

Supercharge your auto scaling for generative AI inference – Introducing Container Caching in SageMaker Inference
AWS Machine Learning - AI
DECEMBER 2, 2024
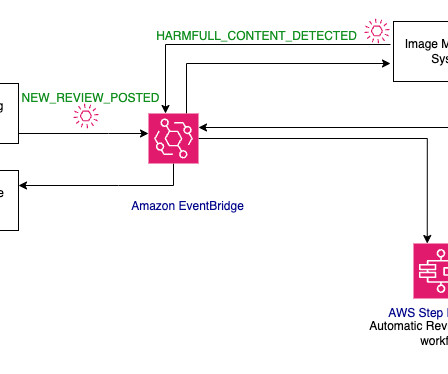
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AI models for inference. In our tests, we’ve seen substantial improvements in scaling times for generative AI model endpoints across various frameworks.











































Let's personalize your content