This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We’re living in a phenomenal moment for machinelearning (ML), what Sonali Sambhus , head of developer and ML platform at Square, describes as “the democratization of ML.” When it comes to recruiting for ML, hire experts when you can, but also look into howtraining can help you meet your talent needs.
The problem is that it’s not always clear how to strike a balance between speed and caution when it comes to adopting cutting-edge AI. Data scientists and AI engineers have so many variables to consider across the machinelearning (ML) lifecycle to prevent models from degrading over time.
Called OpenBioML , the endeavor’s first projects will focus on machinelearning-based approaches to DNA sequencing, protein folding and computational biochemistry. Stability AI’s ethically questionable decisions to date aside, machinelearning in medicine is a minefield. Predicting protein structures.
OctoML , a Seattle-based startup that offers a machinelearning acceleration platform build on top of the open-source Apache TVM compiler framework project , today announced that it has raised a $28 million Series B funding round led by Addition. We look forward to supporting the company’s continued growth.”
Across diverse industries—including healthcare, finance, and marketing—organizations are now engaged in pre-training and fine-tuning these increasingly larger LLMs, which often boast billions of parameters and larger input sequence length. This approach reduces memory pressure and enables efficient training of large models.
Today, one of these, Baseten — which is building tech to make it easier to incorporate machinelearning into a business’ operations, production and processes without a need for specialized engineering knowledge — is announcing $20 million in funding and the official launch of its tools.
“I would encourage everbody to look at the AI apprenticeship model that is implemented in Singapore because that allows businesses to get to use AI while people in all walks of life can learn about how to do that. We are happy to share our learnings and what works — and what doesn’t. And why that role?
Educate and train help desk analysts. Equip the team with the necessary training to work with AI tools. Ensuring they understand how to use the tools effectively will alleviate concerns and boost engagement. Ivanti’s service automation offerings have incorporated AI and machinelearning.
As Artificial Intelligence (AI)-powered cyber threats surge, INE Security , a global leader in cybersecurity training and certification, is launching a new initiative to help organizations rethink cybersecurity training and workforce development.
However, these LLM endpoints often can’t be used by enterprises for several reasons: Private Data Sources: Enterprises often need an LLM that knows where and how to access internal company data, and users often can’t share this data with an open LLM. The Need for Fine Tuning Fine tuning solves these issues.
And we recognized as a company that we needed to start thinking about how we leverage advancements in technology and tremendous amounts of data across our ecosystem, and tie it with machinelearning technology and other things advancing the field of analytics. We have about 13,000 employees through this set of training and itâ??s
Then it is best to build an AI agent that can be cross-trained for this cross-functional expertise and knowledge, Iragavarapu says. We are fast tracking those use cases where we can go beyond traditional machinelearning to acting autonomously to complete tasks and make decisions.
These powerful models, trained on vast amounts of data, can generate human-like text, answer questions, and even engage in creative writing tasks. However, training and deploying such models from scratch is a complex and resource-intensive process, often requiring specialized expertise and significant computational resources.
When considering how to work AI into your existing business practices and what solution to use, you must determine whether your goal is to develop, deploy, or consume AI technology. Deploying AI Many modern AI systems are capable of leveraging machine-to-machine connections to automate data ingestion and initiate responsive activity.
In this post, we demonstrate how to effectively perform model customization and RAG with Amazon Nova models as a baseline. Demystifying RAG and model customization RAG is a technique to enhance the capability of pre-trained models by allowing the model access to external domain-specific data sources.
In short, being ready for MLOps means you understand: Why adopt MLOps What MLOps is When adopt MLOps … only then can you start thinking about how to adopt MLOps. Both the tech and the skills are there: MachineLearning technology is by now easy to use and widely available. How to solve this? Enter MLOps.
After months of crunching data, plotting distributions, and testing out various machinelearning algorithms you have finally proven to your stakeholders that your model can deliver business value. For the sake of argumentation, we will assume the machinelearning model is periodically trained on a finite set of historical data.
First, we should know that how is scope in Data Science, So let me tell you that If you searched top jobs on the internet, in that list Data Science will be also present. So, here we will discuss how to become a Data Scientist in India, and how much time need to become a Data Scientist. Image Source. What is Data Science?
Before LLMs and diffusion models, organizations had to invest a significant amount of time, effort, and resources into developing custom machine-learning models to solve difficult problems. In many cases, this eliminates the need for specialized teams, extensive data labeling, and complex machine-learning pipelines.
In this post, we discuss the advantages and capabilities of the Bedrock Marketplace and Nemotron models, and how to get started. Nemotron-4 15B, with its impressive 15-billion-parameter architecture trained on 8 trillion text tokens, brings powerful multilingual and coding capabilities to the Amazon Bedrock.
Training large language models (LLMs) models has become a significant expense for businesses. PEFT is a set of techniques designed to adapt pre-trained LLMs to specific tasks while minimizing the number of parameters that need to be updated. You can also customize your distributed training.
Roughly a year ago, we wrote “ What machinelearning means for software development.” Karpathy suggests something radically different: with machinelearning, we can stop thinking of programming as writing a step of instructions in a programming language like C or Java or Python. Instead, we can program by example.
