This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This engine uses artificial intelligence (AI) and machinelearning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. You can invoke Lambda functions from over 200 AWS services and software-as-a-service (SaaS) applications.
Before processing the request, a Lambda authorizer function associated with the API Gateway authenticates the incoming message. After it’s authenticated, the request is forwarded to another Lambda function that contains our core application logic. in the GitHub repository you cloned to your local machine during deployment.
To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. We walk you through our solution, detailing the core logic of the Lambda functions. Amazon S3 invokes the {stack_name}-create-batch-queue-{AWS-Region} Lambda function.
When API Gateway receives the request, it triggers an AWS Lambda The Lambda function sends the question to the classifier LLM to determine whether it is a history or math question. These embeddings are then saved as a reference index inside an in-memory FAISS vector store, which is deployed as a Lambda layer.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. Alternatively, you can use AWS Lambda and implement your own logic, or use open source tools such as fmeval. For example, in one common scenario with Cognito that accesses resources with API Gateway and Lambda with a user pool.
The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket. The Lambda function runs the database query against the appropriate OpenSearch Service indexes, searching for exact matches or using fuzzy matching for partial information.
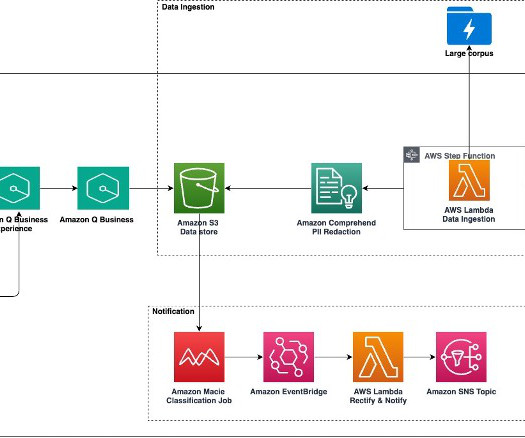
The Amazon Q Business pre-built connectors like Amazon Simple Storage Service (Amazon S3), document retrievers, and upload capabilities streamlined data ingestion and processing, enabling the team to provide swift, accurate responses to both basic and advanced customer queries.
Flexible logging –You can use this solution to store logs either locally or in Amazon Simple Storage Service (Amazon S3) using Amazon Data Firehose, enabling integration with existing monitoring infrastructure. She leads machinelearning projects in various domains such as computer vision, natural language processing, and generative AI.
The solution consists of the following steps: Relevant documents are uploaded and stored in an Amazon Simple Storage Service (Amazon S3) bucket. The text extraction AWS Lambda function is invoked by the SQS queue, processing each queued file and using Amazon Textract to extract text from the documents.
The solution also uses Amazon Cognito user pools and identity pools for managing authentication and authorization of users, Amazon API Gateway REST APIs, AWS Lambda functions, and an Amazon Simple Storage Service (Amazon S3) bucket. To launch the solution in a different Region, change the aws_region parameter accordingly.
If an image is uploaded, it is stored in Amazon Simple Storage Service (Amazon S3) , and a custom AWS Lambda function will use a machinelearning model deployed on Amazon SageMaker to analyze the image to extract a list of place names and the similarity score of each place name.
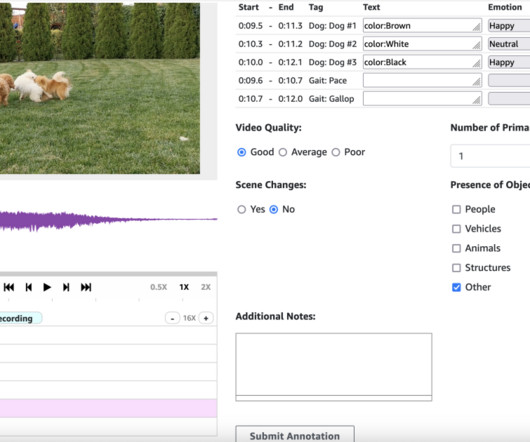
At its core, Amazon Simple Storage Service (Amazon S3) serves as the secure storage for input files, manifest files, annotation outputs, and the web UI components. Pre-annotation and post-annotation AWS Lambda functions are optional components that can enhance the workflow. On the SageMaker console, choose Create labeling job.
