This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When running a Docker container on ECS Fargate, persistent storage is often a necessity. I initially attempted to solve this by manually creating the required directory on EFS using a Lambda-backed custom resource. How about a custom resource? A Lambda function could do this, so I started implementing a custom resource.
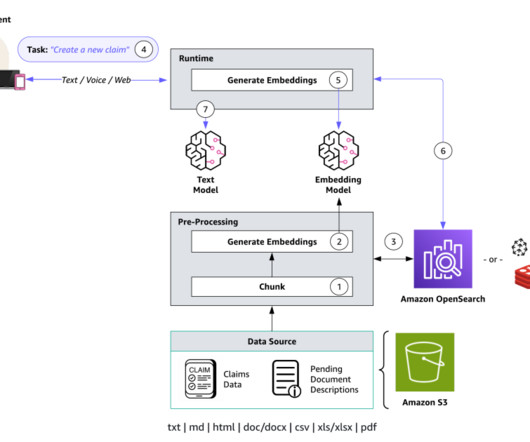
To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. We walk you through our solution, detailing the core logic of the Lambda functions. Amazon S3 invokes the {stack_name}-create-batch-queue-{AWS-Region} Lambda function.
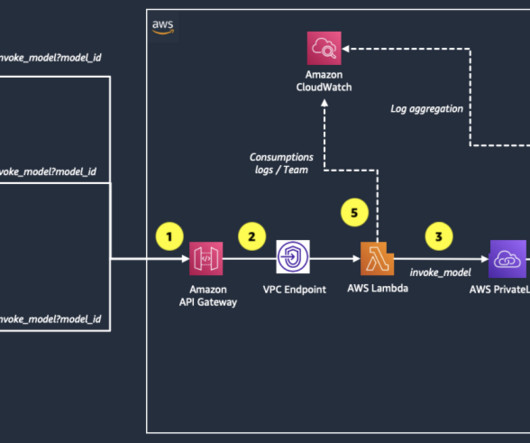
Before processing the request, a Lambda authorizer function associated with the API Gateway authenticates the incoming message. After it’s authenticated, the request is forwarded to another Lambda function that contains our core application logic. This request contains the user’s message and relevant metadata.
The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket. The Lambda function runs the database query against the appropriate OpenSearch Service indexes, searching for exact matches or using fuzzy matching for partial information.
The solution also uses Amazon Cognito user pools and identity pools for managing authentication and authorization of users, Amazon API Gateway REST APIs, AWS Lambda functions, and an Amazon Simple Storage Service (Amazon S3) bucket. The summary is stored inside an S3 bucket, which can be emptied using the extension’s Clean Up feature.
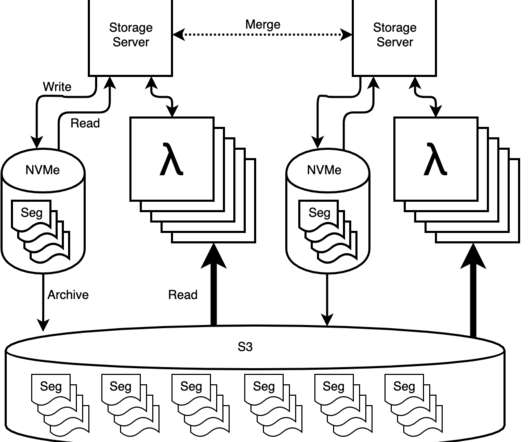
When we introduced Secondary Storage two years ago, it was a deliberate compromise between economy and performance. Compared to Honeycomb’s primary NVMe storage attached to dedicated servers, secondary storage let customers keep more data for less money. Enter AWS Lambda. Today things look very different.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. Depending on the use case and data isolation requirements, tenants can have a pooled knowledge base or a siloed one and implement item-level isolation or resource level isolation for the data respectively.
