This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Loadbalancer – Another option is to use a loadbalancer that exposes an HTTPS endpoint and routes the request to the orchestrator. You can use AWS services such as Application LoadBalancer to implement this approach. API Gateway also provides a WebSocket API.
This setup will adopt the usage of cloud loadbalancing, auto scaling and managed SSL certificates. The way Google configures the VMs results in two remaining abilities: read/write access to Cloud Logging and read access to Cloud Storage. This MIG will act as the backend service for our loadbalancer.
Notable runtime parameters influencing your model deployment include: HF_MODEL_ID : This parameter specifies the identifier of the model to load, which can be a model ID from the Hugging Face Hub (e.g., 11B-Vision-Instruct ) or Simple Storage Service (S3) URI containing the model files. xlarge across all metrics.
Loadbalancing – you can use this to distribute a load of incoming traffic on your virtual machine. OS guest diagnostics – You can turn this on to get the metrics per minute. NIC network security group – It consists of the security rules that we want to apply on our network. For details – [link].
PostgreSQL 16 has introduced a new feature for loadbalancing multiple servers with libpq, that lets you specify a connection parameter called load_balance_hosts. You can use query-from-any-node to scale query throughput, by loadbalancing connections across the nodes. Postgres 16 support in Citus 12.1
They must track key metrics, analyze user feedback, and evolve the platform to meet customer expectations. Measuring your success with key metrics A great variety of metrics helps your team measure product outcomes and pursue continuous growth strategies. It usually focuses on some testing scenarios that automation could miss.
MaestroQA also offers a logic/keyword-based rules engine for classifying customer interactions based on other factors such as timing or process steps including metrics like Average Handle Time (AHT), compliance or process checks, and SLA adherence. Success metrics The early results have been remarkable.
When evaluating solutions, whether to internal problems or those of our customers, I like to keep the core metrics fairly simple: will this reduce costs, increase performance, or improve the network’s reliability? It’s often taken for granted by network specialists that there is a trade-off among these three facets. Resiliency.
Honeycomb’s SLOs allow teams to define, measure, and manage reliability based on real user impact, rather than relying on traditional system metrics like CPU or memory usage. Instead, they consolidate logs, metrics, and traces into a unified workflow.
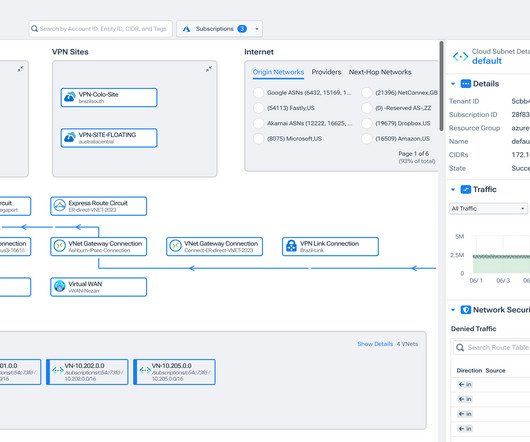
It includes rich metrics for understanding the volume, path, business context, and performance of flows traveling through Azure network infrastructure. For example, Express Route metrics include data about inbound and outbound dropped packets.
Additionally, you can access device historical data or device metrics. The device metrics are stored in an Athena DB named "iot_ops_glue_db" in a table named "iot_device_metrics". It is hosted on Amazon Elastic Container Service (Amazon ECS) with AWS Fargate , and it is accessed using an Application LoadBalancer.
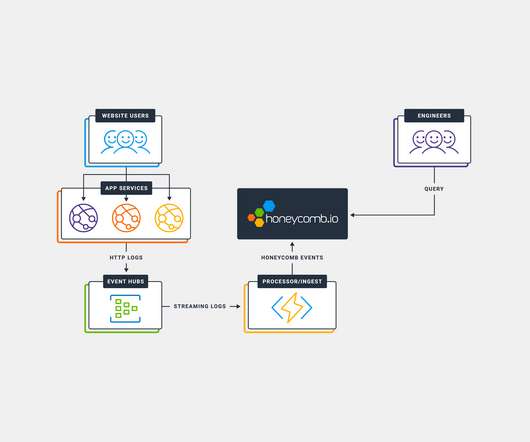
In a simple deployment, an application will emit spans, metrics, and logs which will be sent to api.honeycomb.io This also adds the blue lines, which denote metrics data. The metrics are periodically emitted from applications that don’t contribute to traces, such as a database. and show up in charts.
