This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Bedrock has recently launched two new capabilities to address these evaluation challenges: LLM-as-a-judge (LLMaaJ) under Amazon Bedrock Evaluations and a brand new RAG evaluation tool for Amazon Bedrock KnowledgeBases.
As successful proof-of-concepts transition into production, organizations are increasingly in need of enterprise scalable solutions. This post explores the new enterprise-grade features for KnowledgeBases on Amazon Bedrock and how they align with the AWS Well-Architected Framework.
KnowledgeBases for Amazon Bedrock allows you to build performant and customized Retrieval Augmented Generation (RAG) applications on top of AWS and third-party vector stores using both AWS and third-party models. If you want more control, KnowledgeBases lets you control the chunking strategy through a set of preconfigured options.
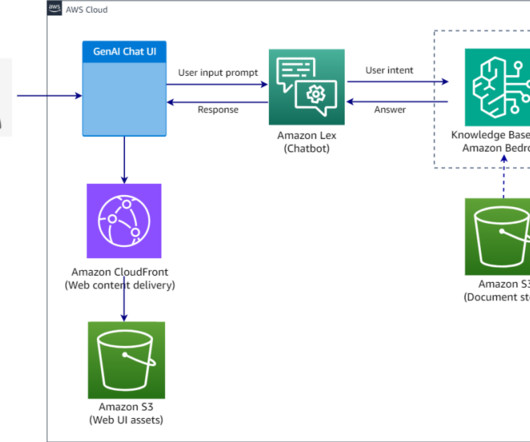
An end-to-end RAG solution involves several components, including a knowledgebase, a retrieval system, and a generation system. Solution overview The solution provides an automated end-to-end deployment of a RAG workflow using KnowledgeBases for Amazon Bedrock. Choose Sync to initiate the data ingestion job.
Organizations can use these models securely, and for models that are compatible with the Amazon Bedrock Converse API, you can use the robust toolkit of Amazon Bedrock, including Amazon Bedrock Agents , Amazon Bedrock KnowledgeBases , Amazon Bedrock Guardrails , and Amazon Bedrock Flows. You can find him on LinkedIn.
We have built a custom observability solution that Amazon Bedrock users can quickly implement using just a few key building blocks and existing logs using FMs, Amazon Bedrock KnowledgeBases , Amazon Bedrock Guardrails , and Amazon Bedrock Agents.
Whether youre an experienced AWS developer or just getting started with cloud development, youll discover how to use AI-powered coding assistants to tackle common challenges such as complex service configurations, infrastructure as code (IaC) implementation, and knowledgebase integration.
The team opted to build out its platform on Databricks for analytics, machinelearning (ML), and AI, running it on both AWS and Azure. I want to provide an easy and secure outlet that’s genuinely production-ready and scalable. The biggest challenge is data. Marsh McLennan created an AI Academy for training all employees.
It often requires managing multiple machinelearning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats. With Amazon Bedrock Data Automation, enterprises can accelerate AI adoption and develop solutions that are secure, scalable, and responsible.
Organizations strive to implement efficient, scalable, cost-effective, and automated customer support solutions without compromising the customer experience. You can simply connect QnAIntent to company knowledge sources and the bot can immediately handle questions using the allowed content. Choose Create knowledgebase.
One way to enable more contextual conversations is by linking the chatbot to internal knowledgebases and information systems. Integrating proprietary enterprise data from internal knowledgebases enables chatbots to contextualize their responses to each user’s individual needs and interests.
They offer fast inference, support agentic workflows with Amazon Bedrock KnowledgeBases and RAG, and allow fine-tuning for text and multi-modal data. To do so, we create a knowledgebase. Complete the following steps: On the Amazon Bedrock console, choose KnowledgeBases in the navigation pane. Choose Next.
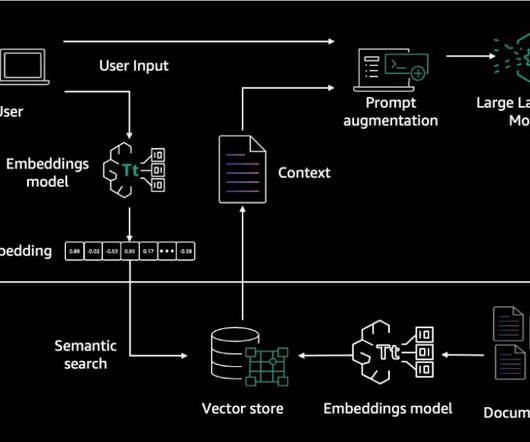
Amazon Bedrock KnowledgeBases is a fully managed capability that helps you implement the entire RAG workflow—from ingestion to retrieval and prompt augmentation—without having to build custom integrations to data sources and manage data flows. Latest innovations in Amazon Bedrock KnowledgeBase provide a resolution to this issue.
