This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The data is spread out across your different storage systems, and you don’t know what is where. Scalable data infrastructure As AI models become more complex, their computational requirements increase. As the leader in unstructured data storage, customers trust NetApp with their most valuable data assets.
To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. It stores information such as job ID, status, creation time, and other metadata. Amazon S3 invokes the {stack_name}-create-batch-queue-{AWS-Region} Lambda function.
As enterprises begin to deploy and use AI, many realize they’ll need access to massive computing power and fast networking capabilities, but storage needs may be overlooked. In that case, Duos needs super-fast storage that works alongside its AI computing units. “If We need to get that information out as quickly as possible.”
For chief information officers (CIOs), the lack of a unified, enterprise-wide data source poses a significant barrier to operational efficiency and informed decision-making. An analysis uncovered that the root cause was incomplete and inadequately cleaned source data, leading to gaps in crucial information about claimants.
Scalability and Flexibility: The Double-Edged Sword of Pay-As-You-Go Models Pay-as-you-go pricing models are a game-changer for businesses. In these scenarios, the very scalability that makes pay-as-you-go models attractive can undermine an organization’s return on investment.
Scalability and Flexibility: The Double-Edged Sword of Pay-As-You-Go Models Pay-as-you-go pricing models are a game-changer for businesses. In these scenarios, the very scalability that makes pay-as-you-go models attractive can undermine an organization’s return on investment.
As AI solutions process more data and move it across environments, organizations must closely monitor data flows to safeguard sensitive information and meet both internal governance guidelines and external regulatory requirements.
Most of Petco’s core business systems run on four InfiniBox® storage systems in multiple data centers. For the evolution of its enterprise storage infrastructure, Petco had stringent requirements to significantly improve speed, performance, reliability, and cost efficiency. Infinidat rose to the challenge.
In todays fast-paced digital landscape, the cloud has emerged as a cornerstone of modern business infrastructure, offering unparalleled scalability, agility, and cost-efficiency. As organizations increasingly migrate to the cloud, however, CIOs face the daunting challenge of navigating a complex and rapidly evolving cloud ecosystem.
Azure Synapse Analytics is Microsofts end-to-give-up information analytics platform that combines massive statistics and facts warehousing abilities, permitting advanced records processing, visualization, and system mastering. Data Lake Storage (Gen2): Select or create a Data Lake Storage Gen2 account.
This ensures data privacy, security, and compliance with national laws, particularly concerning sensitive information. VMware Private AI Foundation brings together industry-leading scalable NVIDIA and ecosystem applications for AI, and can be customized to meet local demands.
Introduction With an ever-expanding digital universe, data storage has become a crucial aspect of every organization’s IT strategy. S3 Storage Undoubtedly, anyone who uses AWS will inevitably encounter S3, one of the platform’s most popular storage services. Storage Class Designed For Retrieval Change Min.
These meetings often involve exchanging information and discussing actions that one or more parties must take after the session. Amazon DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability. Finally, video or audio files uploaded are stored securely in an S3 bucket.
With the information technology element finding its roots in every financial organization and across all industries, strong storage capacity forms the backbone for availability, durability, and scalability. Among these, Amazon S3 is one of the most popular services to meet these needs.
In this post, we explore how to deploy distilled versions of DeepSeek-R1 with Amazon Bedrock Custom Model Import, making them accessible to organizations looking to use state-of-the-art AI capabilities within the secure and scalable AWS infrastructure at an effective cost. For more information, see Create a service role for model import.
As the technology subsists on data, customer trust and their confidential information are at stake—and enterprises cannot afford to overlook its pitfalls. Computational requirements, such as the type of GenAI models, number of users, and data storage capacity, will affect this choice.
As with many data-hungry workloads, the instinct is to offload LLM applications into a public cloud, whose strengths include speedy time-to-market and scalability. The engines use this information to recommend content based on users’ preference history. An LLM is only as strong as its inferencing capabilities.
To make accurate, data-driven decisions, businesses need to feed LLMs with proprietary information, but this risks exposing sensitive data to unauthorized parties. Dell Technologies takes this a step further with a scalable and modular architecture that lets enterprises customize a range of GenAI-powered digital assistants.
Big data is a discipline that deals with methods of analyzing, collecting information systematically, or otherwise dealing with collections of data that are too large or too complex for conventional device data processing applications. The Freenet network offers an efficient way to store and retrieve anonymous information.
In this post, we share how Hearst , one of the nation’s largest global, diversified information, services, and media companies, overcame these challenges by creating a self-service generative AI conversational assistant for business units seeking guidance from their CCoE.
As successful proof-of-concepts transition into production, organizations are increasingly in need of enterprise scalable solutions. For more information, see Create a service role for Knowledge bases for Amazon Bedrock. StorageConfiguration – Specify information about the vector store in which the data source is stored.
This wealth of content provides an opportunity to streamline access to information in a compliant and responsible way. Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles.
Petabyte-level scalability and use of low-cost object storage with millisec response to enable historical analysis and reduce costs. AI-poweredcapabilitiesthat enable rapid analysis and provide performance-related information in an understandable business context. A single view of all operations on premises and in the cloud.
These indexes enable efficient searching and retrieval of part data and vehicle information, providing quick and accurate results. The agents also automatically call APIs to perform actions and access knowledge bases to provide additional information. The following diagram illustrates how it works.
