This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Region Evacuation with static anycast IP approach Welcome back to our comprehensive "Building Resilient Public Networking on AWS" blog series, where we delve into advanced networking strategies for regional evacuation, failover, and robust disaster recovery. subdomain-1.cloudns.ph",
Did you configure a networkloadbalancer for your secondary network interfaces ? How Passthrough NetworkLoadBalancers Work A passthrough NetworkLoadBalancer routes connections directly from clients to the healthy backends, without any interruption. metric 100.
There is a wide range of network topologies possible, so this might be seen as a barrier to decide how this can be accomplished. This triggered the idea to document a number of network topologies, starting with the most simple of the simple, working our way to more complex setups. Expanding on the most simple set up.
For example, if a company’s e-commerce website is taking too long to process customer transactions, a causal AI model determines the root cause (or causes) of the delay, such as a misconfigured loadbalancer. GenAI can even create working code. AI trained on biased data may produce unreliable results.
In part 1 of this series , I talked about the importance of network observability as our customers define it — using advances in data platforms and machine learning to supply answers to critical questions and enable teams to take critical action to keep application traffic flowing. Access and transit networks, edge and exchange points, CDNs.
As a result, traffic won’t be balanced across all replicas of your deployment. This is suitable for testing and development purposes, but it doesn’t utilize the deployment efficiently in a production scenario where loadbalancing across multiple replicas is crucial to handle higher traffic and provide fault tolerance.
When evaluating solutions, whether to internal problems or those of our customers, I like to keep the core metrics fairly simple: will this reduce costs, increase performance, or improve the network’s reliability? It’s often taken for granted by network specialists that there is a trade-off among these three facets. Resiliency.
Networking. Here you’ll see options like: Virtual Network – your network will be logically isolated from other networks in Azure. Overall you can imagine this like the network we have in our traditional data centers. So you can also access the other virtual machines in the same virtual network.
MoE models like DeepSeek-V3 and Mixtral replace the standard feed-forward neural network in transformers with a set of parallel sub-networks called experts. Additionally, SageMaker endpoints support automatic loadbalancing and autoscaling, enabling your LLM deployment to scale dynamically based on incoming requests.
For cloud network specialists, the landscape for their observability efforts includes a mix of physical and virtual networking devices. These devices generate signals (by design or through instrumentation) that provide critical information to those responsible for managing network health. What is network telemetry?
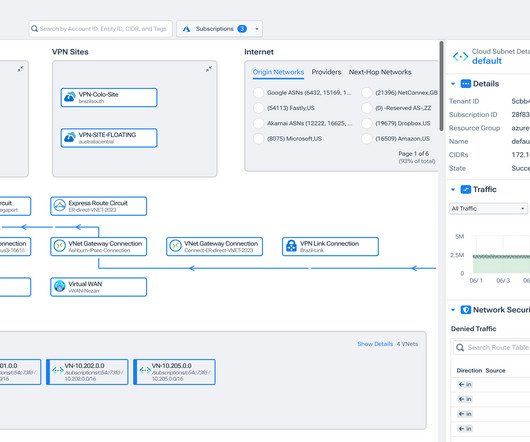
Kentik customers move workloads to (and from) multiple clouds, integrate existing hybrid applications with new cloud services, migrate to Virtual WAN to secure private network traffic, and make on-premises data and applications redundant to multiple clouds – or cloud data and applications redundant to the data center.
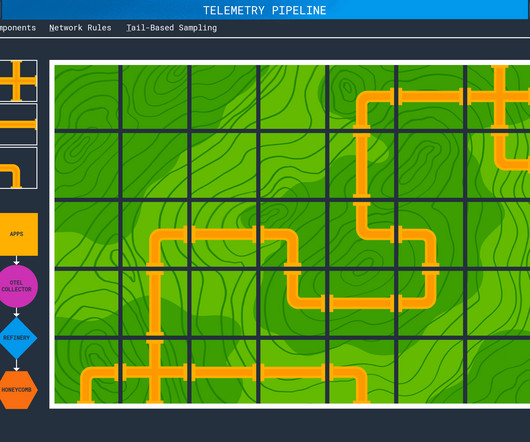
In a simple deployment, an application will emit spans, metrics, and logs which will be sent to api.honeycomb.io If your organization has more components, network rules, or requires tail-based sampling , you’ll need to create a telemetry pipeline. This also adds the blue lines, which denote metrics data. and show up in charts.
Most successful organizations base their goals on improving some or all of the DORA or Accelerate metrics. DORA metrics are used by DevOps teams to measure their performance and find out whether they are “low performers” to “elite performers.” You want to maximize your deployment frequency while minimizing the other metrics.
