This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Although automated metrics are fast and cost-effective, they can only evaluate the correctness of an AI response, without capturing other evaluation dimensions or providing explanations of why an answer is problematic. Human evaluation, although thorough, is time-consuming and expensive at scale.
DEX best practices, metrics, and tools are missing Nearly seven in ten (69%) leadership-level employees call DEX an essential or high priority in Ivanti’s 2024 Digital Experience Report: A CIO Call to Action , up from 61% a year ago. Most IT organizations lack metrics for DEX.
Observability refers to the ability to understand the internal state and behavior of a system by analyzing its outputs, logs, and metrics. Evaluation, on the other hand, involves assessing the quality and relevance of the generated outputs, enabling continual improvement.
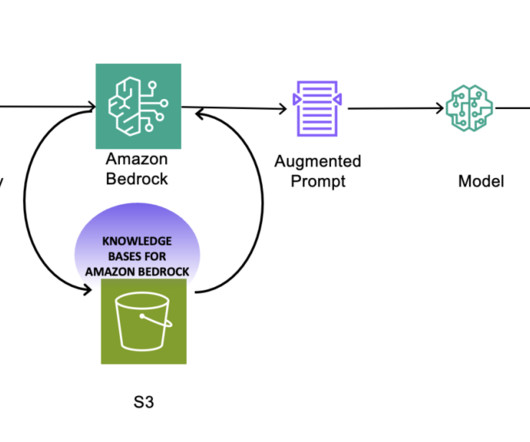
One of its key features, Amazon Bedrock KnowledgeBases , allows you to securely connect FMs to your proprietary data using a fully managed RAG capability and supports powerful metadata filtering capabilities. Context recall – Assesses the proportion of relevant information retrieved from the knowledgebase.
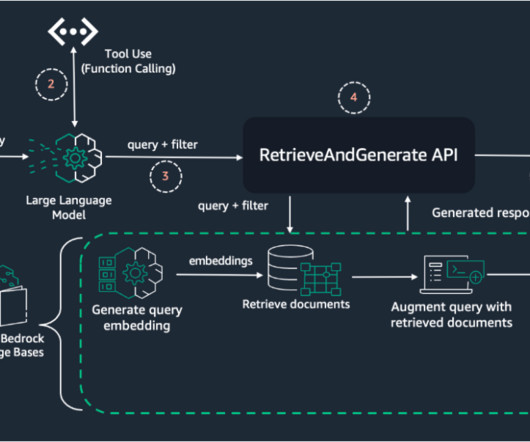
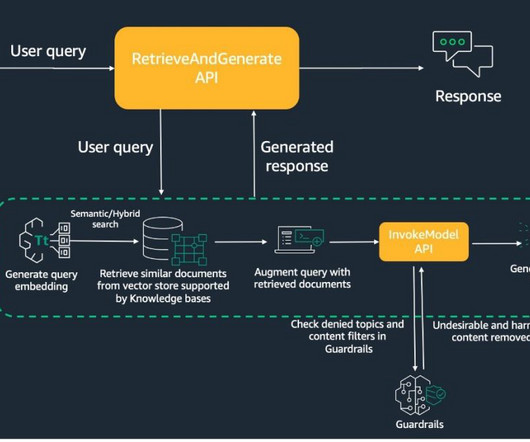
KnowledgeBases for Amazon Bedrock is a fully managed capability that helps you securely connect foundation models (FMs) in Amazon Bedrock to your company data using Retrieval Augmented Generation (RAG). In the following sections, we demonstrate how to create a knowledgebase with guardrails.
They offer fast inference, support agentic workflows with Amazon Bedrock KnowledgeBases and RAG, and allow fine-tuning for text and multi-modal data. To do so, we create a knowledgebase. Complete the following steps: On the Amazon Bedrock console, choose KnowledgeBases in the navigation pane. Choose Next.
This post explores the new enterprise-grade features for KnowledgeBases on Amazon Bedrock and how they align with the AWS Well-Architected Framework. AWS Well-Architected design principles RAG-based applications built using KnowledgeBases for Amazon Bedrock can greatly benefit from following the AWS Well-Architected Framework.
KnowledgeBases for Amazon Bedrock is a fully managed RAG capability that allows you to customize FM responses with contextual and relevant company data. Crucially, if you delete data from the source S3 bucket, it’s automatically removed from the underlying vector store after syncing the knowledgebase.
They have structured data such as sales transactions and revenue metrics stored in databases, alongside unstructured data such as customer reviews and marketing reports collected from various channels. Your tasks include analyzing metrics, providing sales insights, and answering data questions.
As Principal grew, its internal support knowledgebase considerably expanded. With QnABot, companies have the flexibility to tier questions and answers based on need, from static FAQs to generating answers on the fly based on documents, webpages, indexed data, operational manuals, and more.
Amazon Bedrock KnowledgeBases is a fully managed capability that helps you implement the entire RAG workflow—from ingestion to retrieval and prompt augmentation—without having to build custom integrations to data sources and manage data flows. Latest innovations in Amazon Bedrock KnowledgeBase provide a resolution to this issue.
