This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. We walk you through our solution, detailing the core logic of the Lambda functions. Amazon S3 invokes the {stack_name}-create-batch-queue-{AWS-Region} Lambda function.
Before processing the request, a Lambda authorizer function associated with the API Gateway authenticates the incoming message. After it’s authenticated, the request is forwarded to another Lambda function that contains our core application logic. The code runs in a Lambda function. Implement your business logic in this file.
Amazon DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability. AWS Lambda is an event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers.
The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket. The Lambda function runs the database query against the appropriate OpenSearch Service indexes, searching for exact matches or using fuzzy matching for partial information.
Semantic routing offers several advantages, such as efficiency gained through fast similarity search in vector databases, and scalability to accommodate a large number of task categories and downstream LLMs. These embeddings are then saved as a reference index inside an in-memory FAISS vector store, which is deployed as a Lambda layer.
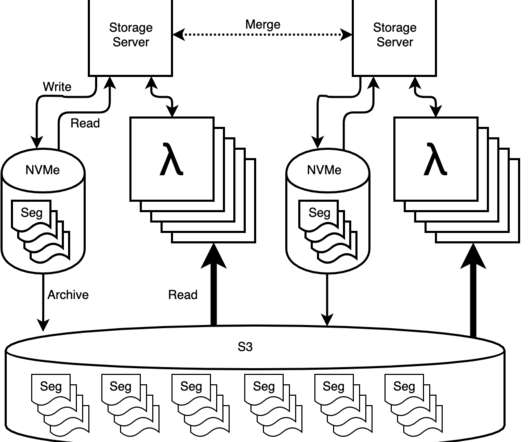
When we introduced Secondary Storage two years ago, it was a deliberate compromise between economy and performance. Compared to Honeycomb’s primary NVMe storage attached to dedicated servers, secondary storage let customers keep more data for less money. Enter AWS Lambda. Today things look very different.
The solution consists of the following steps: Relevant documents are uploaded and stored in an Amazon Simple Storage Service (Amazon S3) bucket. The text extraction AWS Lambda function is invoked by the SQS queue, processing each queued file and using Amazon Textract to extract text from the documents.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. Alternatively, you can use AWS Lambda and implement your own logic, or use open source tools such as fmeval. For example, in one common scenario with Cognito that accesses resources with API Gateway and Lambda with a user pool.
Introduction With an ever-expanding digital universe, data storage has become a crucial aspect of every organization’s IT strategy. S3 Storage Undoubtedly, anyone who uses AWS will inevitably encounter S3, one of the platform’s most popular storage services. Storage Class Designed For Retrieval Change Min.
At its core, Amazon Simple Storage Service (Amazon S3) serves as the secure storage for input files, manifest files, annotation outputs, and the web UI components. Pre-annotation and post-annotation AWS Lambda functions are optional components that can enhance the workflow. On the SageMaker console, choose Create labeling job.
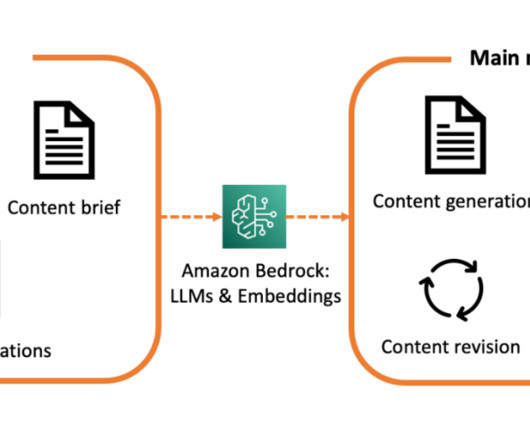
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. This scalability allows for more frequent and comprehensive reviews.