Python is used extensively among Data Engineers and Data Scientists to solve all sorts of problems from ETL/ELT pipelines to building machinelearning models. Apache HBase is an effective data storage system for many workflows but accessing this data specifically through Python can be a struggle. Introduction. builder. .appName(
Data consolidation The transcribed patient reports are consolidated into a structured database, enabling efficient storage, retrieval, and analysis. Copying these sample files will trigger an S3 event invoking the AWS Lambda function audio-to-text. On the Lambda console, navigate to the function named hcls_clinical_trial_analysis.
Multiple specialized Amazon Simple Storage Service Buckets (Amazon S3 Bucket) store different types of outputs. Solution Components Storage architecture The application uses a multi-bucket Amazon S3 storage architecture designed for clarity, efficient processing tracking, and clear separation of document processing stages.
An email handler AWS Lambda function is invoked by WorkMail upon the receipt of an email, and acts as the intermediary that receives requests and passes it to the appropriate agent. The system indexes documents and files stored in Amazon Simple Storage Service (Amazon S3) using Amazon OpenSearch Service for quick retrieval.
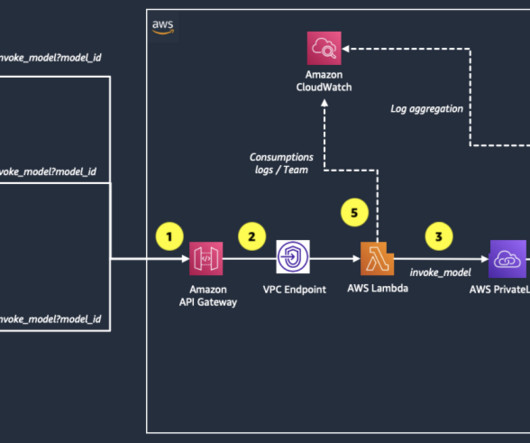
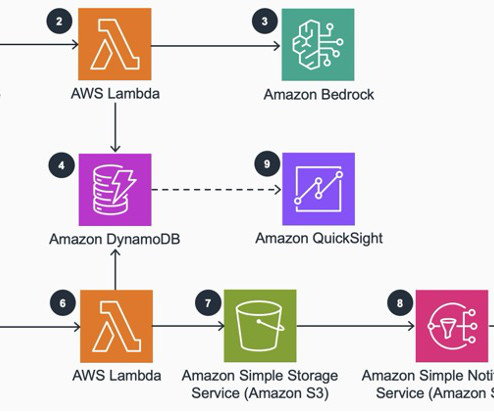
API Gateway routes the request to an AWS Lambda function ( bedrock_invoke_model ) that’s responsible for logging team usage information in Amazon CloudWatch and invoking the Amazon Bedrock model. To learn more about PrivateLink, see Use AWS PrivateLink to set up private access to Amazon Bedrock.
In this post, we demonstrate a few metrics for online LLM monitoring and their respective architecture for scale using AWS services such as Amazon CloudWatch and AWS Lambda. Amazon Bedrock saves the request and completion (response) in Amazon Simple Storage Service (Amazon S3) as the per configuration of invocation logging.
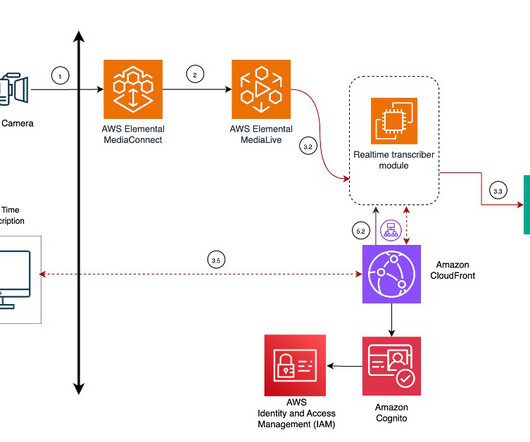
MediaLive also extracts the audio-only output and stores it in an Amazon Simple Storage Service (Amazon S3) bucket, facilitating a subsequent postprocessing workflow. A serverless, event-driven workflow using Amazon EventBridge and AWS Lambda automates the post-event processing.
The storage layer uses Amazon Simple Storage Service (Amazon S3) to hold the invoices that business users upload. You can trigger the processing of these invoices using the AWS CLI or automate the process with an Amazon EventBridge rule or AWS Lambda trigger. Importantly, your document and data are not stored after processing.
