This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
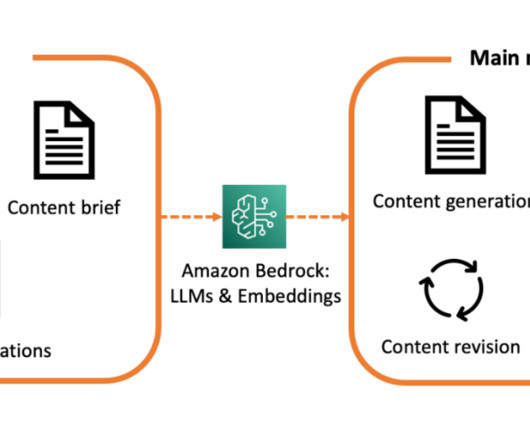
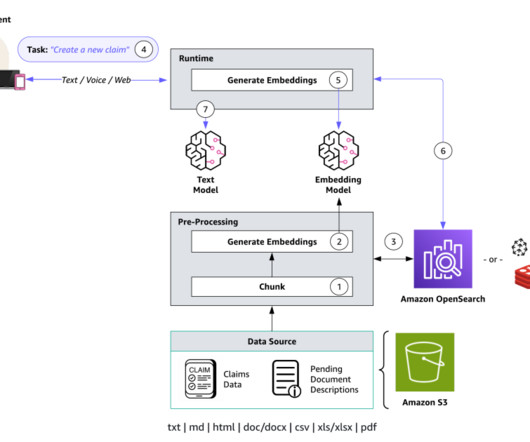
The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket. This allows the agent to provide context and general information about car parts and systems. Ingestion flow The ingestion flow prepares and stores the necessary data for the AI agent to access.
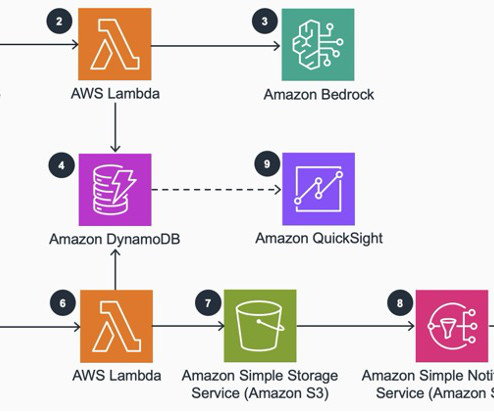
To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. This post guides you through implementing a queue management system that automatically monitors available job slots and submits new jobs as slots become available.
For instance, consider an AI-driven legal document analysis system designed for businesses of varying sizes, offering two primary subscription tiers: Basic and Pro. It also allows for a flexible and modular design, where new LLMs can be quickly plugged into or swapped out from a UI component without disrupting the overall system.
AWS Lambda is an event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers. You can invoke Lambda functions from over 200 AWS services and software-as-a-service (SaaS) applications.
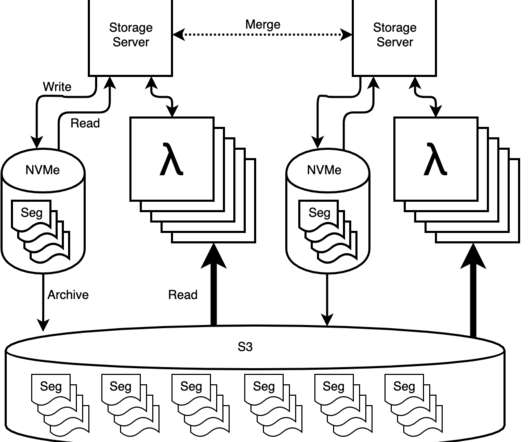
When we introduced Secondary Storage two years ago, it was a deliberate compromise between economy and performance. Compared to Honeycomb’s primary NVMe storage attached to dedicated servers, secondary storage let customers keep more data for less money. Enter AWS Lambda. Today things look very different.