They’re normally more robust and reliable than single systems, but they have a more complex network architecture. However, you likely know how inconsistent even the best networks can be. You probably already use tools to monitor your network. You probably already use tools to monitor your network.
Understanding the network footprint of applications and services is now essential for delivering fast and reliable services in cloud-native environments. Networking is not evaporating into the cloud but instead has become a critical component that underpins every part of modern application architecture. A Refresh: Kubernetes Basics.
At scale, and primarily when carried out in cloud and hybrid-cloud environments, these distributed, service-oriented architectures and deployment strategies create a complexity that can buckle the most experienced network professionals when things go wrong, costs need to be explained, or optimizations need to be made.
If an application or system does not provide an interface to extract data, or other constraints like network connectivity prevent you from using a pull approach, a push strategy can be a good alternative. Which loadbalancer should you pick and how should it be configured? It also configures NiFi accordingly.
They must track key metrics, analyze user feedback, and evolve the platform to meet customer expectations. Measuring your success with key metrics A great variety of metrics helps your team measure product outcomes and pursue continuous growth strategies. It usually focuses on some testing scenarios that automation could miss.
Modern networks are made up of a collection of routers, switches, firewalls, and other network elements. From a high-level perspective, network operators engage in network capacity planning to understand some key networkmetrics: Types of network traffic. Capacity of current network infrastructure.
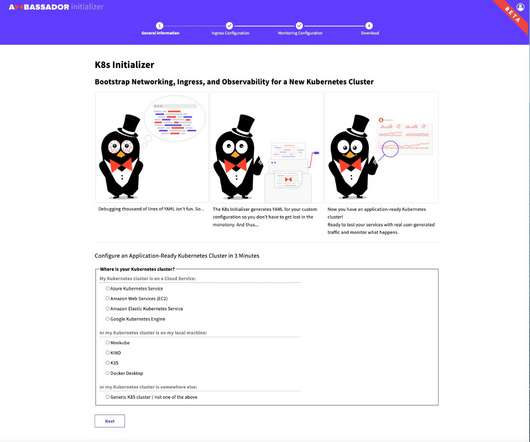
The K8s Initializer: Configure an application-ready Kubernetes cluster in 3 minutes Production-like Networking Challenges In order to illustrate some of the challenges with bootstrapping a cluster for development, let’s run through a couple of common scenarios. The K8s Initializer can help you do just this! Try it now !
What do network engineers working in the trenches, slinging packets, untangling coils of fiber, and spending too much time in the hot aisle really want from all their efforts? They want a rock-solid, reliable, stable network that doesn’t keep them awake at night and ensures great application performance. The answer is simple.
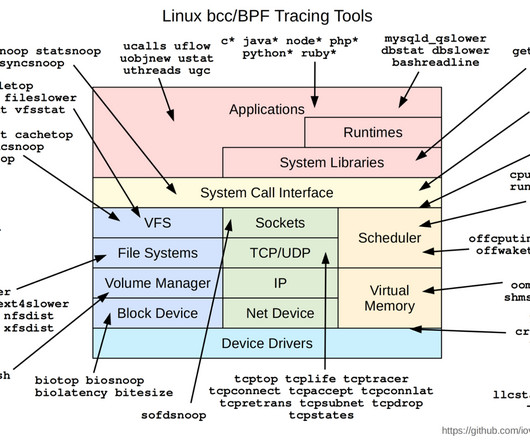
Those calls could be for kernel services, network services, accessing the file system, and so on. Therefore, by looking at the interactions between the application and the kernel, we can learn almost everything we want to know about application performance, including local network activity. How does eBPF work?
Introducing gnmi-gateway: a modular, distributed, and highly available service for modern network telemetry via OpenConfig and gNMI By: Colin McIntosh, Michael Costello Netflix runs its own content delivery network, Open Connect , which delivers all streaming traffic to our members.
Get the latest on the Hive RaaS threat; the importance of metrics and risk analysis; cloud security’s top threats; supply chain security advice for software buyers; and more! . But to truly map cybersecurity efforts to business objectives, you’ll need what CompTIA calls “an organizational risk approach to metrics.”.
Implement Elastic LoadBalancing Implementing elastic loadbalancing (ELB) is a crucial best practice for maximizing PeopleSoft performance on AWS. Implementing ELB for PeopleSoft workloads involves defining relevant health checks, load-balancing algorithms, and session management settings.