For automatic model evaluation jobs, you can either use built-in datasets across three predefined metrics (accuracy, robustness, toxicity) or bring your own datasets. Regular evaluations allow you to adjust and steer the AI’s behavior based on feedback and performance metrics.
By fine-tuning, the LLM can adapt its knowledgebase to specific data and tasks, resulting in enhanced task-specific capabilities. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models. Sonnet vs.
It often requires managing multiple machinelearning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats. By converting unstructured document collections into searchable knowledgebases, organizations can seamlessly find, analyze, and use their data.
Although tagging is supported on a variety of Amazon Bedrock resources —including provisioned models, custom models, agents and agent aliases, model evaluations, prompts, prompt flows, knowledgebases, batch inference jobs, custom model jobs, and model duplication jobs—there was previously no capability for tagging on-demand foundation models.
Depending on the use case and data isolation requirements, tenants can have a pooled knowledgebase or a siloed one and implement item-level isolation or resource level isolation for the data respectively. Model monitoring – The model monitoring service allows tenants to evaluate model performance against predefined metrics.
Amazon Bedrock offers fine-tuning capabilities that allow you to customize these pre-trained models using proprietary call transcript data, facilitating high accuracy and relevance without the need for extensive machinelearning (ML) expertise. and Anthropics Claude Haiku 3.
By monitoring utilization metrics, organizations can quantify the actual productivity gains achieved with Amazon Q Business. Tracking metrics such as time saved and number of queries resolved can provide tangible evidence of the services impact on overall workplace productivity.
Accelerate your generative AI application development by integrating your supported custom models with native Bedrock tools and features like KnowledgeBases, Guardrails, and Agents. Review the model response and metrics provided. Start with a lower concurrency quota and scale up based on actual usage patterns.
One of the most critical applications for LLMs today is Retrieval Augmented Generation (RAG), which enables AI models to ground responses in enterprise knowledgebases such as PDFs, internal documents, and structured data. How do Amazon Nova Micro and Amazon Nova Lite perform against GPT-4o mini in these same metrics?
With deterministic evaluation processes such as the Factual Knowledge and QA Accuracy metrics of FMEval , ground truth generation and evaluation metric implementation are tightly coupled. To learn more about FMEval, see Evaluate large language models for quality and responsibility of LLMs.
With information about products and availability constantly changing, Tractor Supply sees Hey GURA as a “knowledgebase and a training platform,” says Rob Mills, chief technology, digital commerce, and strategy officer at Tractor Supply. It makes the team member much more efficient.”
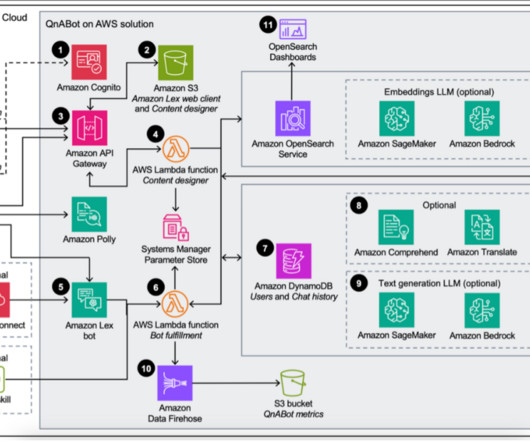
QnABot on AWS (an AWS Solution) now provides access to Amazon Bedrock foundational models (FMs) and KnowledgeBases for Amazon Bedrock , a fully managed end-to-end Retrieval Augmented Generation (RAG) workflow. If a knowledgebase ID is configured , the Bot Fulfillment Lambda function forwards the request to the knowledgebase.
AIOps, at its core, is a data-driven practice of bridging resources and leveraging AI and machinelearning to make predictions based on historical data. Machinelearning and artificial intelligence are complex concepts. AIOps seems to be all the rage these days, and it’s not hard to figure out why.
Additionally, you can access device historical data or device metrics. Additionally, you can access device historical data or device metrics. The device metrics are stored in an Athena DB named "iot_ops_glue_db" in a table named "iot_device_metrics". The AI assistant interprets the user’s text input.
Evaluating LLMs is an undervalued part of the machinelearning (ML) pipeline. We benchmark the results with a metric used for evaluating summarization tasks in the field of natural language processing (NLP) called Recall-Oriented Understudy for Gisting Evaluation (ROUGE). It is time-consuming but, at the same time, critical.
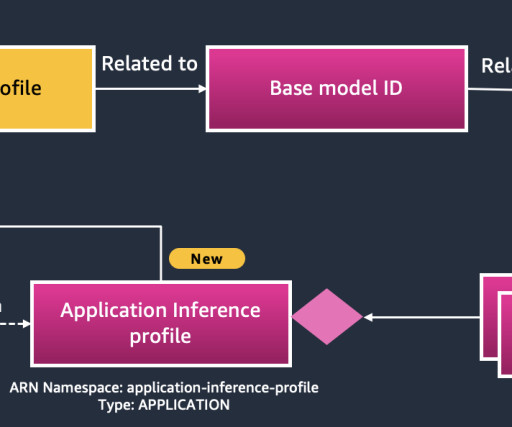
Centralized model In a centralized operating model, all generative AI activities go through a central generative artificial intelligence and machinelearning (AI/ML) team that provisions and manages end-to-end AI workflows, models, and data across the enterprise. There are two types of inference profiles.