Introduction With an ever-expanding digital universe, data storage has become a crucial aspect of every organization’s IT strategy. S3 Storage Undoubtedly, anyone who uses AWS will inevitably encounter S3, one of the platform’s most popular storage services. Storage Class Designed For Retrieval Change Min.
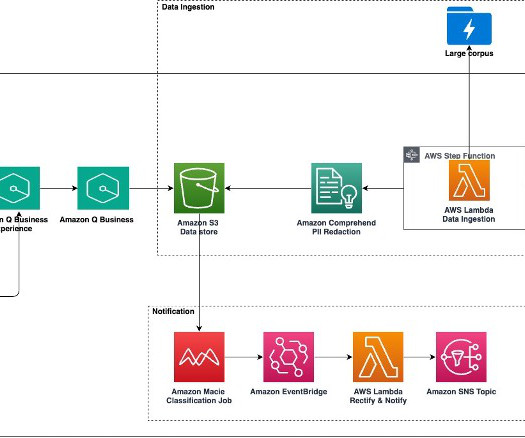
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Step Functions orchestrates AWS services like AWS Lambda and organization APIs like DataStore to ingest, process, and store data securely.
Solution overview This section outlines the architecture designed for an email support system using generative AI. High Level System Design The solution consists of the following components: Email service – This component manages incoming and outgoing customer emails, serving as the primary interface for email communications.
Audio-to-text translation The recorded audio is processed through an advanced speech recognition (ASR) system, which converts the audio into text transcripts. Data integration and reporting The extracted insights and recommendations are integrated into the relevant clinical trial management systems, EHRs, and reporting mechanisms.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. Alternatively, you can use AWS Lambda and implement your own logic, or use open source tools such as fmeval. The tenant management component is responsible for managing and administering these tenants within the system.
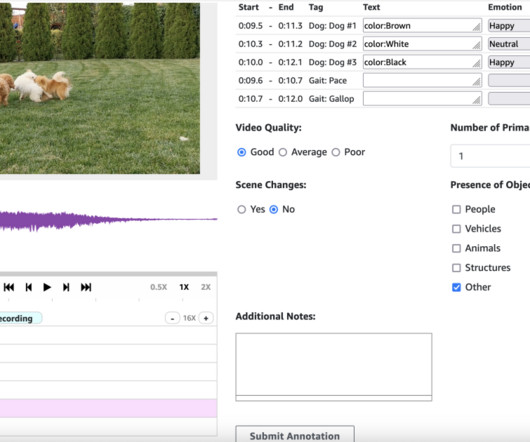
At its core, Amazon Simple Storage Service (Amazon S3) serves as the secure storage for input files, manifest files, annotation outputs, and the web UI components. Pre-annotation and post-annotation AWS Lambda functions are optional components that can enhance the workflow.
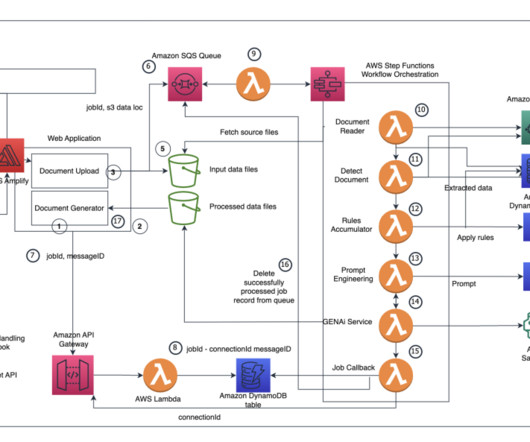
The solution consists of the following steps: Relevant documents are uploaded and stored in an Amazon Simple Storage Service (Amazon S3) bucket. The text extraction AWS Lambda function is invoked by the SQS queue, processing each queued file and using Amazon Textract to extract text from the documents.
As systems scale, conducting thorough AWS Well-Architected Framework Reviews (WAFRs) becomes even more crucial, offering deeper insights and strategic value to help organizations optimize their growing cloud environments. The WAFR reviewer, based on Lambda and AWS Step Functions , is activated by Amazon SQS.