Fine-tuning is a powerful approach in natural language processing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. We also provide insights on how to achieve optimal results for different dataset sizes and use cases, backed by experimental data and performance metrics.
It’s only as good as the models and data used to train it, so there is a need for sourcing and ingesting ever-larger data troves. But annotating and manipulating that training data takes a lot of time and money, slowing down the work or overall effectiveness, and maybe both. V7 even lays out how the two services compare.)
The team opted to build out its platform on Databricks for analytics, machinelearning (ML), and AI, running it on both AWS and Azure. Gen AI agenda Beswick has an ambitious gen AI agenda but everything being developed and trained today is for internal use only to guard against hallucinations and data leakage.
The gap between emerging technological capabilities and workforce skills is widening, and traditional approaches such as hiring specialized professionals or offering occasional training are no longer sufficient as they often lack the scalability and adaptability needed for long-term success.
But that’s exactly the kind of data you want to include when training an AI to give photography tips. Conversely, some of the other inappropriate advice found in Google searches might have been avoided if the origin of content from obviously satirical sites had been retained in the training set.
In this guide, we’ll explore how to build an AI agent from scratch. These agents are reactive, respond to inputs immediately, and learn from data to improve over time. Different technologies like NLP (natural language processing), machinelearning, and automation are used to build an AI agent.
With the advent of generative AI and machinelearning, new opportunities for enhancement became available for different industries and processes. AWS HealthScribe combines speech recognition and generative AI trained specifically for healthcare documentation to accelerate clinical documentation and enhance the consultation experience.
In 2013, I was fortunate to get into artificial intelligence (more specifically, deep learning) six months before it blew up internationally. It started when I took a course on Coursera called “Machinelearning with neural networks” by Geoffrey Hinton. It was like being love struck.
Job titles like data engineer, machinelearning engineer, and AI product manager have supplanted traditional software developers near the top of the heap as companies rush to adopt AI and cybersecurity professionals remain in high demand. The job will evolve as most jobs have evolved.
However, most of these generative AI models are foundational models: high-capacity, unsupervised learning systems that train on vast amounts of data and take millions of dollars of processing power to do it. What is active learning? Active learning makes training a supervised model an iterative process.
The team opted to build out its platform on Databricks for analytics, machinelearning (ML), and AI, running it on both AWS and Azure. Gen AI agenda Beswick has an ambitious gen AI agenda but everything being developed and trained today is for internal use only to guard against hallucinations and data leakage.
The Berlin-based startup wants to bring AI-powered workflow automation to anyone, letting knowldge workers automate tedious, repetitive and manual parts of their job without the need to learnhow to code. This, of course, is where machinelearning come into play. “We
They have a lot more unknowns: availability of right datasets, model training to meet required accuracy threshold, fairness and robustness of recommendations in production, and many more. A common misconception is that a significant amount of data is required for trainingmachinelearning models. This is not always true.
In terms of how to offer FMs to your tenants, with AWS you have several options: Amazon Bedrock is a fully managed service that offers a choice of FMs from AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. These components are illustrated in the following diagram.
What was once a preparatory task for training AI is now a core part of a continuous feedback and improvement cycle. Training compact, domain-specialized models that outperform general-purpose LLMs in areas like healthcare, legal, finance, and beyond. Todays annotation tools are no longer just for labeling datasets.
Exclusive to Amazon Bedrock, the Amazon Titan family of models incorporates 25 years of experience innovating with AI and machinelearning at Amazon. Solution overview The solution outlines how to build a reverse image search engine to retrieve similar images based on input image queries. Replace with the name of your S3 bucket.
Smart Snippet Model in Coveo The Coveo MachineLearning Smart Snippets model shows users direct answers to their questions on the search results page. Navigate to Recommendations : In the left-hand menu, click “models” under the “MachineLearning” section.
You can try these models with SageMaker JumpStart, a machinelearning (ML) hub that provides access to algorithms and models that can be deployed with one click for running inference. Both pre-trained base and instruction-tuned checkpoints are available under the Apache 2.0
LoRA is a technique for efficiently adapting large pre-trained language models to new tasks or domains by introducing small trainable weight matrices, called adapters, within each linear layer of the pre-trained model. Configure server details In this section, we show how to configure and create an EC2 instance to host the LLM.
Trained on broad, generic datasets spanning a wide range of topics and domains, LLMs use their parametric knowledge to perform increasingly complex and versatile tasks across multiple business use cases. This blog post is co-written with Moran beladev, Manos Stergiadis, and Ilya Gusev from Booking.com.
Matthew Horton is a senior counsel and IP lawyer at law firm Foley & Lardner LLP where he focuses his practice on patent law and IP protections in cybersecurity, AI, machinelearning and more. In fact, the USPTO even issued guidance for eligibility that gave an example of training a neural network.
Our goal is to enable you to set up automated, optimal routing between large language models (LLMs) through Amazon Bedrock Intelligent Prompt Routing and its deep understanding of model behaviors within each model family, which incorporates state-of-the-art methods for training routers for different sets of models, tasks and prompts.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