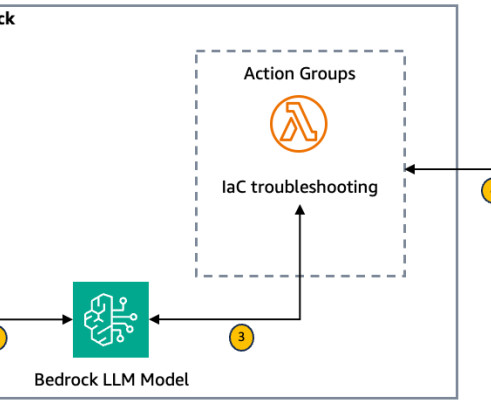
Error retrieval and context gathering The Amazon Bedrock agent forwards these details to an action group that invokes the first AWS Lambda function (see the following Lambda function code ). This contextual information is then sent back to the first Lambda function.
Flexible logging –You can use this solution to store logs either locally or in Amazon Simple Storage Service (Amazon S3) using Amazon Data Firehose, enabling integration with existing monitoring infrastructure. Additionally, you can choose what gets logged. We encourage you to explore this solution and integrate it into your workflows.
Designed with a serverless, cost-optimized architecture, the platform provisions SageMaker endpoints dynamically, providing efficient resource utilization while maintaining scalability. Multiple specialized Amazon Simple Storage Service Buckets (Amazon S3 Bucket) store different types of outputs.
The map functionality in Step Functions uses arrays to execute multiple tasks concurrently, significantly improving performance and scalability for workflows that involve repetitive operations. Furthermore, our solutions are designed to be scalable, ensuring that they can grow alongside your business.
Today, most organizations prefer to host applications and services on the cloud due to ease of deployment, high security, scalability, and cheap maintenance costs over on-premise infrastructure. Currently, AWS offers over 200 cloud services, including cloud hosting, storage, machine learning, and container management.
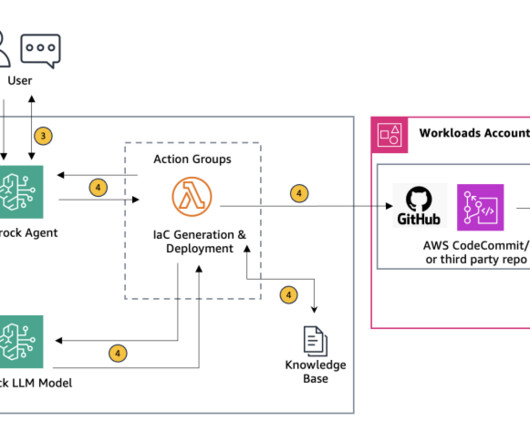
Figure 1 : High level overview of creating Infrastructure as Code from architecture diagram Initial Input through the Amazon Bedrock chat console : The user begins by entering the name of their Amazon Simple Storage Service (Amazon S3) bucket and the object (key) name where the architecture diagram is stored into the Amazon Bedrock chat console.
This innovative service goes beyond traditional trip planning methods, offering real-time interaction through a chat-based interface and maintaining scalability, reliability, and data security through AWS native services. Architecture The following figure shows the architecture of the solution.
In this post, we show you how to build a speech-capable order processing agent using Amazon Lex, Amazon Bedrock, and AWS Lambda. A Lambda function pulls the appropriate prompt template from the Lambda layer and formats model prompts by adding the customer input in the associated prompt template. awscli>=1.29.57
However, these tools may not be suitable for more complex data or situations requiring scalability and robust business logic. In short, Booster is a Low-Code TypeScript framework that allows you to quickly and easily create a backend application in the cloud that is highly efficient, scalable, and reliable. WTF is Booster?
