

Deploy Meta Llama 3.1-8B on AWS Inferentia using Amazon EKS and vLLM
AWS Machine Learning - AI
NOVEMBER 26, 2024
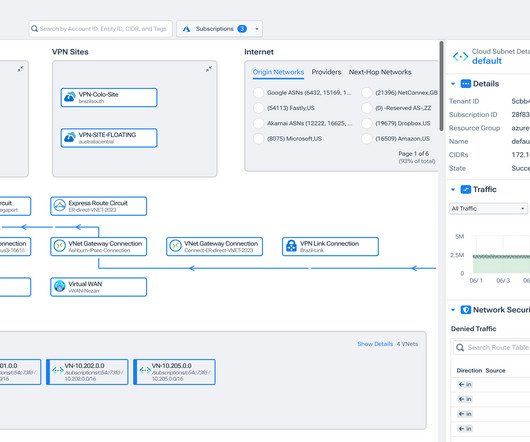
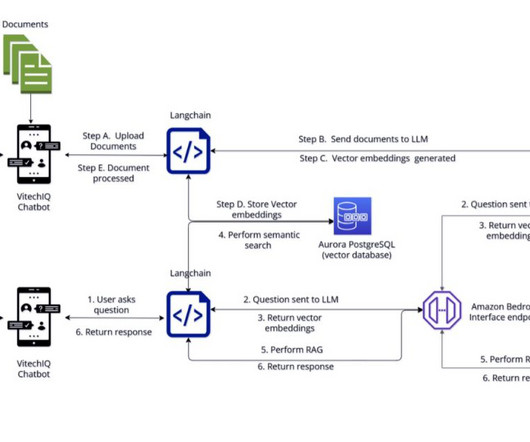
AWS Trainium and AWS Inferentia based instances, combined with Amazon Elastic Kubernetes Service (Amazon EKS), provide a performant and low cost framework to run LLMs efficiently in a containerized environment. We also demonstrate how to test the solution and monitor performance, and discuss options for scaling and multi-tenancy.











































Let's personalize your content