs. although appropriately coupled at runtime?—?developers
In the current digital environment, migration to the cloud has emerged as an essential tactic for companies aiming to boost scalability, enhance operational efficiency, and reinforce resilience. Our checklist guides you through each phase, helping you build a secure, scalable, and efficient cloud environment for long-term success.
The release of CDP Private Cloud Base has seen a number of significant enhancements to the security architecture including: Apache Ranger for security policy management. Apache Ranger consolidates security policy management with tag based access controls, robust auditing and integration with existing corporate directories.
This approach also helped us enforce a no-logs policy and significantly reduce logging storage costs ,” said Bruno. With Refinery, OneFootball no longer needs separate fleets of loadbalancer Collectors and standard Collectors. Interested in learning more? Book a call with our experts.
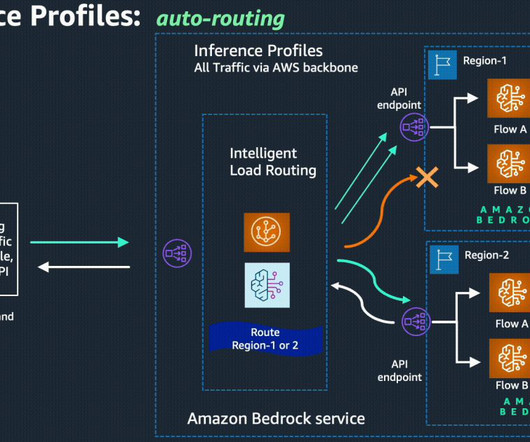
Currently, users might have to engineer their applications to handle scenarios involving traffic spikes that can use service quotas from multiple regions by implementing complex techniques such as client-side loadbalancing between AWS regions, where Amazon Bedrock service is supported.
Configuring resource policies and alerts. Create a LoadBalanced VM Scale Set in Azure. Candidates must have at least one year of experience developing scalable solutions through all phases of software development and be skilled in at least one cloud-supported programming language. Creating and managing alerts.
It is effective at optimizing network traffic in today’s constantly morphing environments and can manage network connections with an intent-based policy model – but as a security solution, it has limitations. ZTA works by protecting individual assets inside the network and setting policies at a granular level. Dynamic loadbalancing.
This unified distribution is a scalable and customizable platform where you can securely run many types of workloads. Externally facing services such as Hue and Hive on Tez (HS2) roles can be more limited to specific ports and loadbalanced as appropriate for high availability. policies can also be defined.
Create and configure an Amazon Elastic LoadBalancer (ELB) and target group that will associate with our cluster’s ECS service. It enables developers to deploy and manage scalable applications that run on groups of servers, called clusters, through application programming interface (API) calls and task definitions.
Python in Web Application Development Python web projects often require rapid development, high scalability to handle high traffic, and secure coding practices with built-in protections against vulnerabilities. This way, Pythons rich ecosystem and scalability make it integral to Netflixs AI innovation.
Deploying the VM-Series with Google Cloud LoadBalancers allows horizontal scalability as your workloads grow and high availability to protect against failure scenarios. The NGFW policy engine also provides detailed telemetry from the service mesh for forensics and analytics. Schedule 1:1 time with us.
Container technology offers benefits such as greater resource efficiency, portability, consistency and scalability. In some cases such as Google Kubernetes Engine (GKE) Autopilot clusters, GKE also handles node management, provisioning and scalability. Loadbalancing. Elastic provisioning and scalability.
For the midrange user where cost is a key factor and massive scalability is not required, the architecture has to be changed to trade off scalability for reduced cost. This also provides the ability to loadbalance across a SAN without the worry of creating a performance issue on the storage.
Advantages: Scalability: Services can be scaled independently according to their specific load and performance requirements. Service Discovery: Other services query the Eureka Server to find the instances of a particular service, enabling dynamic routing and loadbalancing. Order Service, Product Service).
Have a centralized ArgoCD 'Master' controller wherein all decisions regarding RBAC policies, the addition of clusters, deployment, and management of the entire ArgoCD platform are succeeded by this central controller. So why a federated architecture? The purpose of this architecture is to achieve three central goals.
Examples of metrics include CPU usage as a percentage, memory usage in megabytes, response times in milliseconds, requests per second, and the number of connections to a loadbalancer. Scalability: Details resource utilization and identifies performance bottlenecks. Teams can plan for and implement scalable solutions.
