This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
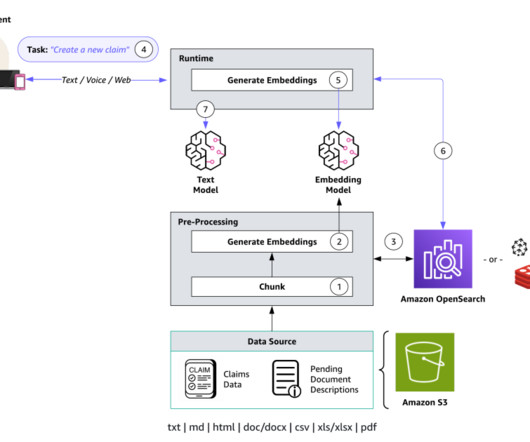
Refer to Supported Regions and models for batch inference for current supporting AWS Regions and models. To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. We walk you through our solution, detailing the core logic of the Lambda functions.
Before processing the request, a Lambda authorizer function associated with the API Gateway authenticates the incoming message. After it’s authenticated, the request is forwarded to another Lambda function that contains our core application logic. This request contains the user’s message and relevant metadata.
The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket. The Lambda function runs the database query against the appropriate OpenSearch Service indexes, searching for exact matches or using fuzzy matching for partial information.
If you’re studying for the AWS Cloud Practitioner exam, there are a few Amazon S3 (Simple Storage Service) facts that you should know and understand. Amazon S3 is an object storage service that is built to be scalable, high available, secure, and performant. What to know about S3 Storage Classes. Most expensive storage class.
The solution also uses Amazon Cognito user pools and identity pools for managing authentication and authorization of users, Amazon API Gateway REST APIs, AWS Lambda functions, and an Amazon Simple Storage Service (Amazon S3) bucket. For additional details, refer to Creating a new user in the AWS Management Console.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. Shared components refer to the functionality and features shared by all tenants. Refer to Perform AI prompt-chaining with Amazon Bedrock for more details. Generative AI gateway Shared components lie in this part.
At its core, Amazon Simple Storage Service (Amazon S3) serves as the secure storage for input files, manifest files, annotation outputs, and the web UI components. Pre-annotation and post-annotation AWS Lambda functions are optional components that can enhance the workflow. On the SageMaker console, choose Create labeling job.
Introduction With an ever-expanding digital universe, data storage has become a crucial aspect of every organization’s IT strategy. S3 Storage Undoubtedly, anyone who uses AWS will inevitably encounter S3, one of the platform’s most popular storage services. Storage Class Designed For Retrieval Change Min.
The Amazon Q Business pre-built connectors like Amazon Simple Storage Service (Amazon S3), document retrievers, and upload capabilities streamlined data ingestion and processing, enabling the team to provide swift, accurate responses to both basic and advanced customer queries.
An email handler AWS Lambda function is invoked by WorkMail upon the receipt of an email, and acts as the intermediary that receives requests and passes it to the appropriate agent. The system indexes documents and files stored in Amazon Simple Storage Service (Amazon S3) using Amazon OpenSearch Service for quick retrieval.
Observability refers to the ability to understand the internal state and behavior of a system by analyzing its outputs, logs, and metrics. For a detailed breakdown of the features and implementation specifics, refer to the comprehensive documentation in the GitHub repository. Additionally, you can choose what gets logged.
Handling large volumes of data, extracting unstructured data from multiple paper forms or images, and comparing it with the standard or reference forms can be a long and arduous process, prone to errors and inefficiencies. Figure 1: Architecture – Standard Form – Data Extraction & Storage.
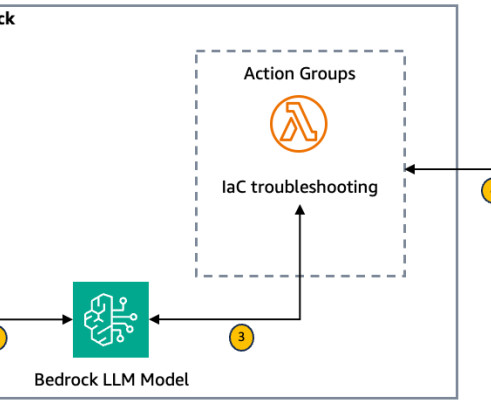
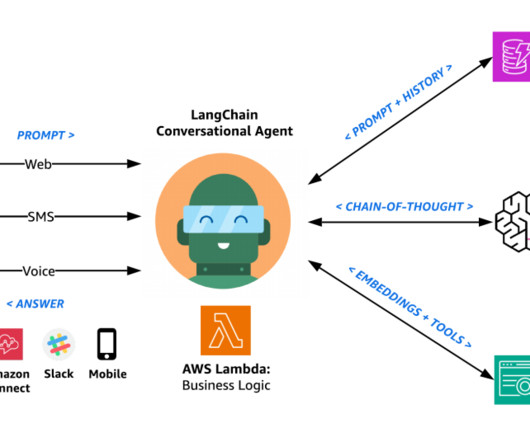
Error retrieval and context gathering The Amazon Bedrock agent forwards these details to an action group that invokes the first AWS Lambda function (see the following Lambda function code ). This contextual information is then sent back to the first Lambda function. Provide the troubleshooting steps to the user.
