This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As these applications scale, and engineering for reliability comes into the forefront, DevOps engineers begin to rely on networking concepts like loadbalancing, auto-scaling, traffic management, and network security. Following are a few key ways NetOps and DevOps can collaborate to make more reliable systems.
In this post we will provide details of the NMDB systemarchitecture beginning with the system requirements?—?these these will serve as the necessary motivation for the architectural choices we made. For example, “requests-per-second” (RPS) is commonly used to auto-scale micro services to serve increased reads or queries.
Performance numbers, system health, and growth projections are derived from the decomposed data elements. Reporting typically a subset of the data in a warehouse that is dedicated to a particular consumer with nice charts and graphs to show key business metrics. How many other pieces of architecture have to be designed to go with that?
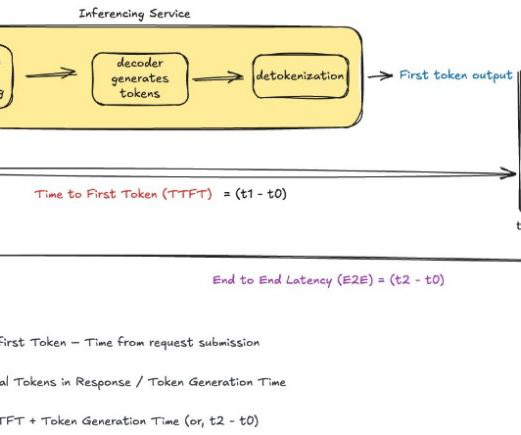
To effectively optimize AI applications for responsiveness, we need to understand the key metrics that define latency and how they impact user experience. These metrics differ between streaming and nonstreaming modes and understanding them is crucial for building responsive AI applications. Haiku and Metas Llama 3.1 70B models.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content