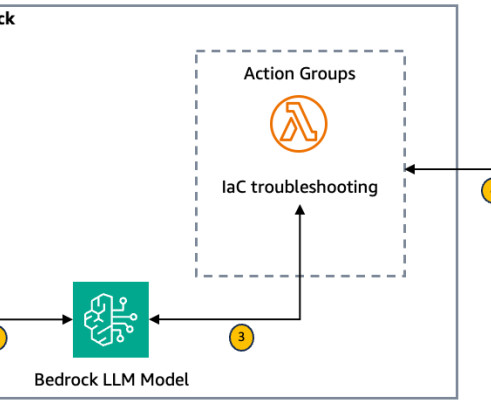
Error retrieval and context gathering The Amazon Bedrock agent forwards these details to an action group that invokes the first AWS Lambda function (see the following Lambda function code ). This contextual information is then sent back to the first Lambda function. Provide the troubleshooting steps to the user.
Observability refers to the ability to understand the internal state and behavior of a system by analyzing its outputs, logs, and metrics. The CloudFormation template provisions resources such as Amazon Data Firehose delivery streams, AWS Lambda functions, Amazon S3 buckets, and AWS Glue crawlers and databases.
With AWS generative AI services like Amazon Bedrock , developers can create systems that expertly manage and respond to user requests. An AI assistant is an intelligent system that understands natural language queries and interacts with various tools, data sources, and APIs to perform tasks or retrieve information on behalf of the user.
However, existing solutions can often fall into two categories: rule-based systems that demand substantial time and effort for setup and upkeep, or rigid systems that lack the flexibility required for human-like interactions with customers. This can be done with a Lambda layer or by using a specific AMI with the required libraries.
It enables you to privately customize the FM of your choice with your data using techniques such as fine-tuning, prompt engineering, and retrieval augmented generation (RAG) and build agents that run tasks using your enterprise systems and data sources while adhering to security and privacy requirements.
Storage: S3 for static content and RDS for a managed database. Leverage Pulumi Config & Secrets: Store sensitive values securely in Pulumis secret management system. Amazon S3 : Object storage for data, logs, and backups. AWS Lambda : Serverless computing service for event-driven applications. MySQL, PostgreSQL).
The system will take a few minutes to set up your project. This includes setting up Amazon API Gateway , AWS Lambda functions, and Amazon Athena to enable querying the structured sales data. Note that generative AI systems are nondeterministic, so responses will not be the same every time.
By extracting key data from testing reports, the system uses Amazon SageMaker JumpStart and other AWS AI services to generate CTDs in the proper format. The user-friendly system also employs encryption for security. The WebSocket triggers an AWS Lambda function, which creates a record in Amazon DynamoDB.
Scaling and State This is Part 9 of Learning Lambda, a tutorial series about engineering using AWS Lambda. So far in this series we’ve only been talking about processing a small number of events with Lambda, one after the other. Lambda will horizontally scale precisely when we need it to a massive extent.
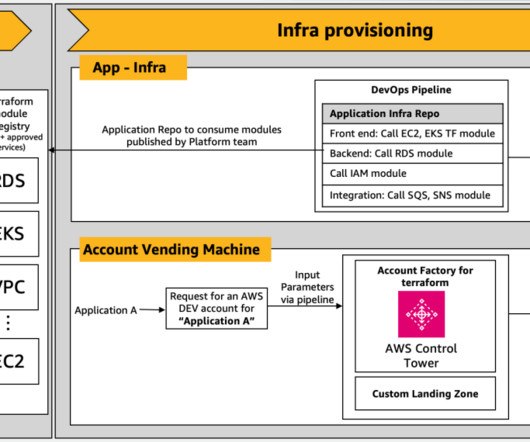
In parallel, the AVM layer invokes a Lambda function to generate Terraform code. Before deployment, the initial draft of the Terraform code is thoroughly reviewed by cloud engineers or an automated code review system to confirm that it meets all technical and compliance standards. Access to Amazon Bedrock models.