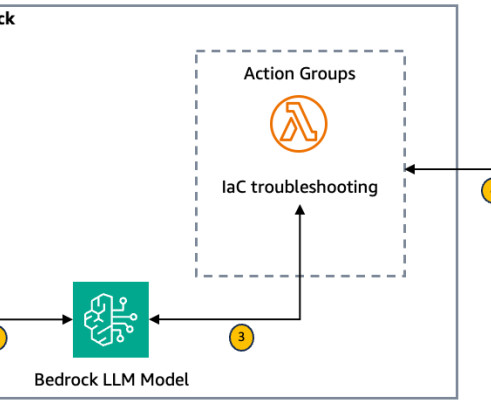
Error retrieval and context gathering The Amazon Bedrock agent forwards these details to an action group that invokes the first AWS Lambda function (see the following Lambda function code ). This contextual information is then sent back to the first Lambda function. Provide the troubleshooting steps to the user.
Currently, AWS offers over 200 cloud services, including cloud hosting, storage, machinelearning, and container management. In 2006, Amazon launched its cloud services platform, Amazon Web Services (AWS) , one of the leading cloud providers to date.
The raw photos are stored in Amazon Simple Storage Service (Amazon S3). Aurora MySQL serves as the primary relational data storage solution for tracking and recording media file upload sessions and their accompanying metadata. S3, in turn, provides efficient, scalable, and secure storage for the media file objects themselves.
Scalable architecture Uses AWS services like AWS Lambda and Amazon Simple Queue Service (Amazon SQS) for efficient processing of multiple reviews. The workflow consists of the following steps: WAFR guidance documents are uploaded to a bucket in Amazon Simple Storage Service (Amazon S3).
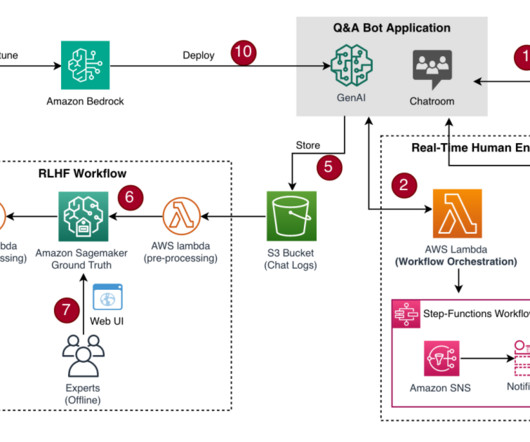
An important aspect of developing effective generative AI application is Reinforcement Learning from Human Feedback (RLHF). RLHF is a technique that combines rewards and comparisons, with human feedback to pre-train or fine-tune a machinelearning (ML) model. Here, we use the on-demand option. More information can be found here.
Amazon Lambda : to run the backend code, which encompasses the generative logic. Amazon Simple Storage Service (S3) : for documents and processed data caching. In step 3, the frontend sends the HTTPS request via the WebSocket API and API gateway and triggers the first Amazon Lambda function.
Now that you understand the concepts for semantic and hierarchical chunking, in case you want to have more flexibility, you can use a Lambda function for adding custom processing logic to chunks such as metadata processing or defining your custom logic for chunking. Make sure to create the Lambda layer for the specific open source framework.
In this post, we show you how to build a speech-capable order processing agent using Amazon Lex, Amazon Bedrock, and AWS Lambda. A Lambda function pulls the appropriate prompt template from the Lambda layer and formats model prompts by adding the customer input in the associated prompt template. awscli>=1.29.57
Hugging Face is an open-source machinelearning (ML) platform that provides tools and resources for the development of AI projects. The workflow consists of the following steps: The user uploads the meeting recording as an audio or video file to the project’s Amazon Simple Storage Service (Amazon S3) bucket, in the /recordings folder.
Amazon Bedrock offers fine-tuning capabilities that allow you to customize these pre-trained models using proprietary call transcript data, facilitating high accuracy and relevance without the need for extensive machinelearning (ML) expertise. Yasmine Rodriguez Wakim is the Chief Technology Officer at Asure Software.
This architecture includes the following steps: A user interacts with the Streamlit chatbot interface and submits a query in natural language This triggers a Lambda function, which invokes the Knowledge Bases RetrieveAndGenerate API. You will use this Lambda layer code later to create the Lambda function.