An important part of ensuring a system is continuing to run properly is around gathering relevant metrics about the system so that they can either have alerts triggered on them, or graphed to aid diagnosing problems. The metrics are stored in blocks encompassing a configured period of time (by default 2 hours). Introduction.
Decompose these into quantifiable KPIs to direct the project, utilizing metrics like migration duration, savings on costs, and enhancements in performance. critical, frequently accessed, archived) to optimize cloud storage costs and performance. lowering costs, enhancing scalability). How to prevent it?
Get the latest on the Hive RaaS threat; the importance of metrics and risk analysis; cloud security’s top threats; supply chain security advice for software buyers; and more! . But to truly map cybersecurity efforts to business objectives, you’ll need what CompTIA calls “an organizational risk approach to metrics.”.
Implement Elastic LoadBalancing Implementing elastic loadbalancing (ELB) is a crucial best practice for maximizing PeopleSoft performance on AWS. Implementing ELB for PeopleSoft workloads involves defining relevant health checks, load-balancing algorithms, and session management settings.
For instance, it may need to scale in terms of offered features, or it may need to scale in terms of processing or storage. But at some point it becomes impossible to add more processing power, bigger attached storage, faster networking, or additional memory. Scaling data storage. Scaling file storage.
This is supplemental to the awesome post by Brian Langbecker on using Honeycomb to investigate the Application LoadBalancers (ALB) Status Codes in AWS. Since Azure AppService also has a LoadBalancer serving the application servers, we can use the same querying techniques to investigate AppService performance.
This bursting is intentional and guided by state-of-the-art monitoring and metrics to know exactly which tiers of the application need to be scaled to maintain SLA’s (Service Level Agreements). Federating Metrics. Aggregating metrics from diverse nodes is feasible with tooling such as Prometheus. Machine Learning.
Divide ETL works with Series of Mappings Use Concurrent Workflow Exec setting to enable parallel loads with different Params Process ETL in multiple batches (ex. 2 times a day) to release the Table post load If Complex ETL logic causes slowness, use FILE as TGT. Delegate load b/w DB and ETL Servers.
For example, one deployment might require more nodes or storage capacity than another, and these resources can be allocated or adjusted as needed without affecting the other deployments. Availability ECE provides features such as automatic failover and loadbalancing, which can help ensure high availability and minimize downtime.
DevOps is blind to the network While DevOps teams may be skilled at building and deploying applications in the cloud, they may have a different level of expertise when it comes to optimizing cloud networking, storage, and security. Unaddressed, this can lead to unreliable (and unsafe) application environments.
Elastic LoadBalancing: Implementing Elastic LoadBalancing services in your cloud architecture ensures that incoming traffic is distributed efficiently across multiple instances. It is critical to regularly rationalize your cloud environments and look for places to reduce tier sizes or de-provision un-used resources.
Consul is a popular “infra tool” that can be used as a distributed key-value storage, as well as a service discovery feature that includes back end storing IPs, ports, health info, and metadata about discovered services. Consul is quite flexible and the monitoring system has numerous metrics. What is Consul?
That said, the only way to get that 50% cost reduction is to install the AWS CloudWatch Agent on your instances and configure it to send memory metrics to CloudWatch. If you are not running the agent…then no memory metrics. Since the Graviton2 is built to support M, C, and R, I think we are much more likely to see widespread use.
Organized Data Storage AWS S3 (Simple Storage Service) stores the structured, unstructured, or semi-structured data. Performance Monitoring on the Cloud AWS CloudWatch serves as a vigilant monitoring tool that provides alarms and logs for tracking and analysis of ETL job performance metrics, ensuring efficient and optimized workflows.
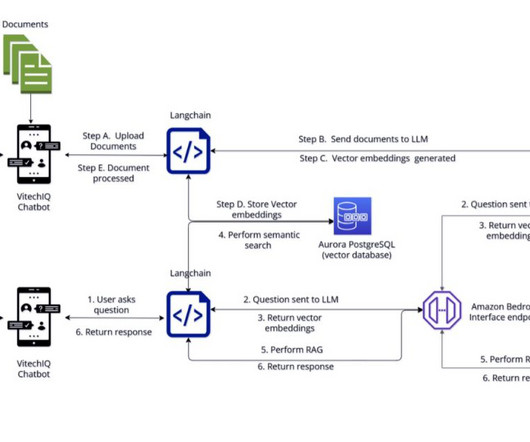
These documents are uploaded and stored in Amazon Simple Storage Service (Amazon S3), making it the centralized data store. The Streamlit app is hosted on an Amazon Elastic Cloud Compute (Amazon EC2) fronted with Elastic LoadBalancing (ELB), allowing Vitech to scale as traffic increases.
loadbalancing, application acceleration, security, application visibility, performance monitoring, service discovery and more. Consistent LoadBalancing for Multi-Cloud Environments. Partnership with Nvidia to offer virtualized GPUs : Either on-premise or as part of VMware Cloud on AWS.