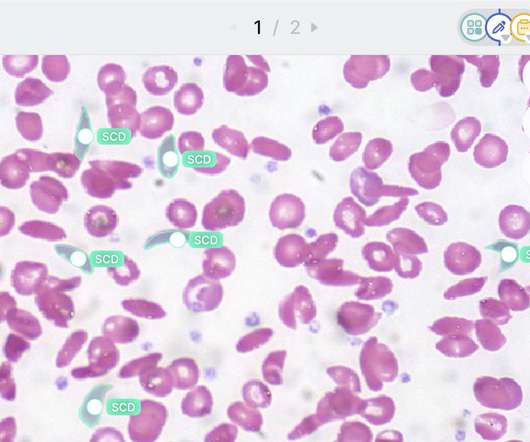




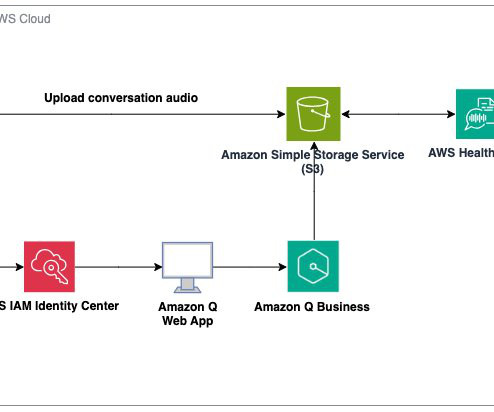




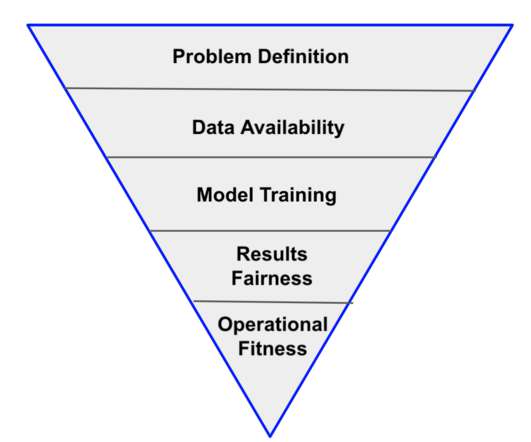






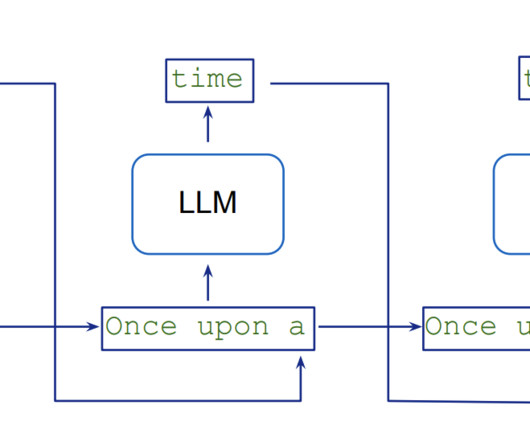











Let's personalize your content