The Lambda function interacts with Amazon Bedrock through its runtime APIs, using either the RetrieveAndGenerate API that connects to a knowledgebase, or the Converse API to chat directly with an LLM available on Amazon Bedrock. If you don’t have an existing knowledgebase, refer to Create an Amazon Bedrock knowledgebase.
The team opted to build out its platform on Databricks for analytics, machinelearning (ML), and AI, running it on both AWS and Azure. I want to provide an easy and secure outlet that’s genuinely production-ready and scalable. The biggest challenge is data. Marsh McLellan created an AI Academy for training all employees.
Amazon Bedrock Agents coordinates interactions between foundation models (FMs), knowledgebases, and user conversations. The agents also automatically call APIs to perform actions and access knowledgebases to provide additional information. The documents are chunked into smaller segments for more effective processing.
KnowledgeBases for Amazon Bedrock is a fully managed service that helps you implement the entire Retrieval Augmented Generation (RAG) workflow from ingestion to retrieval and prompt augmentation without having to build custom integrations to data sources and manage data flows, pushing the boundaries for what you can do in your RAG workflows.
In November 2023, we announced KnowledgeBases for Amazon Bedrock as generally available. Knowledgebases allow Amazon Bedrock users to unlock the full potential of Retrieval Augmented Generation (RAG) by seamlessly integrating their company data into the language model’s generation process.
As Principal grew, its internal support knowledgebase considerably expanded. With QnABot, companies have the flexibility to tier questions and answers based on need, from static FAQs to generating answers on the fly based on documents, webpages, indexed data, operational manuals, and more.
Organizations need to prioritize their generative AI spending based on business impact and criticality while maintaining cost transparency across customer and user segments. This visibility is essential for setting accurate pricing for generative AI offerings, implementing chargebacks, and establishing usage-based billing models.
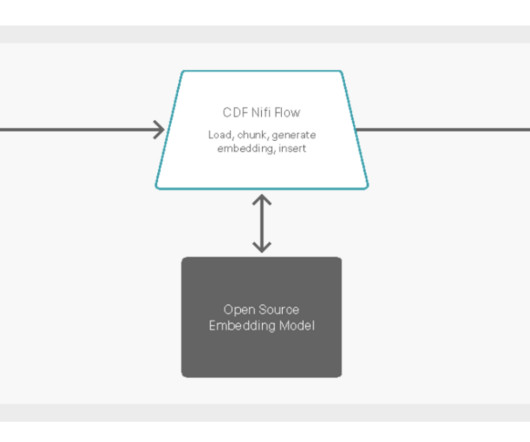
This AMP is built on the foundation of one of our previous AMP s, with the additional enhancement of enabling customers to create a knowledgebase from data on their own website using Cloudera DataFlow (CDF) and then augment questions to the chatbot from that same knowledgebase in Pinecone.
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. This scalability allows for more frequent and comprehensive reviews.
When users pose questions through the natural language interface, the chat agent determines whether to query the structured data in Amazon Athena through the Amazon Bedrock IDE function, search the Amazon Bedrock knowledgebase, or combine both sources for comprehensive insights.
The complexity of developing and deploying an end-to-end RAG solution involves several components, including a knowledgebase, retrieval system, and generative language model. Solution overview The solution provides an automated end-to-end deployment of a RAG workflow using KnowledgeBases for Amazon Bedrock.
Included with Amazon Bedrock is KnowledgeBases for Amazon Bedrock. As a fully managed service, KnowledgeBases for Amazon Bedrock makes it straightforward to set up a Retrieval Augmented Generation (RAG) workflow. With KnowledgeBases for Amazon Bedrock, we first set up a vector database on AWS.
The map functionality in Step Functions uses arrays to execute multiple tasks concurrently, significantly improving performance and scalability for workflows that involve repetitive operations. Furthermore, our solutions are designed to be scalable, ensuring that they can grow alongside your business.
Depending on the use case and data isolation requirements, tenants can have a pooled knowledgebase or a siloed one and implement item-level isolation or resource level isolation for the data respectively. Hasan helps design, deploy and scale Generative AI and Machinelearning applications on AWS.
The following screenshot shows an example of the event filters (1) and time filters (2) as seen on the filter bar (source: Cato knowledgebase ). Retrieval Augmented Generation (RAG) Retrieve relevant context from a knowledgebase, based on the input query. This context is augmented to the original query.