These Prisma Cloud Saved Views improvements streamline collaboration, keeping your team aligned on key security metrics. This eliminates the need to individually toggle visibility for Shared Views. If needed, you can still toggle visibility off. This enhancement provides broader coverage for securing your AWS environment.
Can operations staff take care of complex issues like loadbalancing, business continuity, and failover, which the applications developers use through a set of well-designed abstractions? But that argument isn’t really convincing without metrics. That’s the challenge of platform engineering. Document that.
A distributed streaming platform combines reliable and scalable messaging, storage, and processing capabilities into a single, unified platform that unlocks use cases other technologies individually can’t. In the same way, messaging technologies don’t have storage, thus they cannot handle past data.
Monitoring is the act of taking the data and metrics that observability makes available and tracking them over time so that anomalies, errors, and downtime are noticeable immediately. By monitoring the metrics of running systems, developers can detect when these systems begin to deviate from normal behavior. What is monitoring?
Infrastructure-as-a-service (IaaS) is a category that offers traditional IT services like compute, database, storage, network, loadbalancers, firewalls, etc. Monitoring and logging: collect performance and availability metrics as well as automate incident management and log aggregation.
Docker, containerd ) and manages their lifecycle Pod: The smallest deployable unit in Kubernetes, representing one or more containers sharing the same network namespace and storage. Automated Scaling: It adjusts the number of running instances based on resource usage or custom metrics. Container Runtime: Executes containers (e.g.,
Docker, containerd ) and manages their lifecycle Pod: The smallest deployable unit in Kubernetes, representing one or more containers sharing the same network namespace and storage. Automated Scaling: It adjusts the number of running instances based on resource usage or custom metrics. Container Runtime: Executes containers (e.g.,
Let’s first review a few basic Kubernetes concepts: Pod: “A pod is the basic building block of Kubernetes,” which encapsulates containerized apps, storage, a unique network IP, and instructions on how to run those containers. A Refresh: Kubernetes Basics. Application developers usually assume that the network below layer 4 “just works.”
Conductor helps us achieve a high degree of service availability and data consistency across different storage backends. While this does add to data footprint but the benefits such as (a) allowing for lockless retries, (b) eliminating the need for resolving write conflicts and (c) mitigating data loss, far outweigh the storage costs.
Once the decommissioning process is finished, stop the Cassandra service on the node: Restart the Cassandra service on the remaining nodes in the cluster to ensure data redistribution and replication: LoadBalancing Cassandra employs a token-based partitioning strategy, where data is distributed across nodes based on a token value.
To do that, you’ll have to loadbalance Logstash, deploy multiple parallel data nodes in Elastic, install and run something like Apache Kafka to avoid data loss if your traffic is bursty…and this will all be your responsiblity. All storage nodes are unreachable from the internet.
We’ve previously shared our experience moving Kafka over to Arm instances once AWS offered Graviton2 instance types with on-instance storage (Is4gen and Im4gn), and the wins we saw there ( with help from Amazon ). We’re also very heavy users of AWS Lambda for our storage engine. Finishing the migration.
AWS provides a few native tools that can help you gather cost data and system metrics to identify cost-related inefficiencies in your setup: AWS Cost Explorer. Use the Trusted Advisor Idle LoadBalancers Check to get a report of loadbalancers that have a request count of less than 100 over the past seven days.
KeyValue is an abstraction over the storage engine itself, which allows us to choose the best storage engine that meets our SLO needs. The DeviceToDeviceManager is also responsible for observability, with metrics around cache hits, calls to the data store, message delivery rates, and latency percentile measurements.
To determine which partition is used for storage, the key is mapped into a key space. Classic microservice concerns such as service discovery, loadbalancing, online-offline or anything else are solved natively by event streaming platform protocol. Instrumentation plane tracking application-wide metrics.
Service Definition and Monitoring Administrators will be able to define a service or application as a collection of components (containers, virtual machines, databases, storage arrays, loadbalancers, etc.) There are the obvious cases, like unattached storage volumes that are still being paid for.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content