This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When running a Docker container on ECS Fargate, persistent storage is often a necessity. I initially attempted to solve this by manually creating the required directory on EFS using a Lambda-backed custom resource. A Lambda function could do this, so I started implementing a custom resource. How about a custom resource?
To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. We walk you through our solution, detailing the core logic of the Lambda functions. Amazon S3 invokes the {stack_name}-create-batch-queue-{AWS-Region} Lambda function.
Before processing the request, a Lambda authorizer function associated with the API Gateway authenticates the incoming message. After it’s authenticated, the request is forwarded to another Lambda function that contains our core application logic. The code runs in a Lambda function. Implement your business logic in this file.
The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket. The Lambda function runs the database query against the appropriate OpenSearch Service indexes, searching for exact matches or using fuzzy matching for partial information.
A crucial question that plagues cloud application developers is, “What kind of storage should we use for our app?” Unlike other choices like compute runtimes—Lambda/serverless, containers or virtual machines—data storage choice is highly sticky and makes future application improvements and migrations much harder.
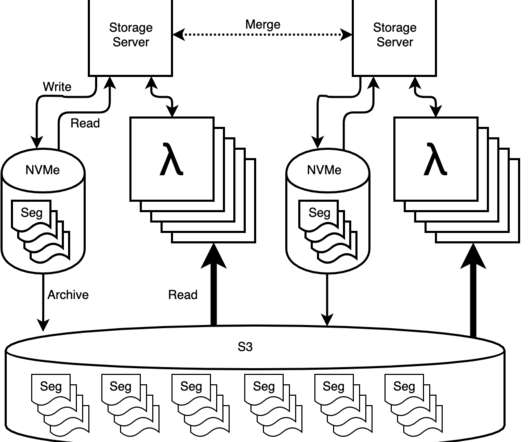
When we introduced Secondary Storage two years ago, it was a deliberate compromise between economy and performance. Compared to Honeycomb’s primary NVMe storage attached to dedicated servers, secondary storage let customers keep more data for less money. Enter AWS Lambda. Today things look very different.
AWS Lambda is an event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers. You can invoke Lambda functions from over 200 AWS services and software-as-a-service (SaaS) applications.
Introduction With an ever-expanding digital universe, data storage has become a crucial aspect of every organization’s IT strategy. S3 Storage Undoubtedly, anyone who uses AWS will inevitably encounter S3, one of the platform’s most popular storage services. Storage Class Designed For Retrieval Change Min.
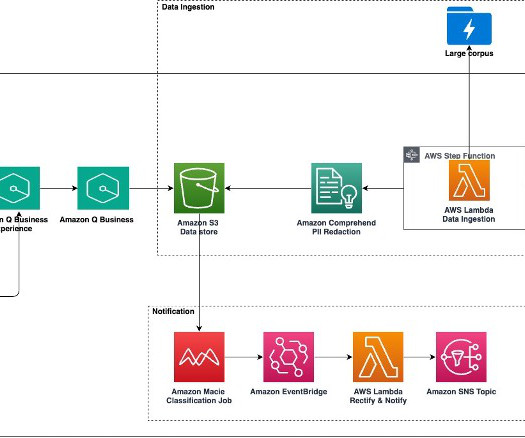
The Amazon Q Business pre-built connectors like Amazon Simple Storage Service (Amazon S3), document retrievers, and upload capabilities streamlined data ingestion and processing, enabling the team to provide swift, accurate responses to both basic and advanced customer queries.
The solution also uses Amazon Cognito user pools and identity pools for managing authentication and authorization of users, Amazon API Gateway REST APIs, AWS Lambda functions, and an Amazon Simple Storage Service (Amazon S3) bucket. To launch the solution in a different Region, change the aws_region parameter accordingly.
AWS Elastic Compute Cloud (EC2), Elastic Container Service (ECS), Amazon Lambda, and AWS Simple Storage Service (Amazon S3) are some of the most critical services you should become familiar with. There are over 200 fully-featured services within the Amazon Web Services (AWS) ecosystem.
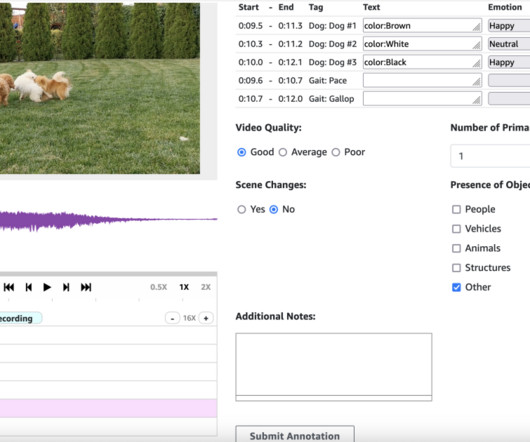
At its core, Amazon Simple Storage Service (Amazon S3) serves as the secure storage for input files, manifest files, annotation outputs, and the web UI components. Pre-annotation and post-annotation AWS Lambda functions are optional components that can enhance the workflow. On the SageMaker console, choose Create labeling job.