IT teams hold a lot of innovation power, as effective use of emerging technologies is crucial for informed decision-making and is key to staying a beat ahead of the competition. A hybrid cloud approach means data storage is scalable and accessible, so that more data is an asset—not a detriment.
The fundraising perhaps reflects the growing demand for platforms that enable flexible data storage and processing. According to a Fivetran poll , 82% of companies are making decisions based on stale information. customer preferences). Real-time databases promise to resolve this.
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. Integration with the AWS Well-Architected Tool pre-populates workload information and initial assessment responses.
In a world whereaccording to Gartner over 80% of enterprise data is unstructured, enterprises need a better way to extract meaningful information to fuel innovation. With Amazon Bedrock Data Automation, enterprises can accelerate AI adoption and develop solutions that are secure, scalable, and responsible.
This challenge is further compounded by concerns over scalability and cost-effectiveness. Depending on the language model specifications, we need to adjust the amount of Amazon Elastic Block Store (Amazon EBS) storage to properly store the base model and adapter weights. The following diagram is the solution architecture.
From insurance to banking to healthcare, organizations of all stripes are upgrading their aging content management systems with modern, advanced systems that introduce new capabilities, flexibility, and cloud-based scalability. We’re confident the Nuxeo Platform will enable us to inform our reps ASAP,” said a healthcare company rep.
This infrastructure comprises a scalable and reliable network that can be accessed from any location with the help of an internet connection. In healthcare, Cloud Computing has paved the way for a whole new world of possibilities in improving patient care, information sharing, and data retrieval. 3: Enhances Security.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
Deletion vectors are a storage optimization feature that replaces physical deletion with soft deletion. Data privacy regulations such as GDPR , HIPAA , and CCPA impose strict requirements on organizations handling personally identifiable information (PII) and protected health information (PHI).
Without this ability, an organization could end up moving sensitive information to an unsecured location or providing access to people who should not have it. However, enterprises with integration solutions that coexist with native IT architecture have scalable data capture and synchronization abilities.
The map functionality in Step Functions uses arrays to execute multiple tasks concurrently, significantly improving performance and scalability for workflows that involve repetitive operations. Furthermore, our solutions are designed to be scalable, ensuring that they can grow alongside your business.
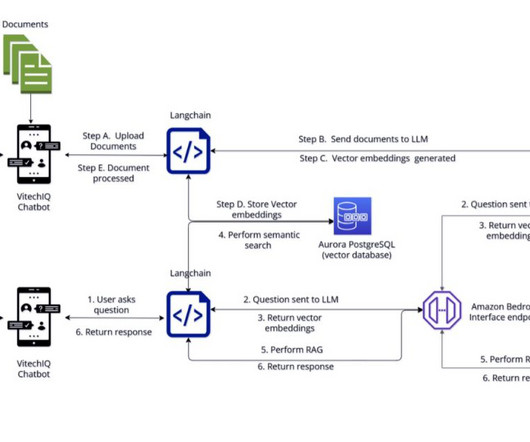
To serve their customers, Vitech maintains a repository of information that includes product documentation (user guides, standard operating procedures, runbooks), which is currently scattered across multiple internal platforms (for example, Confluence sites and SharePoint folders). langsmith==0.0.43 pgvector==0.2.3 streamlit==1.28.0
Among LCS’ major innovations is its Goods to Person (GTP) capability, also known as the Automated Storage and Retrieval System (AS/RS). The system uses robotics technology to improve scalability and cycle times for material delivery to manufacturing. This storage capacity ensures that items can be efficiently organized and accessed.
It multiplies data volume, inflating storage expenses and complicating management. While doing this once isn’t a big deal, repeatedly copying and organizing photos over many years can consume a significant amount of your phone’s storage. Metadata provides information about data, making it more searchable and easier to track.
The data dilemma: Breaking down data silos with intelligent data infrastructure In most organizations, storage silos and data fragmentation are common problems—caused by application requirements, mergers and acquisitions, data ownership issues, rapid tech adoption, and organizational structure.
Unless you analyze it, all this useful information can get lost in storage, often leading to lost revenue opportunities or high operational costs. Problems with real-time, scalable data utilization impact business efficiency, explains one technology decision-maker. Is it difficult to find information within your organization?
We don’t intend to bring all of the logistics and storage in-house, but we want to be more efficient and that means working with the right partners,” he said. Benin, in West Africa, uses the platform as a national market information system. The cost of going door to door to each farmer was really high,” he said.
Traditionally, data management and the core underlying infrastructure, including storage and compute, have been viewed as separate IT initiatives. Beyond the traditional considerations of speeds and feeds, forward-thinking CIOs must ensure their compute and storage are adaptable.
Financial technology and services company Fidelity National Information Services (FIS) uses the low code WaveMaker to develop the user interfaces for the customer-facing applications it builds for its bank customers, using APIs to connect those applications to the customer’s or FIS’ back-end systems.
This complicates synchronization, scalability, detecting anomalies, pulling valuable insights, and enhancing decision-making. Enterprises can harness the power of continuous information flow by lessening the gap between traditional architecture and dynamic data streams. The complexity doesn’t end here. CIO, Data Integration
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















































Let's personalize your content