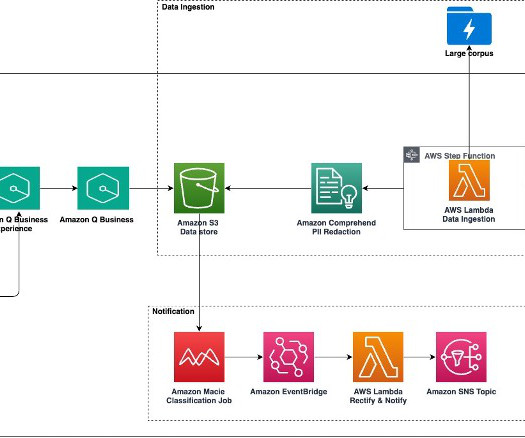
The Amazon Q Business pre-built connectors like Amazon Simple Storage Service (Amazon S3), document retrievers, and upload capabilities streamlined data ingestion and processing, enabling the team to provide swift, accurate responses to both basic and advanced customer queries.
Introduction With an ever-expanding digital universe, data storage has become a crucial aspect of every organization’s IT strategy. S3 Storage Undoubtedly, anyone who uses AWS will inevitably encounter S3, one of the platform’s most popular storage services. Storage Class Designed For Retrieval Change Min.
Time-consuming and resource-intensive The process required dedicating significant time and resources to review the submissions manually and follow up with institutions to request additional information if needed to rectify the submissions, resulting in slowing down the overall review process.
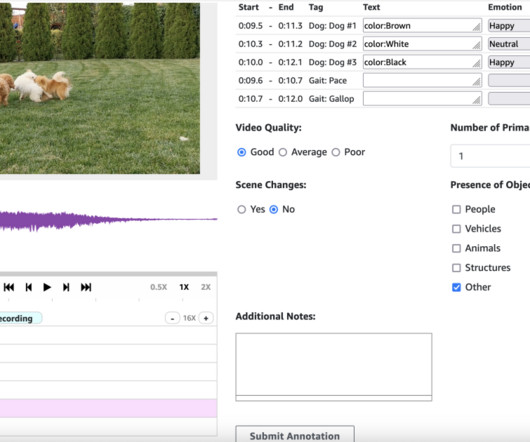
At its core, Amazon Simple Storage Service (Amazon S3) serves as the secure storage for input files, manifest files, annotation outputs, and the web UI components. Pre-annotation and post-annotation AWS Lambda functions are optional components that can enhance the workflow.
The solution offers the following potential benefits: Efficiency By automating the initial protocol design process, researchers can save valuable time and resources, allowing them to focus on more critical aspects of clinical trial execution. The audio is converted into text, providing accurate and verbatim transcripts.
The AI engine accesses this resource to pull relevant information needed to effectively address customer inquiries. An email handler AWS Lambda function is invoked by WorkMail upon the receipt of an email, and acts as the intermediary that receives requests and passes it to the appropriate agent.
Flexible logging –You can use this solution to store logs either locally or in Amazon Simple Storage Service (Amazon S3) using Amazon Data Firehose, enabling integration with existing monitoring infrastructure. Additionally, you can choose what gets logged. We encourage you to explore this solution and integrate it into your workflows.
This solution offers the following key benefits: Rapid analysis and resource optimization What previously took days of manual review can now be accomplished in minutes, allowing for faster iteration and improvement of architectures. The WAFR reviewer, based on Lambda and AWS Step Functions , is activated by Amazon SQS.