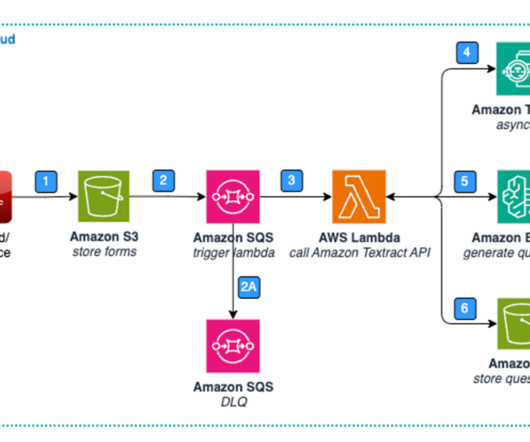
The solution consists of the following steps: Relevant documents are uploaded and stored in an Amazon Simple Storage Service (Amazon S3) bucket. The text extraction AWS Lambda function is invoked by the SQS queue, processing each queued file and using Amazon Textract to extract text from the documents.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. Alternatively, you can use AWS Lambda and implement your own logic, or use open source tools such as fmeval. For example, in one common scenario with Cognito that accesses resources with API Gateway and Lambda with a user pool.
Data consolidation The transcribed patient reports are consolidated into a structured database, enabling efficient storage, retrieval, and analysis. Copying these sample files will trigger an S3 event invoking the AWS Lambda function audio-to-text. On the Lambda console, navigate to the function named hcls_clinical_trial_analysis.
An email handler AWS Lambda function is invoked by WorkMail upon the receipt of an email, and acts as the intermediary that receives requests and passes it to the appropriate agent. The system indexes documents and files stored in Amazon Simple Storage Service (Amazon S3) using Amazon OpenSearch Service for quick retrieval.
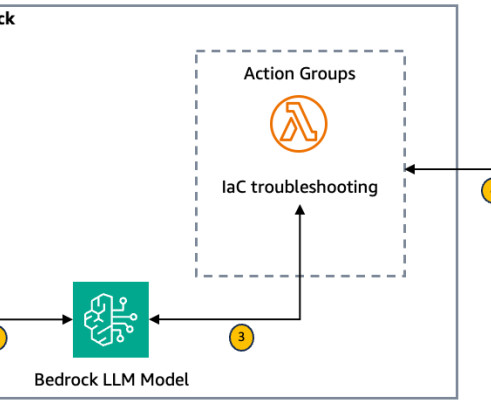
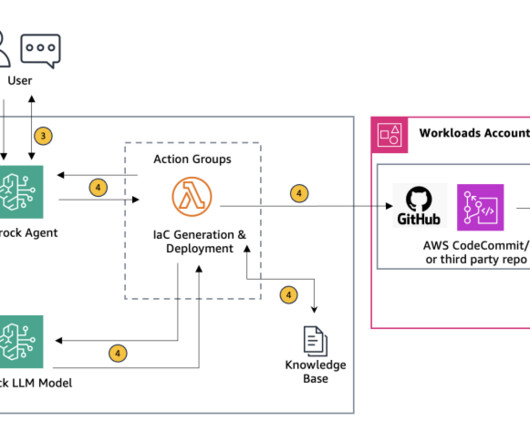
Error retrieval and context gathering The Amazon Bedrock agent forwards these details to an action group that invokes the first AWS Lambda function (see the following Lambda function code ). This contextual information is then sent back to the first Lambda function. Provide the troubleshooting steps to the user.
Flexible logging –You can use this solution to store logs either locally or in Amazon Simple Storage Service (Amazon S3) using Amazon Data Firehose, enabling integration with existing monitoring infrastructure. Additionally, you can choose what gets logged. We encourage you to explore this solution and integrate it into your workflows.
