This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For more information on how to view and increase your quotas, refer to Amazon EC2 service quotas. As a result, traffic won’t be balanced across all replicas of your deployment. For production use, make sure that loadbalancing and scalability considerations are addressed appropriately.
For example, if a company’s e-commerce website is taking too long to process customer transactions, a causal AI model determines the root cause (or causes) of the delay, such as a misconfigured loadbalancer. Visit here for more information or contact BMC. This customer data, however, remains on customer systems.
Loadbalancer – Another option is to use a loadbalancer that exposes an HTTPS endpoint and routes the request to the orchestrator. You can use AWS services such as Application LoadBalancer to implement this approach. API Gateway also provides a WebSocket API.
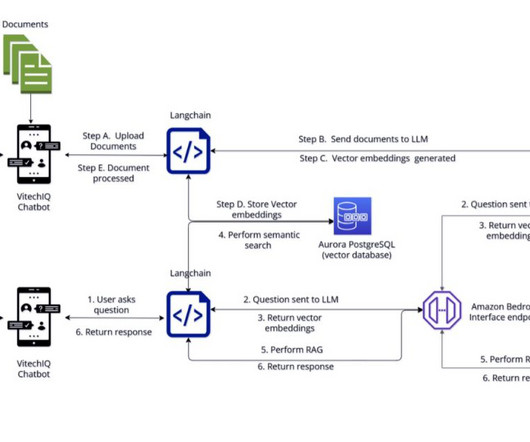
To serve their customers, Vitech maintains a repository of information that includes product documentation (user guides, standard operating procedures, runbooks), which is currently scattered across multiple internal platforms (for example, Confluence sites and SharePoint folders). langsmith==0.0.43 pgvector==0.2.3 streamlit==1.28.0
This setup will adopt the usage of cloud loadbalancing, auto scaling and managed SSL certificates. We do want to get information about the interactions (to identify misbehavior for example), so we will allow for flow logs to be collected but with a low sample rate and just at 25% of the traffic.
Loadbalancing – you can use this to distribute a load of incoming traffic on your virtual machine. OS guest diagnostics – You can turn this on to get the metrics per minute. Also, the validation of the information that you have filled earlier will happen in this tab only. For details – [link].
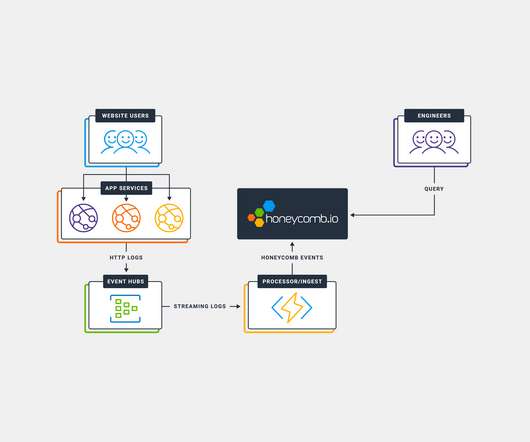
CloudWatch metrics can be a very useful source of information for a number of AWS services that dont produce telemetry as well as instrumented code. There are also a number of useful metrics for non-web-request based functions, like metrics on concurrent database requests. New to Honeycomb? Get your free account today!
The inherent vulnerabilities of these models include their potential of producing hallucinated responses (generating plausible but false information), their risk of generating inappropriate or harmful content, and their potential for unintended disclosure of sensitive training data.
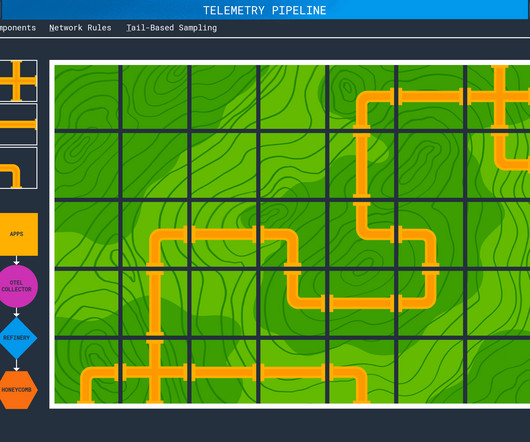
Observability starts by collecting system telemetry data, such as logs, metrics, and traces. To gain a more complete picture, observability tools collect data from various components of the software system: logs, metrics, and traces (typically considered the “three pillars of observability” but don’t get us started on that rant ).
An AI assistant is an intelligent system that understands natural language queries and interacts with various tools, data sources, and APIs to perform tasks or retrieve information on behalf of the user. Additionally, you can access device historical data or device metrics. The tasks are then run through a series of API calls.
The platform is a one-stop shop for football fans to follow their teams, get up-to-date information, and immerse themselves in global football culture. Honeycomb’s SLOs allow teams to define, measure, and manage reliability based on real user impact, rather than relying on traditional system metrics like CPU or memory usage.
