This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Loadbalancer – Another option is to use a loadbalancer that exposes an HTTPS endpoint and routes the request to the orchestrator. You can use AWS services such as Application LoadBalancer to implement this approach. API Gateway also provides a WebSocket API.
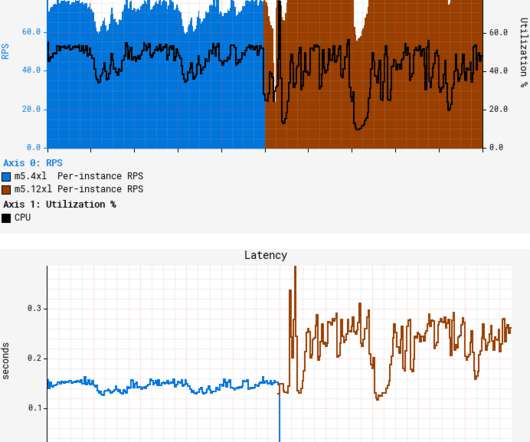
Additionally, SageMaker endpoints support automatic loadbalancing and autoscaling, enabling your LLM deployment to scale dynamically based on incoming requests. Optimizing these metrics directly enhances user experience, system reliability, and deployment feasibility at scale. xlarge across all metrics.
How to use a Virtual Machine in your Computer System? In simple words, If we use a Computer machine over the internet which has its own infrastructure i.e. So once a client wants a game to be developed which should run on All of the operating Systems (i.e. So this was an example in terms of operating systems. Management.
With AWS generative AI services like Amazon Bedrock , developers can create systems that expertly manage and respond to user requests. An AI assistant is an intelligent system that understands natural language queries and interacts with various tools, data sources, and APIs to perform tasks or retrieve information on behalf of the user.
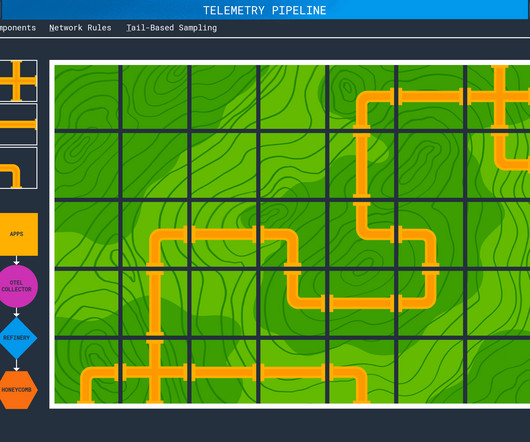
In a simple deployment, an application will emit spans, metrics, and logs which will be sent to api.honeycomb.io The best practice for security purposes is to use a Gateway Collector so production systems don’t need to communicate externally. This also adds the blue lines, which denote metrics data. and show up in charts.
Do you work with distributed software systems? They’re normally more robust and reliable than single systems, but they have a more complex network architecture. Common monitoring metrics are latency, packet loss, and jitter. Distributed Systems Are Complex. Cloud providers often hide much of this complexity.
An important part of ensuring a system is continuing to run properly is around gathering relevant metrics about the system so that they can either have alerts triggered on them, or graphed to aid diagnosing problems. The metrics are stored in blocks encompassing a configured period of time (by default 2 hours).
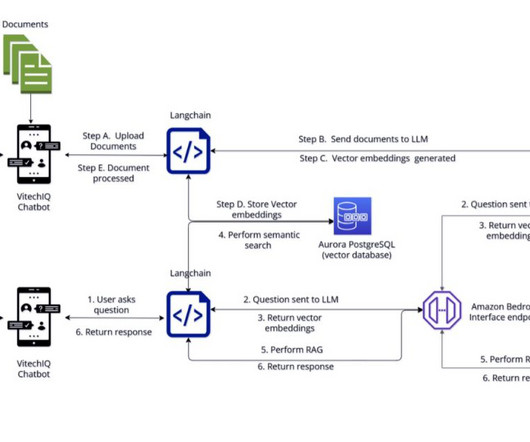
Prompt engineering Prompt engineering is crucial for the knowledge retrieval system. The Streamlit app is hosted on an Amazon Elastic Cloud Compute (Amazon EC2) fronted with Elastic LoadBalancing (ELB), allowing Vitech to scale as traffic increases. Prompts also help ground the model.
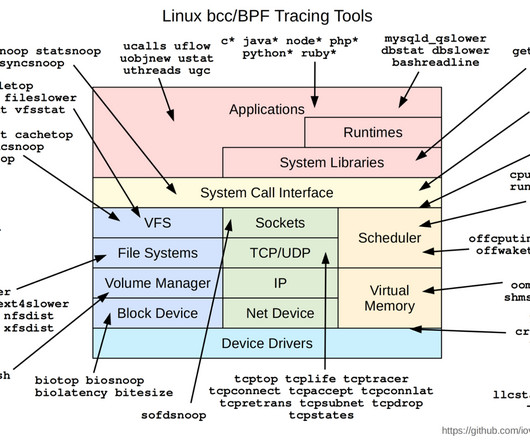
eBPF is a lightweight runtime environment that gives you the ability to run programs inside the kernel of an operating system, usually a recent version of Linux. Those calls could be for kernel services, network services, accessing the file system, and so on. This could be due to congestion or even errors on the remote NIC.