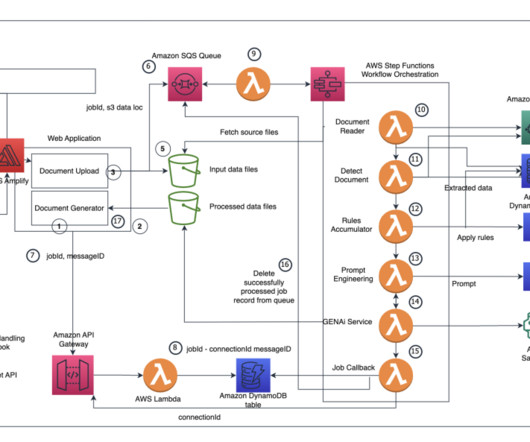
Part 1: Standard forms: Data extraction and storage The following diagram highlights the key elements of a solution for data extraction and storage with standard forms. Figure 1: Architecture – Standard Form – Data Extraction & Storage. Lastly, the Lambda function stores the question list in Amazon S3.
The Lambda function spins up an Amazon Bedrock batch processing endpoint and passes the S3 file location. The second Lambda function performs the following tasks: It monitors the batch processing job on Amazon Bedrock. Amazon Bedrock batch processes this single JSONL file, where each row contains input parameters and prompts.
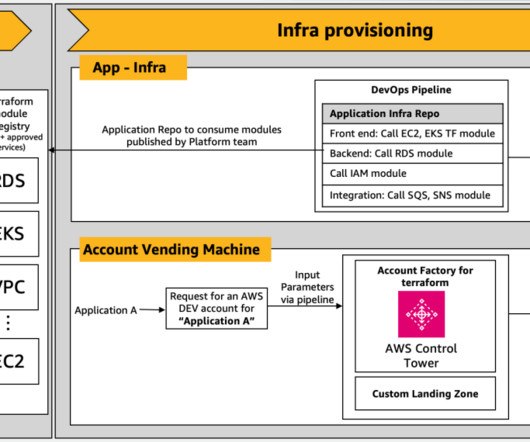
In parallel, the AVM layer invokes a Lambda function to generate Terraform code. The reviewed and updated Terraform scripts are then used to deploy infrastructure components into the newly provisioned AWS account, setting up compute, storage, and networking resources required for the application. Access to Amazon Bedrock models.
Currently, AWS offers over 200 cloud services, including cloud hosting, storage, machine learning, and container management. In 2006, Amazon launched its cloud services platform, Amazon Web Services (AWS) , one of the leading cloud providers to date.
In this post, we show you how to build a speech-capable order processing agent using Amazon Lex, Amazon Bedrock, and AWS Lambda. A Lambda function pulls the appropriate prompt template from the Lambda layer and formats model prompts by adding the customer input in the associated prompt template. awscli>=1.29.57
When API Gateway receives the request, it triggers an AWS Lambda The Lambda function sends the question to the classifier LLM to determine whether it is a history or math question. These embeddings are then saved as a reference index inside an in-memory FAISS vector store, which is deployed as a Lambda layer.
Figure 1 : High level overview of creating Infrastructure as Code from architecture diagram Initial Input through the Amazon Bedrock chat console : The user begins by entering the name of their Amazon Simple Storage Service (Amazon S3) bucket and the object (key) name where the architecture diagram is stored into the Amazon Bedrock chat console.
One such service is their serverless computing service , AWS Lambda. For the uninitiated, Lambda is an event-driven serverless computing platform that lets you run code without managing or provisioning servers and involves zero administration. How does AWS Lambda Work. Why use AWS Lambda? Read on to know. zip or jar.
Scaling and State This is Part 9 of Learning Lambda, a tutorial series about engineering using AWS Lambda. So far in this series we’ve only been talking about processing a small number of events with Lambda, one after the other. Lambda will horizontally scale precisely when we need it to a massive extent.
Scalable architecture Uses AWS services like AWS Lambda and Amazon Simple Queue Service (Amazon SQS) for efficient processing of multiple reviews. The workflow consists of the following steps: WAFR guidance documents are uploaded to a bucket in Amazon Simple Storage Service (Amazon S3).
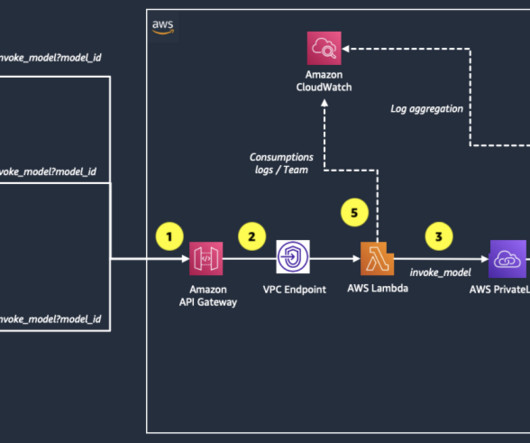
API Gateway routes the request to an AWS Lambda function ( bedrock_invoke_model ) that’s responsible for logging team usage information in Amazon CloudWatch and invoking the Amazon Bedrock model. The workflow steps are as follows: An Amazon EventBridge rule triggers a Lambda function ( bedrock_cost_tracking ) daily.