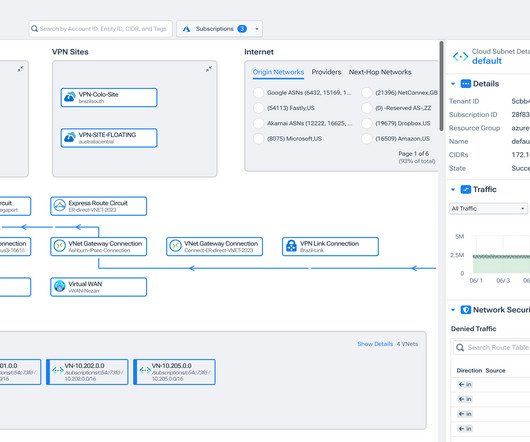
It includes rich metrics for understanding the volume, path, business context, and performance of flows traveling through Azure network infrastructure. For example, Express Route metrics include data about inbound and outbound dropped packets.
In a simple deployment, an application will emit spans, metrics, and logs which will be sent to api.honeycomb.io This also adds the blue lines, which denote metrics data. The metrics are periodically emitted from applications that don’t contribute to traces, such as a database. and show up in charts.
Common monitoring metrics are latency, packet loss, and jitter. But these metrics usually are at an individual service level, like a particular internet gateway or loadbalancer. The outcome of having metrics and logging at the service level is the difficulty of tracing through the system. No more guessing.
When you pull data, you are taking information out of an application or system. Most applications and systems provide APIs that allow you to extract information from them. Pushing data means your source application/system is putting information into a target system. It also configures NiFi accordingly.
Get the latest on the Hive RaaS threat; the importance of metrics and risk analysis; cloud security’s top threats; supply chain security advice for software buyers; and more! . But to truly map cybersecurity efforts to business objectives, you’ll need what CompTIA calls “an organizational risk approach to metrics.”. MFA bypass.
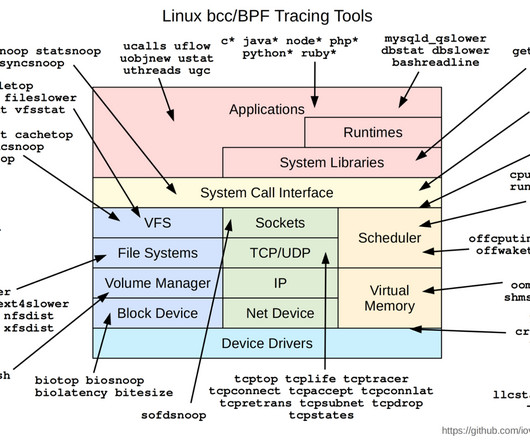
For example, to write an eBPF program in Python to monitor tcpretransmits , you can use the BPF class from the bpfcc library to define a kprobe that attaches to the tcp_retransmit_skb function and captures information about retransmissions. Finally, we loop and handle the perf output events using the open_perf_buffer and kprobe_poll methods.
These devices generate signals (by design or through instrumentation) that provide critical information to those responsible for managing network health. Traditional network monitoring relies on telemetry sources such as Simple Network Messaging Protocol (SNMP), sFlow, NetFlow, CPU, memory, and other device-specific metrics.
Decompose these into quantifiable KPIs to direct the project, utilizing metrics like migration duration, savings on costs, and enhancements in performance. Secure data while in transit and when stored, and consolidate encryption key management to protect information during the migration. lowering costs, enhancing scalability).
At times, toolset disparity between various stages and multiple teams driving parallel work streams creates numerous information silos leading to fragmented visibility at the product level. Metrics like velocity, reliability, reduced application release cycles and ability to ramp up/ramp down are commonly used.
Now that you know how to optimize your pipelines via metric benchmarks, your 2nd resolution for 2021 should be to best use precious developer time. Record results on the Cypress Dashboard and loadbalance tests in parallel mode. Resolution 2: Make use of precious developer time. Reuse config. Sonarcloud.
Here are some best practices: Determine the specific customer issues you want to troubleshoot, and the key metrics and events that will help identify and resolve those issues. If the data fails to reach the Shepherd service, our next step is to investigate the ELB loadbalancer. This should guide your instrumentation efforts.
Administrators can identify potential issues and take necessary actions before they escalate by proactively monitoring key metrics such as latency, throughput, disk usage, and resource utilization. These tools provide more advanced monitoring features, including alerting based on custom thresholds and metrics.
As these applications scale, and engineering for reliability comes into the forefront, DevOps engineers begin to rely on networking concepts like loadbalancing, auto-scaling, traffic management, and network security.
And you find the balance of how much telemetry to sample, retaining the shape of important metrics and traces of all the errors, while dropping the rest to minimize costs. This does happen when loadbalancer configuration changes or services start using more HTTP codes. You build up alerts based on those errors.