Scalable architecture Uses AWS services like AWS Lambda and Amazon Simple Queue Service (Amazon SQS) for efficient processing of multiple reviews. The workflow consists of the following steps: WAFR guidance documents are uploaded to a bucket in Amazon Simple Storage Service (Amazon S3).
The Lambda function spins up an Amazon Bedrock batch processing endpoint and passes the S3 file location. The second Lambda function performs the following tasks: It monitors the batch processing job on Amazon Bedrock. For detailed information, refer to the Security Best Practices section of this post.
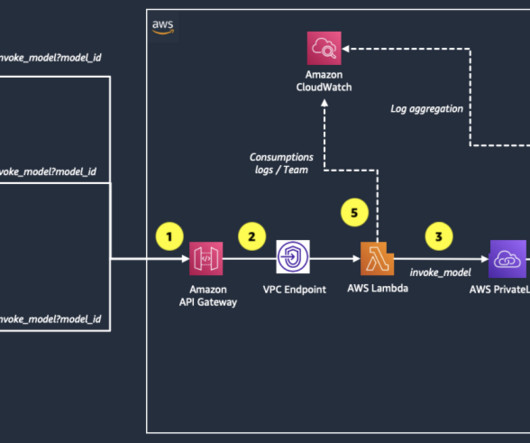
API Gateway routes the request to an AWS Lambda function ( bedrock_invoke_model ) that’s responsible for logging team usage information in Amazon CloudWatch and invoking the Amazon Bedrock model. The workflow steps are as follows: An Amazon EventBridge rule triggers a Lambda function ( bedrock_cost_tracking ) daily.
In this post, we demonstrate a few metrics for online LLM monitoring and their respective architecture for scale using AWS services such as Amazon CloudWatch and AWS Lambda. Amazon Bedrock saves the request and completion (response) in Amazon Simple Storage Service (Amazon S3) as the per configuration of invocation logging.
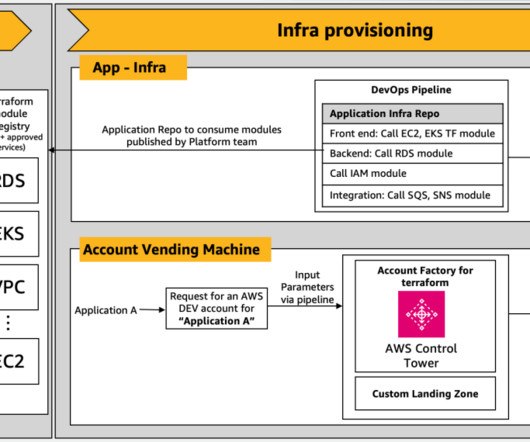
In this post, we refer to these solutions collectively as the AVM layer. In parallel, the AVM layer invokes a Lambda function to generate Terraform code. Solution overview The AWS Landing Zone deployment uses a Lambda function for generating Terraform scripts from architectural inputs. Access to Amazon Bedrock models.
“Awareness of FinOps practices and the maturity of software that can automate cloud optimization activities have helped enterprises get a better understanding of key cost drivers,” McCarthy says, referring to the practice of blending finance and cloud operations to optimize cloud spend.
Instead of handling all items within a single execution, Step Functions launches a separate execution for each item in the array, letting you concurrently process large-scale data sources stored in Amazon Simple Storage Service (Amazon S3), such as a single JSON or CSV file containing large amounts of data, or even a large set of Amazon S3 objects.
The following reference architecture illustrates what an automated review analysis solution could look like. The architecture carries out the following steps: Customer reviews can be imported into an Amazon Simple Storage Service (Amazon S3) bucket as JSON objects. Review Lambda quotas and function timeout to create batches.