Decompose these into quantifiable KPIs to direct the project, utilizing metrics like migration duration, savings on costs, and enhancements in performance. Configure loadbalancers, establish auto-scaling policies, and perform tests to verify functionality. Localize your network and streamline traffic flows to minimize latency.
On May 27 of this year, Gartner Research Director Sanjit Ganguli released a research note titled “Network Performance Monitoring Tools Leave Gaps in Cloud Monitoring.” You’d put a few others — I emphasize “few” because these appliances were and are not cheap — at other major choke points in and out of the network.
But at some point it becomes impossible to add more processing power, bigger attached storage, faster networking, or additional memory. Partition tolerance — the system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes. One example is Kubernetes’ built-in loadbalancer.
While we’ve previously made public reference to the fact that Kentik has been working with A10 Networks, and today we are proud to formally announce both the partnership and our field-ready integration between Kentik Detect and the A10 Thunder TPS mitigation solution. A10 solutions help protect some of the world's largest networks.
As your traffic rises and falls, you can set up auto-scaling on a specific metric (e.g., Therefore, you can bring the number of containers up or down in response to fluctuations in the selected metric. Loadbalancer (EC2 feature) . Network mode would be by default awsvpc for ECS Fargate. Step 2: Configure network.
However, with the help of a Network Operations Center (NOC), you can streamline and simplify your IT operations dramatically. What is a Network Operations Center (NOC)? A NOC, pronounced like the word knock, is an internal or a third-party facility for monitoring and managing an organization’s networked devices and systems.
Flow-based network monitoring relies on collecting information about packet flows (i.e. a sequence of related packets) as they traverse routers, switches, loadbalancers, ADCs, network visibility switches, and other devices. Flow-based monitoring provides significant advantages over other network monitoring methods.
Acquisition announcement of Avi Networks : A multi-cloud application services platform that provides software for the delivery of enterprise applications in data centers and clouds—e.g., loadbalancing, application acceleration, security, application visibility, performance monitoring, service discovery and more.
This bursting is intentional and guided by state-of-the-art monitoring and metrics to know exactly which tiers of the application need to be scaled to maintain SLA’s (Service Level Agreements). Federating Metrics. Aggregating metrics from diverse nodes is feasible with tooling such as Prometheus. Machine Learning.
This technology promise to homogenise internal network communication between services and provide cross-cutting nonfunctional concerns such as observability and fault-tolerance. There was also limited visibility into infrastructure components such as hosted loadbalancers, caches and network topologies.
This technology promise to homogenise internal network communication between services and provide cross-cutting nonfunctional concerns such as observability and fault-tolerance. There was also limited visibility into infrastructure components such as hosted loadbalancers, caches and network topologies.
We deploy applications, and configure some networks that are internal to us, then connect those to the internet using the cloud provider’s gateways. The majority of things that would cause this to fire are better monitored via specific localized metrics (number of healthy instances in a loadbalancer) or SLOs to measure real user experience.
Consider deploying Informatica Nodes on a GRID for High Availability and LoadBalancing. Does the ETL System/Server has required H/W Capabilities? Optimize ETL Design by following the Best Practices. Monitor Storage Space and Computing Abilities.
Consul is quite flexible and the monitoring system has numerous metrics. We can even choose metrics for monitoring containers. . Another benefit of using Consul is that it can substitute other well known monitoring systems, such as Zabbix and Nagios. These features make Consul an ideal control panel for a service mesh solution.
That said, the only way to get that 50% cost reduction is to install the AWS CloudWatch Agent on your instances and configure it to send memory metrics to CloudWatch. If you are not running the agent…then no memory metrics. Hence – a potential 25% cost reduction. Memcached: +43% performance, at lower latency.
Elastic Beanstalk handles the provisioning of resources such as EC2 instances, loadbalancers, and databases, allowing developers to focus on their application’s code. The service auto-configures capacity provisioning, loadbalancing, scaling, and application health monitoring details.
If you are using the cloud, you can configure secure network connections though Virtual Private Clouds (VPCs). Availability ECE provides features such as automatic failover and loadbalancing, which can help ensure high availability and minimize downtime. You need to provide your own loadbalancing solution.
NANOG (North American Network Operators Group) time has arrived again. Network Performance Monitoring solution. A few weeks ago, Kentik announced the first network performance monitoring solution that is built for cloud and digital operations. It now ingests performance metrics like TCP retransmits and latency.
Sitefinity Cloud takes full advantage of all the available performance metrics and troubleshooting tools to keep your project in prime shape. There’s more than one way to get things right and fine-tuning is an art if you want loadbalancing, geo redundancy, autoscaling, backup and recovery to absolutely click.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content