After being in cloud and leveraging it better, we are able to manage compute and storage better ourselves,” said the CIO, who notes that vendors are not cutting costs on licenses or capacity but are offering more guidance and tools. He went with cloud provider Wasabi for those storage needs. “We
Storage: S3 for static content and RDS for a managed database. Amazon S3 : Object storage for data, logs, and backups. AWS Lambda : Serverless computing service for event-driven applications. Networking: A secure VPC with private and public subnets. Security: IAM roles, Security Groups, and encryption best practices.
This is done using ReAct prompting, which breaks down the task into a series of steps that are processed sequentially: For device metrics checks, we use the check-device-metrics action group, which involves an API call to Lambda functions that then query Amazon Athena for the requested data. It serves as the data source to the knowledge base.
In this blog post, you will learn how to build a Serverless speech-to-text conversion solution using Amazon Transcribe , AWS Lambda , and the Go programming language.
In this blog post, you will learn how to build a Serverless solution to process images using Amazon Rekognition , AWS Lambda and the Go programming language.
If an image is uploaded, it is stored in Amazon Simple Storage Service (Amazon S3) , and a custom AWS Lambda function will use a machine learning model deployed on Amazon SageMaker to analyze the image to extract a list of place names and the similarity score of each place name.
In this post, we demonstrate a few metrics for online LLM monitoring and their respective architecture for scale using AWS services such as Amazon CloudWatch and AWS Lambda. Amazon Bedrock saves the request and completion (response) in Amazon Simple Storage Service (Amazon S3) as the per configuration of invocation logging.
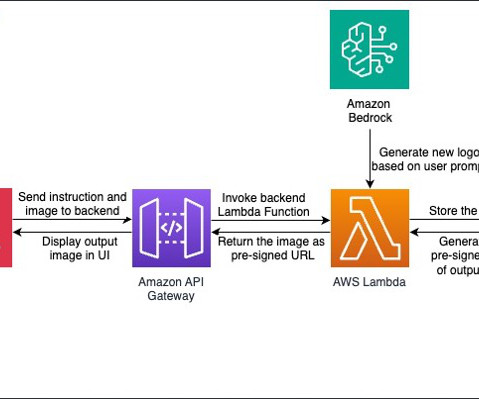
Integrating it with the range of AWS serverless computing, networking, and content delivery services like AWS Lambda , Amazon API Gateway , and AWS Amplify facilitates the creation of an interactive tool to generate dynamic, responsive, and adaptive logos. This API will be used to invoke the Lambda function.
In this blog post, you will learn how to build a Serverless solution for entity detection using Amazon Comprehend , AWS Lambda , and the Go programming language. Text files uploaded to Amazon Simple Storage Service (S3) will trigger a Lambda function which will further analyze it, extract entity metadata (name, type, etc.)
The application uses the Amplify libraries for Amazon Simple Storage Service (Amazon S3) and uploads documents provided by users to Amazon S3. The WebSocket triggers an AWS Lambda function, which creates a record in Amazon DynamoDB. Another Lambda function gets triggered with a new message in the SQS queue.
For example, traditional data structures in relational databases started to move forward to a new approach that enables to storage and retrieval of key-value and document data structures using NoSQL databases.
The architecture carries out the following steps: Customer reviews can be imported into an Amazon Simple Storage Service (Amazon S3) bucket as JSON objects. This bucket will have event notifications enabled to invoke an AWS Lambda function to process the objects created or updated.
If you’re studying for the AWS Cloud Practitioner exam, there are a few Amazon S3 (Simple Storage Service) facts that you should know and understand. Amazon S3 is an object storage service that is built to be scalable, high available, secure, and performant. What to know about S3 Storage Classes. Most expensive storage class.
The workflow consists of the following steps: A user uploads multiple images into an Amazon Simple Storage Service (Amazon S3) bucket via a Streamlit web application. The DynamoDB update triggers an AWS Lambda function, which starts a Step Functions workflow. The Step Functions workflow runs the following steps for each image: 5.1
Now that you understand the concepts for semantic and hierarchical chunking, in case you want to have more flexibility, you can use a Lambda function for adding custom processing logic to chunks such as metadata processing or defining your custom logic for chunking. Make sure to create the Lambda layer for the specific open source framework.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content