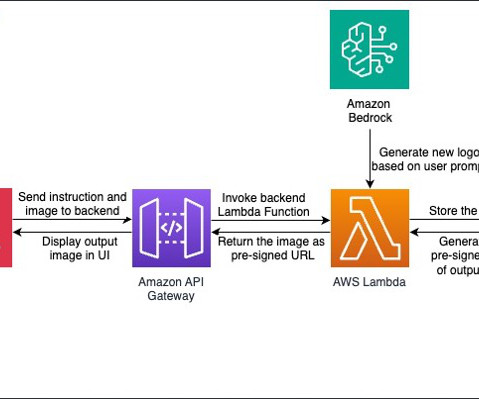
Integrating it with the range of AWS serverless computing, networking, and content delivery services like AWS Lambda , Amazon API Gateway , and AWS Amplify facilitates the creation of an interactive tool to generate dynamic, responsive, and adaptive logos. This API will be used to invoke the Lambda function.
Scaling and State This is Part 9 of Learning Lambda, a tutorial series about engineering using AWS Lambda. So far in this series we’ve only been talking about processing a small number of events with Lambda, one after the other. Lambda will horizontally scale precisely when we need it to a massive extent.
In this post, we show you how to build a speech-capable order processing agent using Amazon Lex, Amazon Bedrock, and AWS Lambda. A Lambda function pulls the appropriate prompt template from the Lambda layer and formats model prompts by adding the customer input in the associated prompt template. awscli>=1.29.57
Amazon Lambda : to run the backend code, which encompasses the generative logic. Amazon Simple Storage Service (S3) : for documents and processed data caching. Amazon Simple Storage Service (S3) : for documents and processed data caching. It sends it back to the WebSocket via the Lambda function.
The storage layer uses Amazon Simple Storage Service (Amazon S3) to hold the invoices that business users upload. If you’re new to Amazon EC2, refer to the Amazon EC2 User Guide. You can trigger the processing of these invoices using the AWS CLI or automate the process with an Amazon EventBridge rule or AWS Lambda trigger.
Ground truth data in AI refers to data that is known to be factual, representing the expected use case outcome for the system being modeled. Document Section Targeting - Reference specific sections when the information location is relevant - Example: "In Section [X] of [Document Name], what are the steps for [specific process]?"
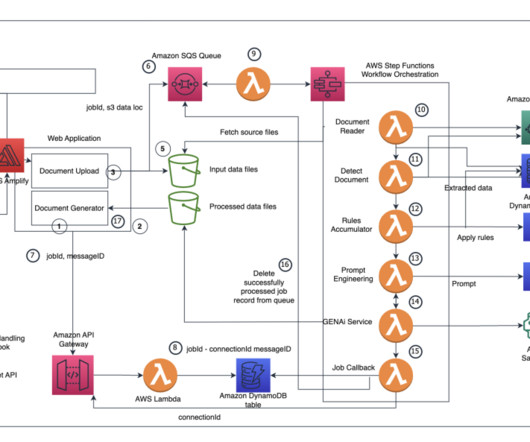
The application uses the Amplify libraries for Amazon Simple Storage Service (Amazon S3) and uploads documents provided by users to Amazon S3. The WebSocket triggers an AWS Lambda function, which creates a record in Amazon DynamoDB. Another Lambda function gets triggered with a new message in the SQS queue.
The workflow consists of the following steps: A user uploads multiple images into an Amazon Simple Storage Service (Amazon S3) bucket via a Streamlit web application. The DynamoDB update triggers an AWS Lambda function, which starts a Step Functions workflow. The Step Functions workflow runs the following steps for each image: 5.1
Apache HBase is an effective data storage system for many workflows but accessing this data specifically through Python can be a struggle. The rest of this blog post refers to some sample operations on a CDSW deployment. For more information about catalogs, refer to this documentation [link]. Example Operations . Put Operations.
Now that you understand the concepts for semantic and hierarchical chunking, in case you want to have more flexibility, you can use a Lambda function for adding custom processing logic to chunks such as metadata processing or defining your custom logic for chunking. Make sure to create the Lambda layer for the specific open source framework.
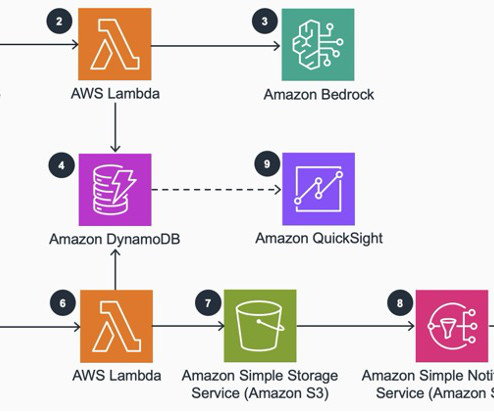
They used the following services in the solution: Amazon Bedrock Amazon DynamoDB AWS Lambda Amazon Simple Storage Service (Amazon S3) The following diagram illustrates the high-level workflow of the current solution: The workflow consists of the following steps: The user navigates to Vidmob and asks a creative-related query.