The Asure team was manually analyzing thousands of call transcripts to uncover themes and trends, a process that lacked scalability. Staying ahead in this competitive landscape demands agile, scalable, and intelligent solutions that can adapt to changing demands.
One of the most critical applications for LLMs today is Retrieval Augmented Generation (RAG), which enables AI models to ground responses in enterprise knowledgebases such as PDFs, internal documents, and structured data. These five webpages act as a knowledgebase (source data) to limit the RAG models response.
In this post, we explore how you can use Amazon Q Business , the AWS generative AI-powered assistant, to build a centralized knowledgebase for your organization, unifying structured and unstructured datasets from different sources to accelerate decision-making and drive productivity.
Accelerate your generative AI application development by integrating your supported custom models with native Bedrock tools and features like KnowledgeBases, Guardrails, and Agents. This serverless approach eliminates the need for infrastructure management while providing enterprise-grade security and scalability.
Centralized model In a centralized operating model, all generative AI activities go through a central generative artificial intelligence and machinelearning (AI/ML) team that provisions and manages end-to-end AI workflows, models, and data across the enterprise. Amazon Bedrock cost and usage will be recorded in each LOBs AWS accounts.
It integrates with existing applications and includes key Amazon Bedrock features like foundation models (FMs), prompts, knowledgebases, agents, flows, evaluation, and guardrails. Justin Ossai is a GenAI Labs Specialist Solutions Architect based in Dallas, TX.
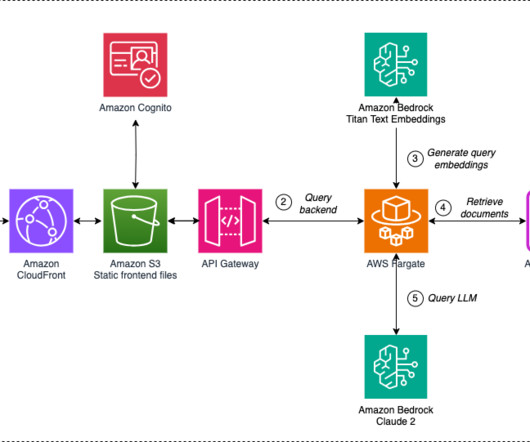
We will walk you through deploying and testing these major components of the solution: An AWS CloudFormation stack to set up an Amazon Bedrock knowledgebase, where you store the content used by the solution to answer questions. This solution uses Amazon Bedrock LLMs to find answers to questions from your knowledgebase.
Limited scalability – As the volume of requests increased, the CCoE team couldn’t disseminate updated directives quickly enough. Going forward, the team enriched the knowledgebase (S3 buckets) and implemented a feedback loop to facilitate continuous improvement of the solution.
When Amazon Q Business became generally available in April 2024, we quickly saw an opportunity to simplify our architecture, because the service was designed to meet the needs of our use caseto provide a conversational assistant that could tap into our vast (sales) domain-specific knowledgebases.
Solution overview This solution uses the Amazon Bedrock KnowledgeBases chat with document feature to analyze and extract key details from your invoices, without needing a knowledgebase. Jobandeep Singh is an Associate Solution Architect at AWS specializing in MachineLearning.
But alongside that, the data is used as the basis of e-learning modules for onboarding, training or professional development — modules created/conceived of either by people in the organization, or by Sana itself. “Sana is used continuously, which is very different from a typical e-learning platform,” he said.
Generative AI empowers organizations to combine their data with the power of machinelearning (ML) algorithms to generate human-like content, streamline processes, and unlock innovation. However, their knowledge is static and tied to the data used during the pre-training phase. The prompt is sent to Anthropic Claude 2.0
It uses the provided conversation history, action groups, and knowledgebases to understand the context and determine the necessary tasks. This is based on the instructions that are interpreted by the assistant as per the system prompt and user’s input. Additionally, you can access device historical data or device metrics.
During the solution design process, Verisk also considered using Amazon Bedrock KnowledgeBases because its purpose built for creating and storing embeddings within Amazon OpenSearch Serverless. Vaibhav Singh is a Product Innovation Analyst at Verisk, based out of New Jersey. Tarik Makota is a Sr.
Evaluating LLMs is an undervalued part of the machinelearning (ML) pipeline. To implement our RAG system, we utilized a dataset of 95,000 radiology report findings-impressions pairs as the knowledge source. promptTemplate = f""" You have to generate radiology report impressions based on the following findings.
The solution is powered by Amazon Bedrock and customized with data to go beyond traditional email-based systems. Retrieval-Augmented Generation (RAG) is the process of allowing a language model to consult an authoritative knowledgebase outside of its training data sources—before generating a response.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content