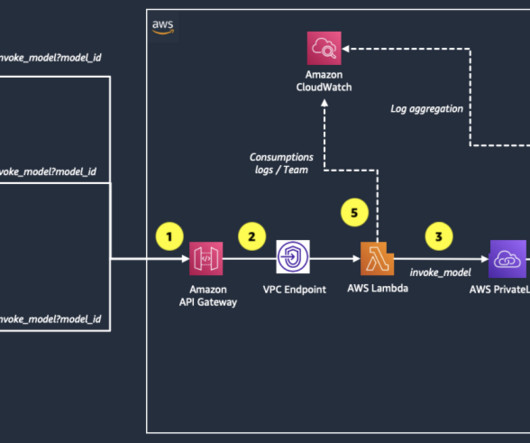
API Gateway routes the request to an AWS Lambda function ( bedrock_invoke_model ) that’s responsible for logging team usage information in Amazon CloudWatch and invoking the Amazon Bedrock model. The workflow steps are as follows: An Amazon EventBridge rule triggers a Lambda function ( bedrock_cost_tracking ) daily.
Our proposed architecture provides a scalable and customizable solution for online LLM monitoring, enabling teams to tailor your monitoring solution to your specific use cases and requirements. The file saved on Amazon S3 creates an event that triggers a Lambda function. The function invokes the modules.
This was not only about rewriting applications, but the backend data stores were also redesigned in terms of dynamic scalability , high performance, and flexibility for event-driven architecture.
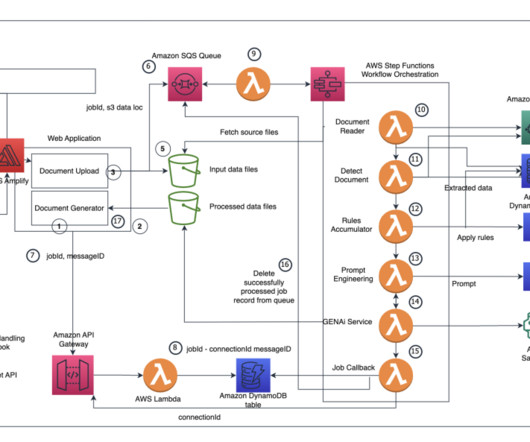
The application uses the Amplify libraries for Amazon Simple Storage Service (Amazon S3) and uploads documents provided by users to Amazon S3. The WebSocket triggers an AWS Lambda function, which creates a record in Amazon DynamoDB. Another Lambda function gets triggered with a new message in the SQS queue.
One such service is their serverless computing service , AWS Lambda. For the uninitiated, Lambda is an event-driven serverless computing platform that lets you run code without managing or provisioning servers and involves zero administration. How does AWS Lambda Work. Why use AWS Lambda? Read on to know. zip or jar.
They provide a strategic advantage for developers and organizations by simplifying infrastructure management, enhancing scalability, improving security, and reducing undifferentiated heavy lifting. For direct device actions like start, stop, or reboot, we use the action-on-device action group, which invokes a Lambda function.
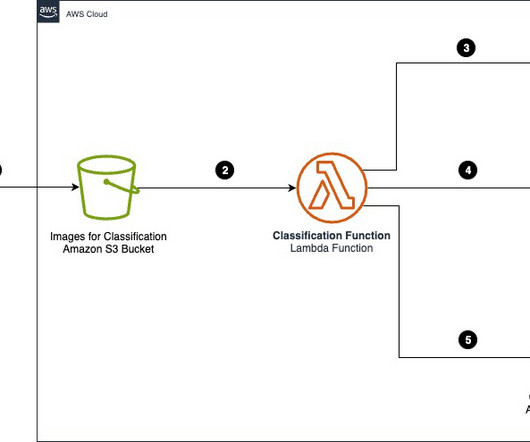
The workflow consists of the following steps: A user uploads multiple images into an Amazon Simple Storage Service (Amazon S3) bucket via a Streamlit web application. The DynamoDB update triggers an AWS Lambda function, which starts a Step Functions workflow. The Step Functions workflow runs the following steps for each image: 5.1
As the name suggests, a cloud service provider is essentially a third-party company that offers a cloud-based platform for application, infrastructure or storage services. In a public cloud, all of the hardware, software, networking and storage infrastructure is owned and managed by the cloud service provider. What Is a Public Cloud?