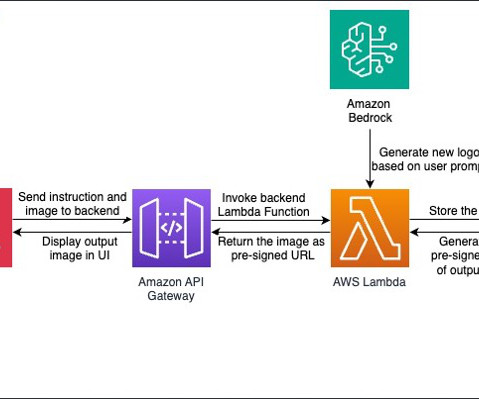
Integrating it with the range of AWS serverless computing, networking, and content delivery services like AWS Lambda , Amazon API Gateway , and AWS Amplify facilitates the creation of an interactive tool to generate dynamic, responsive, and adaptive logos. This API will be used to invoke the Lambda function.
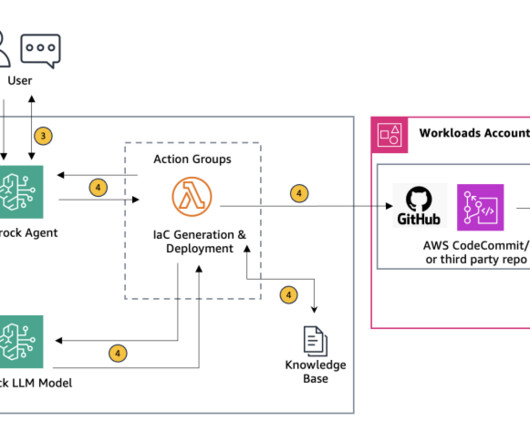
Figure 1 : High level overview of creating Infrastructure as Code from architecture diagram Initial Input through the Amazon Bedrock chat console : The user begins by entering the name of their Amazon Simple Storage Service (Amazon S3) bucket and the object (key) name where the architecture diagram is stored into the Amazon Bedrock chat console.
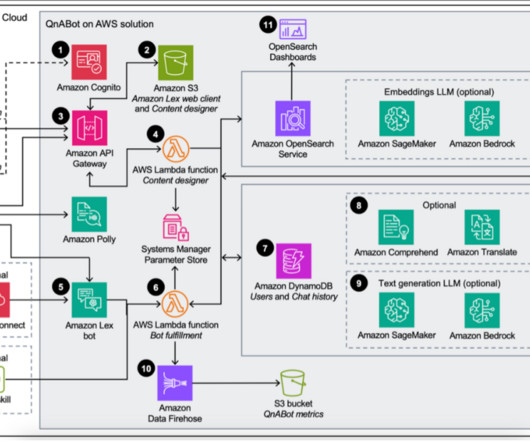
The solution is extensible, uses AWS AI and machinelearning (ML) services, and integrates with multiple channels such as voice, web, and text (SMS). The Content Designer AWS Lambda function saves the input in Amazon OpenSearch Service in a questions bank index.
This is done using ReAct prompting, which breaks down the task into a series of steps that are processed sequentially: For device metrics checks, we use the check-device-metrics action group, which involves an API call to Lambda functions that then query Amazon Athena for the requested data. It serves as the data source to the knowledge base.
The architecture carries out the following steps: Customer reviews can be imported into an Amazon Simple Storage Service (Amazon S3) bucket as JSON objects. This bucket will have event notifications enabled to invoke an AWS Lambda function to process the objects created or updated.
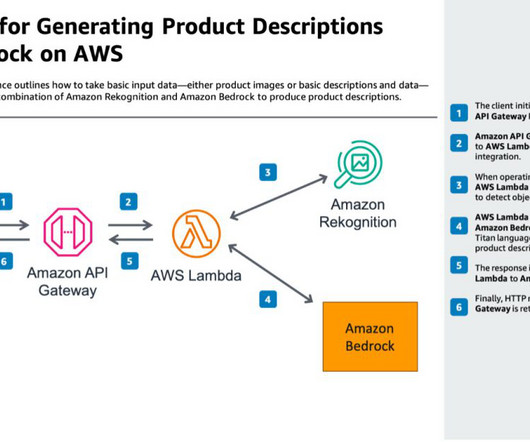
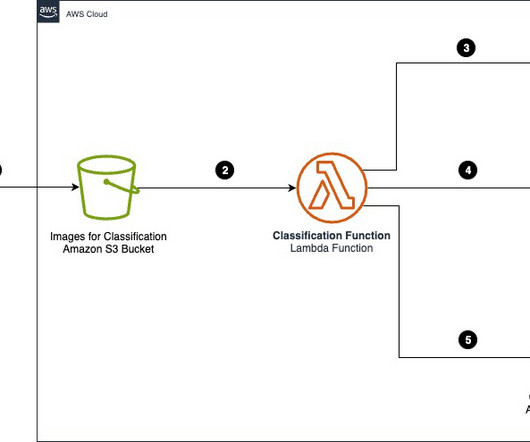
AWS Lambda – AWS Lambda provides serverless compute for processing. Note that in this solution, all of the storage is in the UI. Amazon API Gateway passes the request to AWS Lambda through a proxy integration. When operating on product image inputs, AWS Lambda calls Amazon Rekognition to detect objects in the image.