But alongside that, the data is used as the basis of e-learning modules for onboarding, training or professional development — modules created/conceived of either by people in the organization, or by Sana itself. “Sana is used continuously, which is very different from a typical e-learning platform,” he said.
Increasingly, CRM software development companies use complicated algorithms, AI, and machinelearning technology to analyze data and identify customer bottlenecks. Many CRM software solutions provide customer portals that allow users to open service tickets, search knowledgebases, and download files. Self Service.
Additionally, the complexity increases due to the presence of synonyms for columns and internal metrics available. Embedding is usually performed by a machinelearning (ML) model. I am creating a new metric and need the sales data. To learn more, visit Amazon Bedrock KnowledgeBases now supports structured data retrieval.
AIOps, at its core, is a data-driven practice of bridging resources and leveraging AI and machinelearning to make predictions based on historical data. Machinelearning and artificial intelligence are complex concepts. AIOps seems to be all the rage these days, and it’s not hard to figure out why.
From internal knowledgebases for customer support to external conversational AI assistants, these applications use LLMs to provide human-like responses to natural language queries. This post focuses on evaluating and interpreting metrics using FMEval for question answering in a generative AI application.
Generative AI empowers organizations to combine their data with the power of machinelearning (ML) algorithms to generate human-like content, streamline processes, and unlock innovation. However, their knowledge is static and tied to the data used during the pre-training phase. The prompt is sent to Anthropic Claude 2.0
There are many challenges that can impact employee productivity, such as cumbersome search experiences or finding specific information across an organization’s vast knowledgebases. Knowledge management: Amazon Q Business helps organizations use their institutional knowledge more effectively.
And, if your testing is done using a specific developer script, you’re likely not capturing key metrics to improve your software development lifecycle, such as how the code changes the database. Just as the mainframe continues to modernize, so too does DevOps modernization software.
This approach, when applied to generative AI solutions, means that a specific AI or machinelearning (ML) platform configuration can be used to holistically address the operational excellence challenges across the enterprise, allowing the developers of the generative AI solution to focus on business value.
During the solution design process, Verisk also considered using Amazon Bedrock KnowledgeBases because its purpose built for creating and storing embeddings within Amazon OpenSearch Serverless. Vaibhav Singh is a Product Innovation Analyst at Verisk, based out of New Jersey.
For a generative AI powered Live Meeting Assistant that creates post call summaries, but also provides live transcripts, translations, and contextual assistance based on your own company knowledgebase, see our new LMA solution. Jahed Zaïdi is an AI & MachineLearning specialist at AWS Professional Services in Paris.
The veracity of metrics like these has been challenged over the years. But it’s reasonable to say that knowledge workers in particular devote a sizeable chunk of their workdays to sifting through data, whether to find basic contact info or domain-specific files. . According to McKinsey, employees spend 1.8
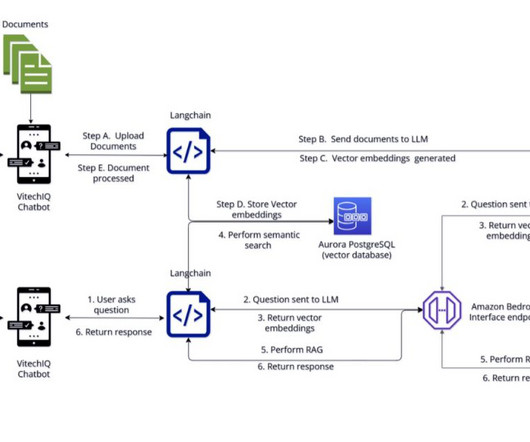
Retrieval Augmented Generation vs. fine tuning Traditional LLMs don’t have an understanding of Vitech’s processes and flow, making it imperative to augment the power of LLMs with Vitech’s knowledgebase. Additionally, Vitech uses Amazon Bedrock runtime metrics to measure latency, performance, and number of tokens. “We
DEX best practices, metrics and tools are missing Nearly seven in ten (69%) leadership-level employees call DEX an essential or high priority in Ivantis 2024 Digital Experience Report: A CIO Call to Action , up from 61% a year ago. Most IT organizations lack metrics for DEX.
Traditional approaches rely on training machinelearning models, requiring labeled data and iterative fine-tuning. This enables the calculation of critical overall metrics such as accuracy , macro-precision , macro-recall , and micro-precision.
To create AI assistants that are capable of having discussions grounded in specialized enterprise knowledge, we need to connect these powerful but generic LLMs to internal knowledgebases of documents. To understand these limitations, let’s consider again the example of deciding where to invest based on financial reports.
Verisk FAST’s AI companion aims to alleviate this burden by not only providing 24/7 support for business processing and configuration questions related to FAST, but also tapping into the immense knowledgebase to provide an in-depth, tailored response. However, they understood that this was not a one-and-done effort.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content