Using VSA, technicians can remotely control and deploy policy-based user access privileges to enforce security policies across on-premises devices and VMs. Virtual machines: These are the scalable computing resources that cloud Infrastructure-as-a-Service (IaaS) provides. Leverage policy-based configuration in VSA.
These services not only provide options for geo-distribution, caching, fragmentation, checks, and more, they also allow setting policies for accessing the file (read and write). Even when data and file storage are fully distributed and easily scalable, your application might not perform well. Traffic optimization. Continuously scaling.
In e-commerce, speed and scalability reign supreme. Loading time is key to attract customers trying to design a product. CloudFront required BRIKL’s engineers to manually set up new distribution sources for their traffic, create new loadbalancers, set origin paths, dictate HTTP protocol policy, create cache policies, and more.
It comes with greater scalability, control, and customization. Scalability and reliability are some of the advantages of community clouds. Scalability: These services are highly scalable and help manage workload, ensuring the performance of the hardware and software. With the help of a stable internet connection.
Replication is a crucial capability in distributed systems to address challenges related to fault tolerance, high availability, loadbalancing, scalability, data locality, network efficiency, and data durability. Note: SRM supports custom topic naming policies through a plugin called replication policy.
Introducing Amazon EC2 C6i instances – C6i instances are powered by 3rd generation Intel Xeon Scalable processors (code named Ice Lake) with an all-core turbo frequency of 3.5 Customers can use Elastic Fabric Adapter on the 32xlarge size, which enables low latency and highly scalable inter-node communication. Networking.
Introducing Amazon EC2 C6i instances – C6i instances are powered by 3rd generation Intel Xeon Scalable processors (code named Ice Lake) with an all-core turbo frequency of 3.5 Customers can use Elastic Fabric Adapter on the 32xlarge size, which enables low latency and highly scalable inter-node communication. Networking.
Scalability and Resource Constraints: Scaling distributed deployments can be hindered by limited resources, but edge orchestration frameworks and cloud integration help optimise resource utilisation and enable loadbalancing. In short, SASE involves fusing connectivity and security into a singular cloud-based framework.
Scalability Demands As the volume of data grows, the systems have to handle & manage the data without compromising on performance. S3 provides availability, security, and scalability, all of which come at a significantly low cost. Scalability AWS provides EC2 instances that can be scaled up or down.
Some ways to consider “Value” are how critical the application is to the company mission, potential operational savings, improvements to customer experience, improved performance or scalability, or the availability of new capabilities. . Scalable and Higher Quality Apps. Replatforming provides greater benefits than simply rehosting.
Ivanti Sentry Ivanti Sentry is a highly scalable appliance server that can be deployed in your environment as a virtual machine (VM) on-premises or in the cloud (AWS or Azure). After adding services, the next step is to create or assign a conditional access policy. This gives you the flexibility to place Sentry servers where needed.
Service/Micro-service : A Kubernetes Service is an abstraction which defines a logical set of pods and a policy by which to access them. AOS (Apstra) - enables Kubernetes to quickly change the network policy based on application requirements. Project Calico (Open Source) - a container networking provider and network policy engine.
No wonder Amazon Web Services has become one of the pillars of todays digital economy, as it delivers flexibility, scalability, and agility. AWS cost optimization: The basic things to know AWS provides flexibility and scalability, making it an almost irreplaceable tool for businesses, but these same benefits often lead to inefficiencies.
Deploying the VM-Series with Google Cloud LoadBalancers allows horizontal scalability as your workloads grow and high availability to protect against failure scenarios. The NGFW policy engine also provides detailed telemetry from the service mesh for forensics and analytics. Schedule 1:1 time with us.
They want to deploy a powerful content management solution on a scalable and highly available platform and also shift focus from infrastructure management so that their IT teams focus on content delivery. Progressing from visiting a website to filling out an online form, as one example, should be a seamless process.
There's also a no questions asked 30-day return policy. Leverage this data across your monitoring efforts and integrate with PerfOps’ other tools such as Alerts, Health Monitors and FlexBalancer – a smart approach to loadbalancing. Try a free preview today.
When the resource-based policy enables any principal to carry out an action on the function, the action can be considered public from the identity perspective. When configuring a function URL with NONE, a resource-based policy is created that enables the principal to carry out lambda:InvokeFunctionUrl action on the function.
Deploying the VM-Series with Google Cloud LoadBalancers allows horizontal scalability as your workloads grow and high availability to protect against failure scenarios. The NGFW policy engine also provides detailed telemetry from the service mesh for forensics and analytics.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content