This is supplemental to the awesome post by Brian Langbecker on using Honeycomb to investigate the Application LoadBalancers (ALB) Status Codes in AWS. Since Azure AppService also has a LoadBalancer serving the application servers, we can use the same querying techniques to investigate AppService performance.
Fun and Informative Events. Leverage this data across your monitoring efforts and integrate with PerfOps’ other tools such as Alerts, Health Monitors and FlexBalancer – a smart approach to loadbalancing. If you are interested in a sponsored post for an event, job, or product, please contact us for more information.
Fun and Informative Events. Leverage this data across your monitoring efforts and integrate with PerfOps’ other tools such as Alerts, Health Monitors and FlexBalancer – a smart approach to loadbalancing. If you are interested in a sponsored post for an event, job, or product, please contact us for more information.
Rather than collecting only flow data from routers, or only eBPF information from containers, the fact that application traffic traverses so many devices means we need much more data to get an accurate view of what’s happening. The Kappa Host agent deployed to collect kernel information and return it to the Kentik platform.
The majority of things that would cause this to fire are better monitored via specific localized metrics (number of healthy instances in a loadbalancer) or SLOs to measure real user experience. Ingest Azure Front Door metrics and trigger based on whether the backend is healthy. Could it be throttling? Conclusion.
A part of the “service level” family , an SLO is a reliability target (for example, “99%”) driven by an SLI (which is a metric like “requests completed without error”) that organizations use to ensure user experiences are smooth and customer contracts are being met. Can we express this in clear language with common-sense metrics?
Fun and Informative Events. Leverage this data across your monitoring efforts and integrate with PerfOps’ other tools such as Alerts, Health Monitors and FlexBalancer – a smart approach to loadbalancing. If you are interested in a sponsored post for an event, job, or product, please contact us for more information.
From a high-level perspective, network operators engage in network capacity planning to understand some key network metrics: Types of network traffic. Measure and analyze traffic metrics to establish performance and capacity baselines for future bandwidth consumption. Key metrics for planning network capacity.
Fun and Informative Events. Leverage this data across your monitoring efforts and integrate with PerfOps’ other tools such as Alerts, Health Monitors and FlexBalancer – a smart approach to loadbalancing. If you are interested in a sponsored post for an event, job, or product, please contact us for more information.
At a high level, if your data contained PII or other sensitive information, it remained on premise in dedicated VMWare pods. Availability ECE provides features such as automatic failover and loadbalancing, which can help ensure high availability and minimize downtime. You need to provide your own loadbalancing solution.
Flow-based network monitoring relies on collecting information about packet flows (i.e. a sequence of related packets) as they traverse routers, switches, loadbalancers, ADCs, network visibility switches, and other devices. Processor information: records CPU usage and memory usage of a device. Flow Protocol Capabilities.
Most of what we’re saying, I mean we’re going to talk about Spinnaker and Kayenta do, but it’s really general information about Canaries. And it supports like an extensible set of metric services and judges and cloud platforms and everything else. Hopefully you’re publishing metrics.
There was also limited visibility into infrastructure components such as hosted loadbalancers, caches and network topologies. The Evolution of Envoy I’ve talked about the core features of Envoy in a previous post that covers another of Matt’s talks, but here I want to touch on the advanced loadbalancing.
Monitoring is the act of taking the data and metrics that observability makes available and tracking them over time so that anomalies, errors, and downtime are noticeable immediately. By monitoring the metrics of running systems, developers can detect when these systems begin to deviate from normal behavior. What is monitoring?
Once the decommissioning process is finished, stop the Cassandra service on the node: Restart the Cassandra service on the remaining nodes in the cluster to ensure data redistribution and replication: LoadBalancing Cassandra employs a token-based partitioning strategy, where data is distributed across nodes based on a token value.
Leverage this data across your monitoring efforts and integrate with PerfOps’ other tools such as Alerts, Health Monitors and FlexBalancer – a smart approach to loadbalancing. Fun and Informative Events. If you are interested in a sponsored post for an event, job, or product, please contact us for more information.
There was also limited visibility into infrastructure components such as hosted loadbalancers, caches and network topologies. The Evolution of Envoy I’ve talked about the core features of Envoy in a previous post that covers another of Matt’s talks, but here I want to touch on the advanced loadbalancing.
Sitefinity Cloud takes full advantage of all the available performance metrics and troubleshooting tools to keep your project in prime shape. There’s more than one way to get things right and fine-tuning is an art if you want loadbalancing, geo redundancy, autoscaling, backup and recovery to absolutely click.
Sitefinity Cloud takes full advantage of all the available performance metrics and troubleshooting tools to keep your project in prime shape. There’s more than one way to get things right and fine-tuning is an art if you want loadbalancing, geo redundancy, autoscaling, backup and recovery to absolutely click.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content