Key features of AWS Batch Efficient Resource Management: AWS Batch automatically provisions the required resources, such as compute instances and storage, based on job requirements. Integration with AWS Services: AWS Batch seamlessly integrates with other AWS services, such as Amazon S3, AWS Lambda, and Amazon DynamoDB.
As the name suggests, a cloud service provider is essentially a third-party company that offers a cloud-based platform for application, infrastructure or storage services. In a public cloud, all of the hardware, software, networking and storage infrastructure is owned and managed by the cloud service provider. What Is a Public Cloud?
Scaling and State This is Part 9 of Learning Lambda, a tutorial series about engineering using AWS Lambda. So far in this series we’ve only been talking about processing a small number of events with Lambda, one after the other. Lambda will horizontally scale precisely when we need it to a massive extent.
The workflow consists of the following steps: The user uploads the meeting recording as an audio or video file to the project’s Amazon Simple Storage Service (Amazon S3) bucket, in the /recordings folder. Transcripts are then stored in the project’s S3 bucket under /transcriptions/TranscribeOutput/. AWS CDK version 2.0
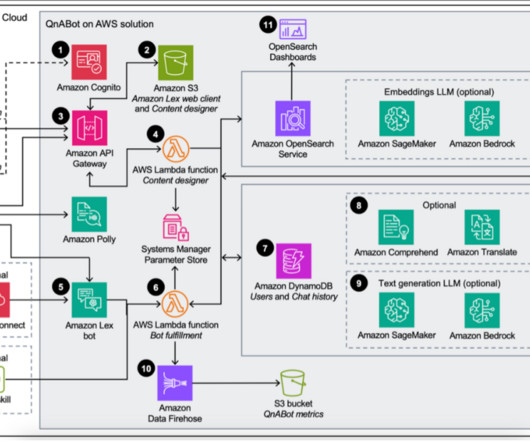
The Content Designer AWS Lambda function saves the input in Amazon OpenSearch Service in a questions bank index. Amazon Lex forwards requests to the Bot Fulfillment Lambda function. Users can also send requests to this Lambda function through Amazon Alexa devices. input – A placeholder for the current user utterance or question.
Action groups are a set of APIs and corresponding business logic, whose OpenAPI schema is defined as JSON files stored in Amazon Simple Storage Service (Amazon S3). Each action group can specify one or more API paths, whose business logic is run through the AWS Lambda function associated with the action group.
Using Amazon Bedrock allows for iteration of the solution using knowledge bases for simple storage and access of call transcripts as well as guardrails for building responsible AI applications. This step is shown by business analysts interacting with QuickSight in the storage and visualization step through natural language.
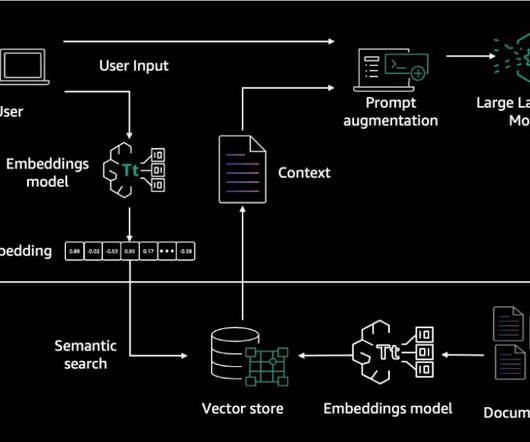
For more details, refer to the Primer on Retrieval Augmented Generation, Embeddings, and Vector Databases section in Preview – Connect Foundation Models to Your Company Data Sources with Agents for Amazon Bedrock. For more information, refer to Model access. You will use this Lambda layer code later to create the Lambda function.
An Amazon Cognito identity pool grants temporary access to the Amazon Simple Storage Service (Amazon S3) bucket. API Gateway instantiates an AWS Step Functions The state machine orchestrates the AI/ML services Amazon Transcribe and Amazon Bedrock and the NoSQL data store Amazon DynamoDB using AWS Lambda functions.
When processing the user’s request, the migration assistant invokes relevant action groups such as R Dispositions and Migration Plan , which in turn invoke specific AWS Lambda The Lambda functions process the request using RAG to produce the required output. For more information, refer to Model access.
Amazon Lex then invokes an AWS Lambda handler for user intent fulfillment. The Lambda function associated with the Amazon Lex chatbot contains the logic and business rules required to process the user’s intent. For more details on supported data sources, refer to Data sources. ConversationTable – Stores conversation history.
The launch template and Auto Scaling group will be used to launch instances based on the queue depth (the number of jobs in the queue) value provided by the runner API for a given runner resource class — all triggered by a Lambda function that checks the API periodically. Setting up a runner resource class in CircleCI.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content