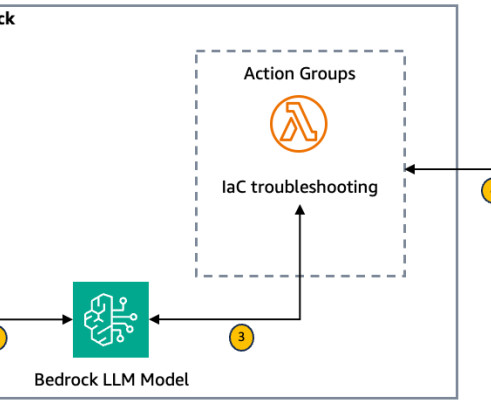
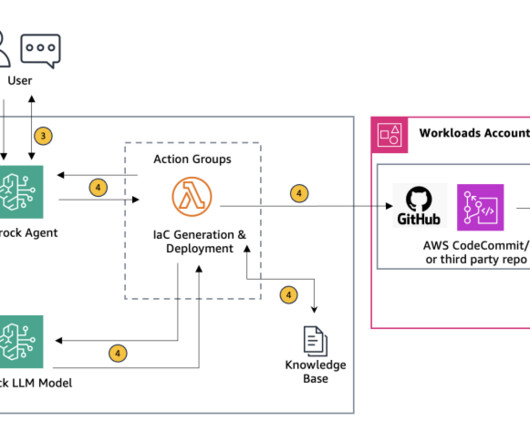
Troubleshooting infrastructure as code (IaC) errors often consumes valuable time and resources. Error retrieval and context gathering The Amazon Bedrock agent forwards these details to an action group that invokes the first AWS Lambda function (see the following Lambda function code ).
Workflow Overview Write Infrastructure Code (Python) Pulumi Translates Code to AWS Resources Apply Changes (pulumi up) Pulumi Tracks State for Future Updates Prerequisites Pulumi Dashboard The Pulumi Dashboard (if using Pulumi Cloud) helps track: The current state of infrastructure. Amazon S3 : Object storage for data, logs, and backups.
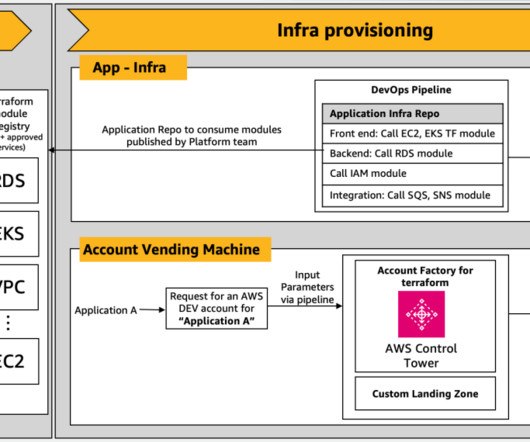
Migrating to the cloud is an essential step for modern organizations aiming to capitalize on the flexibility and scale of cloud resources. AWS Landing Zone addresses this need by offering a standardized approach to deploying AWS resources. In parallel, the AVM layer invokes a Lambda function to generate Terraform code.
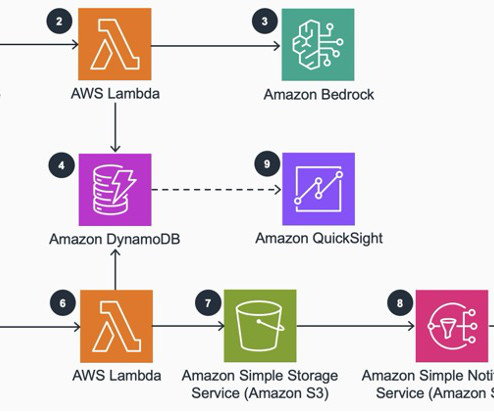
AWS CDK is an open source software development framework to model and provision your cloud application resources using familiar programming languages. The workflow steps are as follows: An Amazon EventBridge rule triggers a Lambda function ( bedrock_cost_tracking ) daily. The AWS CDK code is available in the GitHub repository.
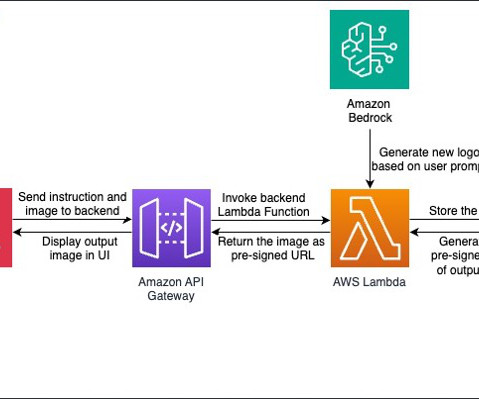
Integrating it with the range of AWS serverless computing, networking, and content delivery services like AWS Lambda , Amazon API Gateway , and AWS Amplify facilitates the creation of an interactive tool to generate dynamic, responsive, and adaptive logos. This API will be used to invoke the Lambda function.