As the name suggests, a cloud service provider is essentially a third-party company that offers a cloud-based platform for application, infrastructure or storage services. In a public cloud, all of the hardware, software, networking and storage infrastructure is owned and managed by the cloud service provider. What Is a Public Cloud?
Get 1 GB of free storage. Try Render Vercel Earlier known as Zeit, the Vercel app acts as the top layer of AWS Lambda which will make running your applications easy. Their service provides the most sophisticated vision, language, speech, and AI models, hence you will be able to create your machine-learning system.
Key features of AWS Batch Efficient Resource Management: AWS Batch automatically provisions the required resources, such as compute instances and storage, based on job requirements. Integration with AWS Services: AWS Batch seamlessly integrates with other AWS services, such as Amazon S3, AWS Lambda, and Amazon DynamoDB.
If you’re studying for the AWS Cloud Practitioner exam, there are a few Amazon S3 (Simple Storage Service) facts that you should know and understand. Amazon S3 is an object storage service that is built to be scalable, high available, secure, and performant. What to know about S3 Storage Classes. Most expensive storage class.
Using Amazon Bedrock, you can easily experiment with and evaluate top FMs for your use case, privately customize them with your data using techniques such as fine-tuning and Retrieval Augmented Generation (RAG), and build agents that execute tasks using your enterprise systems and data sources.
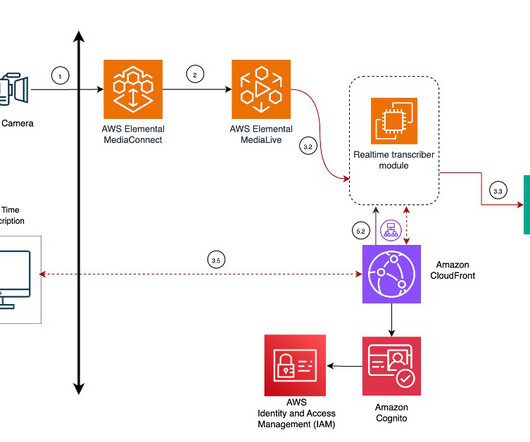
The absence of such a system hinders effective knowledge sharing and utilization, limiting the overall impact of events and workshops. Real-time transcription processing To facilitate real-time accessibility, the system uses MediaLive to isolate audio from the live video stream.
The system is built upon Amazon Bedrock and leverages LLM capabilities to generate curated medical content for disease awareness. For this reason, our system has been augmented with additional guardrails for fact-checking and rules evaluation. Amazon Lambda : to run the backend code, which encompasses the generative logic.
This pivotal decision has been instrumental in propelling them towards fulfilling their mission, ensuring their system operations are characterized by reliability, superior performance, and operational efficiency. The raw photos are stored in Amazon Simple Storage Service (Amazon S3). Data intake A user uploads photos into Mixbook.
The workflow consists of the following steps: A user uploads multiple images into an Amazon Simple Storage Service (Amazon S3) bucket via a Streamlit web application. The DynamoDB update triggers an AWS Lambda function, which starts a Step Functions workflow. The Step Functions workflow runs the following steps for each image: 5.1
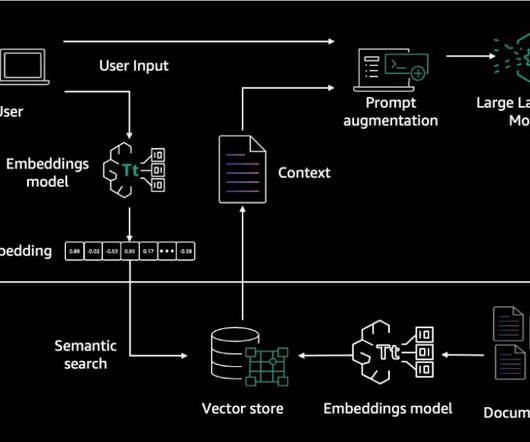
Parsing documents is important for RAG applications because it enables the system to understand the structure and context of the information contained within the documents. In the next section, we discuss custom processing using Lambda function provided by Knowledge bases for Amazon Bedrock.