Get 1 GB of free storage. Try Render Vercel Earlier known as Zeit, the Vercel app acts as the top layer of AWS Lambda which will make running your applications easy. It offers the most intuitive user interface & scalability choices. Features: Simple deployment with just one click. Auto Scaling for traffic surges.
The storage layer uses Amazon Simple Storage Service (Amazon S3) to hold the invoices that business users upload. You can trigger the processing of these invoices using the AWS CLI or automate the process with an Amazon EventBridge rule or AWS Lambda trigger. Importantly, your document and data are not stored after processing.
Solution overview The policy documents reside in Amazon Simple Storage Service (Amazon S3) storage. This action invokes an AWS Lambda function to retrieve the document embeddings from the OpenSearch Service database and present them to Anthropics Claude 3 Sonnet FM, which is accessed through Amazon Bedrock.
The goal is to deploy a highly available, scalable, and secure architecture with: Compute: EC2 instances with Auto Scaling and an Elastic Load Balancer. Storage: S3 for static content and RDS for a managed database. Amazon S3 : Object storage for data, logs, and backups. Networking: A secure VPC with private and public subnets.
The raw photos are stored in Amazon Simple Storage Service (Amazon S3). Aurora MySQL serves as the primary relational data storage solution for tracking and recording media file upload sessions and their accompanying metadata. S3, in turn, provides efficient, scalable, and secure storage for the media file objects themselves.
If you’re studying for the AWS Cloud Practitioner exam, there are a few Amazon S3 (Simple Storage Service) facts that you should know and understand. Amazon S3 is an object storage service that is built to be scalable, high available, secure, and performant. What to know about S3 Storage Classes. 99.99% object durability.
The Asure team was manually analyzing thousands of call transcripts to uncover themes and trends, a process that lacked scalability. Staying ahead in this competitive landscape demands agile, scalable, and intelligent solutions that can adapt to changing demands.
However, when building a scalable review analysis solution, businesses can achieve the most value by automating the review analysis workflow. The architecture carries out the following steps: Customer reviews can be imported into an Amazon Simple Storage Service (Amazon S3) bucket as JSON objects.
It provides a powerful and scalable platform for executing large-scale batch jobs with minimal setup and management overhead. Key features of AWS Batch Efficient Resource Management: AWS Batch automatically provisions the required resources, such as compute instances and storage, based on job requirements.
Now that you understand the concepts for semantic and hierarchical chunking, in case you want to have more flexibility, you can use a Lambda function for adding custom processing logic to chunks such as metadata processing or defining your custom logic for chunking. Make sure to create the Lambda layer for the specific open source framework.
This includes setting up Amazon API Gateway , AWS Lambda functions, and Amazon Athena to enable querying the structured sales data. He collaborates with Independent Software Vendors (ISVs) in the Northeast region, assisting them in designing and building scalable and modern platforms on the AWS Cloud.
Below is a review of the main announcements that impact compute, database, storage, networking, machine learning, and development. We empower ourselves to monitor and test these new service releases and seek ways to help our clients become more successful through improved security, scalability, resiliency, and cost-optimization.
Scalability and reusability : Promote scalability and reusability across different AWS migration projects. Additionally, modular design facilitates scalability by allowing users to scale the migration operation up or down based on workload demands. Create and associate a Lambda function to handle the action’s logic.
Amazon Lambda : to run the backend code, which encompasses the generative logic. Amazon Simple Storage Service (S3) : for documents and processed data caching. In step 3, the frontend sends the HTTPS request via the WebSocket API and API gateway and triggers the first Amazon Lambda function.
The authors divide the data engineer lifecycle into five stages: Generation Storage Ingestion Transformation Serving Data The field is moving up the value chain, incorporating traditional enterprise practices like data management and cost optimization and new practices like DataOps. Architect for scalability. Plan for failure.
The following architecture diagram illustrates how you can use the Amazon Titan Multimodal Embeddings model with documents in an Amazon Simple Storage Service (Amazon S3) bucket for image gallery creation. An Amazon S3 object notification event invokes the embedding AWS Lambda function.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content