In this post, we show you how to build a speech-capable order processing agent using Amazon Lex, Amazon Bedrock, and AWS Lambda. A Lambda function pulls the appropriate prompt template from the Lambda layer and formats model prompts by adding the customer input in the associated prompt template. awscli>=1.29.57
Our most-used AWS resources will help you stay on track in your journey to learn and apply AWS. We dove into the data on our online learning platform to identify the most-used Amazon Web Services (AWS) resources. Continue reading 10 top AWS resources on O’Reilly’s online learning platform.
Such a virtual assistant should support users across various business functions, such as finance, legal, human resources, and operations. When API Gateway receives the request, it triggers an AWS Lambda The Lambda function sends the question to the classifier LLM to determine whether it is a history or math question.
After being in cloud and leveraging it better, we are able to manage compute and storage better ourselves,” said the CIO, who notes that vendors are not cutting costs on licenses or capacity but are offering more guidance and tools. He went with cloud provider Wasabi for those storage needs. “We
With common compute resources most (serial) computing challenges can be solved. Resources are available on-demand, no ordering/waiting time for the deployment of resources. It dynamically scales resources up and down, ensuring optimal utilization and cost-efficiency. Reduced ongoing costs.
Figure 1 : High level overview of creating Infrastructure as Code from architecture diagram Initial Input through the Amazon Bedrock chat console : The user begins by entering the name of their Amazon Simple Storage Service (Amazon S3) bucket and the object (key) name where the architecture diagram is stored into the Amazon Bedrock chat console.
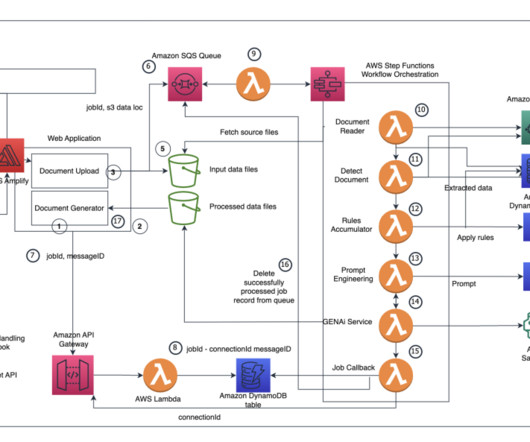
The workflow consists of the following steps: A user uploads multiple images into an Amazon Simple Storage Service (Amazon S3) bucket via a Streamlit web application. The DynamoDB update triggers an AWS Lambda function, which starts a Step Functions workflow. The Step Functions workflow runs the following steps for each image: 5.1
One such service is their serverless computing service , AWS Lambda. For the uninitiated, Lambda is an event-driven serverless computing platform that lets you run code without managing or provisioning servers and involves zero administration. How does AWS Lambda Work. Why use AWS Lambda? Read on to know. zip or jar.
Scaling and State This is Part 9 of Learning Lambda, a tutorial series about engineering using AWS Lambda. So far in this series we’ve only been talking about processing a small number of events with Lambda, one after the other. Lambda will horizontally scale precisely when we need it to a massive extent.
This significantly reduces the burden on human resources and allows employees to focus on more strategic and creative tasks. The code and resources required for deployment are available in the amazon-bedrock-examples repository. The schema allows the agent to reason around the function of each API.
If you’re studying for the AWS Cloud Practitioner exam, there are a few Amazon S3 (Simple Storage Service) facts that you should know and understand. Amazon S3 is an object storage service that is built to be scalable, high available, secure, and performant. What to know about S3 Storage Classes. Most expensive storage class.