Get the latest on the Hive RaaS threat; the importance of metrics and risk analysis; cloud security’s top threats; supply chain security advice for software buyers; and more! . Yes, keeping tabs on, for example, the number of patched systems and the percentage of trained staffers is a good start. What would this look like?
GS2 is a stateless service that receives traffic through a flavor of round-robin loadbalancer, so all nodes should receive nearly equal amounts of traffic. a contiguous chunk of data (typically 64 bytes on x86 systems) transferred to and from the cache. Cache line is a concept similar to memory page?—?a
Due care needs to be exercised to know if their recommendations are grounded in delivery experience. The Puppet report further mentions that companies at a high level of DevOps maturity use ticketing systems 16% more than what is used by companies at the lower end of the maturity scale.
Power Your Projects with Python Professionals HIRE PYTHON DEVELOPERS The World of Python: Key Stats and Observations Python confidently leads the ranking of the most popular programming languages , outperforming its closest competitors, C++ by 53.44% and Java by 58%, based on popularity metrics. of respondents reporting they love it.
Making sure you have valid unit test and regression test coverage also prevents problems that arise due to any changes to the codebase required later for scaling. Partition tolerance — the system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes. Scaling file storage.
Unfortunately, we’ve ended up with a different problem: modern software systems can only be operated by the developers who created them. Can operations staff take care of complex issues like loadbalancing, business continuity, and failover, which the applications developers use through a set of well-designed abstractions?
As your traffic rises and falls, you can set up auto-scaling on a specific metric (e.g., Therefore, you can bring the number of containers up or down in response to fluctuations in the selected metric. It’s cost-effective because you can better utilize the available resources and not use them on operating system overhead.
In this blog, we will highlight five specific strategies for Cloud FinOps, focusing on autoscaling, budgets, reservations, monitoring for under-utilized resources, and architecting systems for cost efficiency. With autoscaling schedules, you can proactively plan and adjust resources based on known usage patterns.
Sample system diagram for an Alexa voice command. The other main use case was RENO, the Rapid Event Notification System mentioned above. Rewriting always comes with a risk, and it’s never the first solution we reach for, particularly when working with a system that’s in place and working well.
Let’s review a few important product announcements for each. loadbalancing, application acceleration, security, application visibility, performance monitoring, service discovery and more. Consistent LoadBalancing for Multi-Cloud Environments. Kubernetes. NSX Cloud: Consistently Extend NSX to AWS and Azure.
Elastic Beanstalk handles the provisioning of resources such as EC2 instances, loadbalancers, and databases, allowing developers to focus on their application’s code. The service auto-configures capacity provisioning, loadbalancing, scaling, and application health monitoring details.
Replication is a crucial capability in distributed systems to address challenges related to fault tolerance, high availability, loadbalancing, scalability, data locality, network efficiency, and data durability. Use the /v2/topic-metrics/{source}/{target}/{upstreamTopic}/{metric} endpoint instead.
Let’s first review a few basic Kubernetes concepts: Pod: “A pod is the basic building block of Kubernetes,” which encapsulates containerized apps, storage, a unique network IP, and instructions on how to run those containers. It basically takes a set of isolated stateless sidecar proxies and turns them into a distributed system.
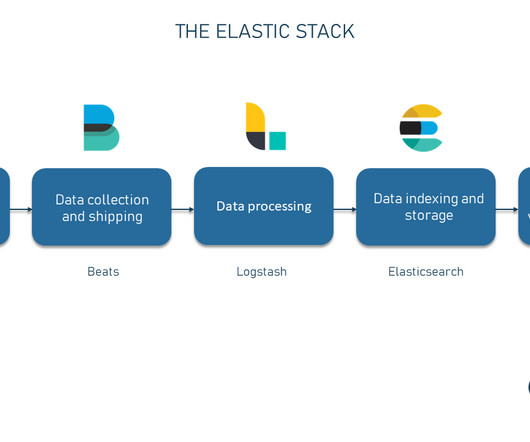
But if you’re doing it *right*, more people will want to start using the system and you will need to either limit access to the interface, or scale it up. Elastic stack doesn’t include traces or the ability to view them side-by-side with events from your systems.
The primary hosting pattern to migrate was a.NET application running on a Windows instance behind a loadbalancer. For SSM documents, we pushed in-process spans to a stack saved to the local file system. Does introducing a new agent version preserve the stability of the system or does it de-stabilized it? Conclusion.
In this post we will provide details of the NMDB system architecture beginning with the system requirements?—?these A fundamental requirement for any lasting data system is that it should scale along with the growth of the business applications it wishes to serve. key value stores generally allow storing any data under a key).
Microservices have become the dominant architectural paradigm for building large-scale distributed systems, but until now, their inner workings at major tech companies have remained shrouded in mystery. are generated by platforms like their ML inference system that create separate services for each tenant.