This includes setting up Amazon API Gateway , AWS Lambda functions, and Amazon Athena to enable querying the structured sales data. Prerequisites Before creating your application in Amazon Bedrock IDE, you’ll need to set up a few resources in your AWS account.
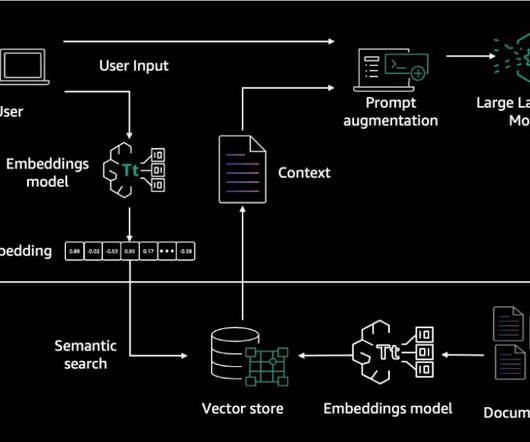
We use the following key components: Embeddings – Embeddings are numerical representations of real-world objects that machinelearning (ML) and AI systems use to understand complex knowledge domains like humans do. An Amazon S3 object notification event invokes the embedding AWS Lambda function.
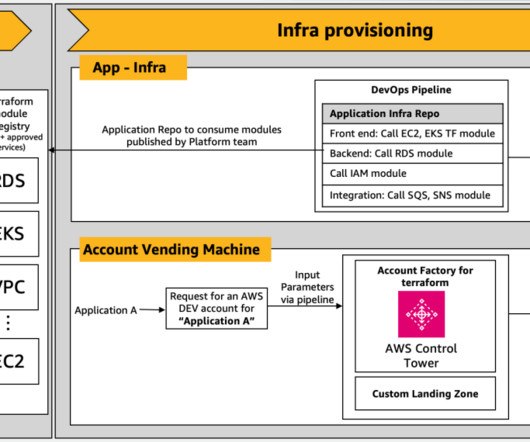
In parallel, the AVM layer invokes a Lambda function to generate Terraform code. The reviewed and updated Terraform scripts are then used to deploy infrastructure components into the newly provisioned AWS account, setting up compute, storage, and networking resources required for the application. Access to Amazon Bedrock models.
Solution overview The policy documents reside in Amazon Simple Storage Service (Amazon S3) storage. This action invokes an AWS Lambda function to retrieve the document embeddings from the OpenSearch Service database and present them to Anthropics Claude 3 Sonnet FM, which is accessed through Amazon Bedrock.
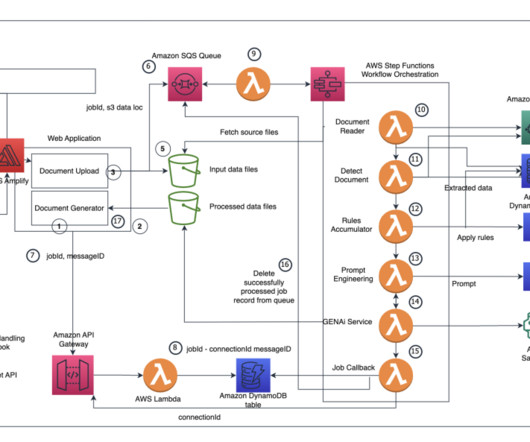
The application uses the Amplify libraries for Amazon Simple Storage Service (Amazon S3) and uploads documents provided by users to Amazon S3. The WebSocket triggers an AWS Lambda function, which creates a record in Amazon DynamoDB. Another Lambda function gets triggered with a new message in the SQS queue.
Get 1 GB of free storage. Try Render Vercel Earlier known as Zeit, the Vercel app acts as the top layer of AWS Lambda which will make running your applications easy. Their service provides the most sophisticated vision, language, speech, and AI models, hence you will be able to create your machine-learning system.
Action groups are a set of APIs and corresponding business logic, whose OpenAPI schema is defined as JSON files stored in Amazon Simple Storage Service (Amazon S3). Each action group can specify one or more API paths, whose business logic is run through the AWS Lambda function associated with the action group.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content