Get 1 GB of free storage. Try Render Vercel Earlier known as Zeit, the Vercel app acts as the top layer of AWS Lambda which will make running your applications easy. Also, you will pay only for the resources you are going to use. Features: Simple deployment with just one click. Auto Scaling for traffic surges.
Inline mapping is efficient for lightweight tasks and helps avoid launching multiple Step Functions executions, which can be more costly and resource intensive. The results of each iteration are collected and made available for subsequent steps in the state machine. But there are limitations.
The process is often resource intensive, requiring a significant amount of time and human effort while still being prone to human errors and delays in identifying key insights, recurring themes, and improvement opportunities. The Lambda function runs the business logic to process the customer reviews within the input JSON file.
As the name suggests, a cloud service provider is essentially a third-party company that offers a cloud-based platform for application, infrastructure or storage services. In a public cloud, all of the hardware, software, networking and storage infrastructure is owned and managed by the cloud service provider.
The application uses the Amplify libraries for Amazon Simple Storage Service (Amazon S3) and uploads documents provided by users to Amazon S3. The WebSocket triggers an AWS Lambda function, which creates a record in Amazon DynamoDB. Another Lambda function gets triggered with a new message in the SQS queue.
The storage layer uses Amazon Simple Storage Service (Amazon S3) to hold the invoices that business users upload. You can trigger the processing of these invoices using the AWS CLI or automate the process with an Amazon EventBridge rule or AWS Lambda trigger. Importantly, your document and data are not stored after processing.
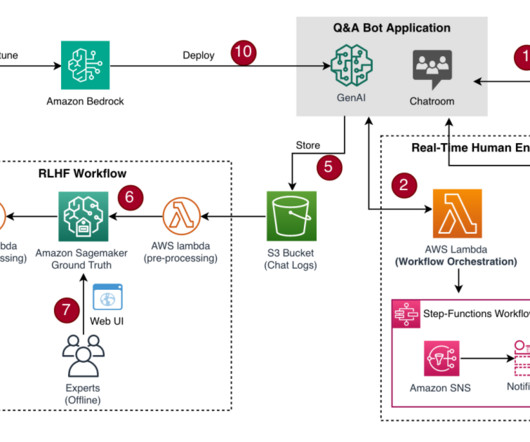
Build an offline human feedback workflow In this scenario, we assume that the chat transcripts are stored in an Amazon Simple Storage Service (Amazon S3) bucket in JSON format, a typical chat transcript format, for the human experts to provide annotations and labels on each LLM response. Here, we use the on-demand option.
We’re big fans of AWS Lambda at Honeycomb. As you may have read , we recently made some major improvements to our storage engine by leveraging Lambda to process more data in less time. Making a change to a complex system like our storage engine is daunting, but can be made less so with good instrumentation and tracing.
Most teams experience fluctuations in their resource demands throughout the workday, and maintaining unused compute capacity can result in unnecessary costs. If your application needs access to internal databases or sensitive resources for proper testing, you can deploy it to self-hosted runners behind your firewall.
Now that you understand the concepts for semantic and hierarchical chunking, in case you want to have more flexibility, you can use a Lambda function for adding custom processing logic to chunks such as metadata processing or defining your custom logic for chunking. Make sure to create the Lambda layer for the specific open source framework.
In addition, metadata filtering requires fewer computation resources, thereby improving the overall performance and reducing costs associated with the search. The app uses a single sign-on (SSO) functionality that allows them to access company-wide resources and other services and follows a company’s data level access protocol.
Solution overview The entire infrastructure of the solution is provisioned using the AWS Cloud Development Kit (AWS CDK), which is an infrastructure as code (IaC) framework to programmatically define and deploy AWS resources. Transcripts are then stored in the project’s S3 bucket under /transcriptions/TranscribeOutput/. AWS CDK version 2.0
Amazon Lex then invokes an AWS Lambda handler for user intent fulfillment. The Lambda function associated with the Amazon Lex chatbot contains the logic and business rules required to process the user’s intent. You may prefer to use a GitHub app to access resources on behalf of an organization or for long-lived integrations.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content