We share a lot of experience with metrics and monitoring technologies, although she kind of despises them and I feel a profound affection for them. A knack for systems thinking, paired with equal interest in both human & technological systems.
An issue in a shared service, or a key network component, can lead to alerts in many dependent applications, which, while all accurately reflecting the state of systems, can slow issue remediation. Topology and dependency info will allow the LM platform to suppress alerts from the dependent systems. on that service as a whole.
We will review some of the building blocks that make Elasticsearch and OpenSearch some of the leading analytics and search engines. Client nodes act as a gateway to the cluster and help loadbalance the incoming ingest and search requests. We will review some of the most common data types in a later section. Client Nodes.
A NOC, pronounced like the word knock, is an internal or a third-party facility for monitoring and managing an organization’s networked devices and systems. A typical NOC uses various tools and techniques to monitor and manage networks, systems and applications. What is a Network Operations Center (NOC)?
Then, when developers we’re ready to ship their unit of code, they would turn to our Operations team to manage the runtime configurations, exposing the application on a single port, managing the loadbalancers, SSL termination and making sure the DNS records were pointing to the right location. at least as the runtime platform.
From those home-made beginnings as Compass, Elasticsearch has matured into one of the leading enterprise search engines, standing among the top 10 most popular database management systems globally according to the Stack Overflow 2023 Developer Survey. Analysis of logs, metrics, and security events. Real-time behavior modeling with ML.
The outage caused 404 errors for downstream customers using Google Cloud LoadBalancing (GCLB). Problem response, on the other hand, tends to happen after problems are noted, prioritized, and assigned to an individual for review. Incident Response.
The software layer can consist of operating systems, virtual machines, web servers, and enterprise applications. The infrastructure engineer supervises all three layers making sure that the entire system. However, according to Steve Traugott , “that got me conflated with systems integrator, so I later defaulted to engineer myself.”.
Generally, the goal of multi-homing is to use both upstream provider connections in a sane manner and “load-balance” them. You don’t need BGP to load-balance; you can do that almost as well with a “round-robin” or “route-caching.” We’ll be talking more about metrics in the future.
As a distributed system for collecting, storing, and processing data at scale, Apache Kafka ® comes with its own deployment complexities. You don’t have to wait for the next official release of Kafka and avoid getting stuck due to bugs in the software. You would miss project deadlines due to technical difficulties.
A10 Networks is a networking industry leader, and their series of application networking, loadbalancing, and DDoS protection solutions accelerate and secure the applications and networks of the world’s largest enterprises, service providers, and cloud platforms. A10 solutions help protect some of the world's largest networks.
Moving away from hardware-based loadbalancers and other edge appliances towards the software-based “programmable edge” provided by Envoy clearly has many benefits, particularly in regard to dynamism and automation. Here operations team will specify sensible system defaults, and also adapt these in real-time based on external events.
AWS provides a few native tools that can help you gather cost data and systemmetrics to identify cost-related inefficiencies in your setup: AWS Cost Explorer. Use the Trusted Advisor Idle LoadBalancers Check to get a report of loadbalancers that have a request count of less than 100 over the past seven days.
You’ve got APM, and metrics, and Net NPM, and DDoS protection, and it all needs to work, and it all needs to be related. If the link is congested, then a basic NetFlow tool function allows you to double click on that, and you can see that the link is full because there’s tons of traffic due to the database servers syncing.
The disruption of network bandwidth or performance to any particular set of services can create a disastrous ripple effect on the entire application eco-system, which makes it critical to protect more than just north-south, client-server Web traffic. with BGP, GeoIP, SNMP, and performance metrics from packet capture.
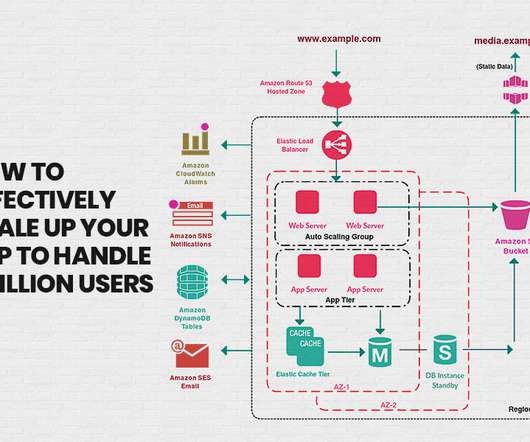
With the customer feedback and user’s review, you may improve and upgrade the app with the additional features which in turn increase your app users. In simple words, the scalability of the app is the capacity of the system to handle the load of the application and ensure the smooth functioning of the app with the increasing user load.
Antifragile Systems 4. Mobile Apps The Cloud In 2003 Nicholas Carr’s controversial article “IT Doesn’t Matter” was published in Harvard Business Review. Using the Google File System as a model, they spent 2004 working on a distributed file system for Nutch. The Cloud 2. Big Data 3. Content Platforms 5.
Deep systems” (microservices) create new problems in understandability, observability, and debuggability I’ve been hearing some interesting buzz about “deep systems” for the past few months, primarily from Ben Sigelman and the Lightstep team. But now we are building deep systems in the cloud.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content