The architecture carries out the following steps: Customer reviews can be imported into an Amazon Simple Storage Service (Amazon S3) bucket as JSON objects. This bucket will have event notifications enabled to invoke an AWS Lambda function to process the objects created or updated.
The performance characteristics of a distributed system such as Databricks will be different from those of a traditional relational database depending on the data characteristics and access patterns, but the impact on the business may not necessarily call for doing anything.
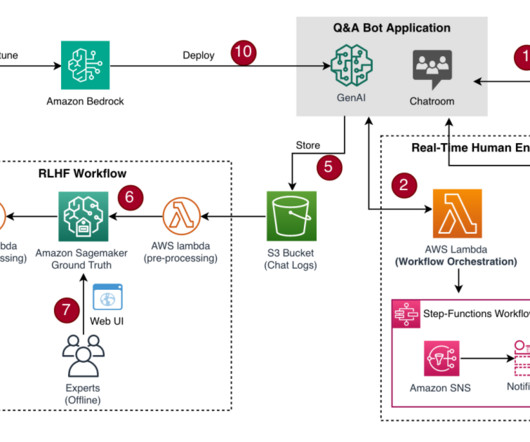
In this post, we introduce a solution for integrating a “near-real-time human workflow” where humans are prompted by the generative AI system to take action when a situation or issue arises. Pre-annotation Lambda function The process starts with an AWS Lambda function. Here, we use the on-demand option.
We’re big fans of AWS Lambda at Honeycomb. As you may have read , we recently made some major improvements to our storage engine by leveraging Lambda to process more data in less time. Making a change to a complex system like our storage engine is daunting, but can be made less so with good instrumentation and tracing.
With this practical book, you’ll learn how to plan and build systems to serve your organization’s and customers’ needs by evaluating the best technologies available through the framework of the data engineering lifecycle. That means the data engineering lifecycle comprises stages that turn raw data into a useful end product.
System integration – Agents make API calls to integrated company systems to run specific actions. Action groups are a set of APIs and corresponding business logic, whose OpenAPI schema is defined as JSON files stored in Amazon Simple Storage Service (Amazon S3). create-customer-resources.sh
Below is a review of the main announcements that impact compute, database, storage, networking, machine learning, and development. After several years of AWS users asking for it, this new EC2 instance allows Amazon Elastic Compute Cloud (EC2) to run macOS and all other Apple operating systems. Container Image Support in AWS Lambda.
Scaling and State This is Part 9 of Learning Lambda, a tutorial series about engineering using AWS Lambda. So far in this series we’ve only been talking about processing a small number of events with Lambda, one after the other. Lambda will horizontally scale precisely when we need it to a massive extent.
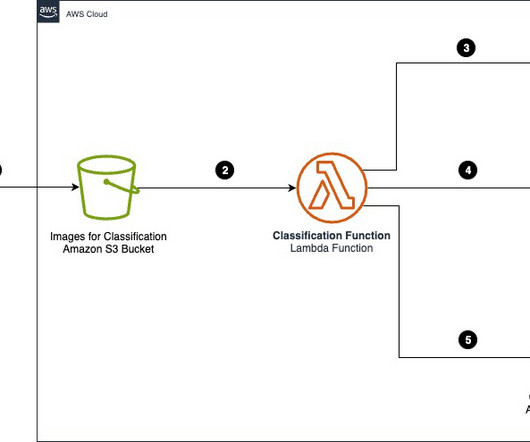
The system architecture comprises several core components: UI portal – This is the user interface (UI) designed for vendors to upload product images. AWS Lambda – AWS Lambda provides serverless compute for processing. Note that in this solution, all of the storage is in the UI. This could be any database of your choice.
One way to enable more contextual conversations is by linking the chatbot to internal knowledge bases and information systems. Managing these interdependent parts can introduce complexities in system development and deployment. You will use this Lambda layer code later to create the Lambda function.
Categorizing documents is an important first step in IDP systems. As new document templates and types emerge in business workflows, you can simply invoke the Amazon Bedrock API to dynamically vectorize them and append to their IDP systems to rapidly enhance document classification capabilities.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content