This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Aquarium , a startup from two former Cruise employees, wants to help companies refine their machinelearning model data more easily and move the models into production faster. One customer Sterblue offers a good example. investment to build intelligent machinelearning labeling platform. Datasaur snags $3.9M
Data scientists and AI engineers have so many variables to consider across the machinelearning (ML) lifecycle to prevent models from degrading over time. It guides users through training and deploying an informed chatbot, which can often take a lot of time and effort.
Called OpenBioML , the endeavor’s first projects will focus on machinelearning-based approaches to DNA sequencing, protein folding and computational biochemistry. Stability AI’s ethically questionable decisions to date aside, machinelearning in medicine is a minefield. Image Credits: OpenBioML.
Training a frontier model is highly compute-intensive, requiring a distributed system of hundreds, or thousands, of accelerated instances running for several weeks or months to complete a single job. For example, pre-training the Llama 3 70B model with 15 trillion training tokens took 6.5 During the training of Llama 3.1
Recent research shows that 67% of enterprises are using generative AI to create new content and data based on learned patterns; 50% are using predictive AI, which employs machinelearning (ML) algorithms to forecast future events; and 45% are using deep learning, a subset of ML that powers both generative and predictive models.
Here are just a few examples of the benefits of using LLMs in the enterprise for both internal and external use cases: Optimize Costs. Fine tuning involves another round of training for a specific model to help guide the output of LLMs to meet specific standards of an organization.
A striking example of this can already be seen in tools such as Adobe Photoshop. Before LLMs and diffusion models, organizations had to invest a significant amount of time, effort, and resources into developing custom machine-learning models to solve difficult problems. Lets look at some specific examples.
Across diverse industries—including healthcare, finance, and marketing—organizations are now engaged in pre-training and fine-tuning these increasingly larger LLMs, which often boast billions of parameters and larger input sequence length. This approach reduces memory pressure and enables efficient training of large models.
To help address the problem, he says, companies are doing a lot of outsourcing, depending on vendors and their client engagement engineers, or sending their own people to training programs. In the Randstad survey, for example, 35% of people have been offered AI training up from just 13% in last years survey.
With those tools involved, users can build new AI models on relatively low-powered machines, saving heavy-duty units for the compute-intensive process of model training. Deploying AI Many modern AI systems are capable of leveraging machine-to-machine connections to automate data ingestion and initiate responsive activity.
In these cases, the AI sometimes fabricated unrelated phrases, such as “Thank you for watching!” — likely due to its training on a large dataset of YouTube videos. Another machinelearning engineer reported hallucinations in about half of over 100 hours of transcriptions inspected.
Unfortunately, the blog post only focuses on train-serve skew. Feature stores solve more than just train-serve skew. This becomes more important when a company scales and runs more machinelearning models in production. You may, for example, want to know what values it can take. This drives computation costs.
After months of crunching data, plotting distributions, and testing out various machinelearning algorithms you have finally proven to your stakeholders that your model can deliver business value. For the sake of argumentation, we will assume the machinelearning model is periodically trained on a finite set of historical data.
Both the tech and the skills are there: MachineLearning technology is by now easy to use and widely available. So then let me re-iterate: why, still, are teams having troubles launching MachineLearning models into production? No longer is MachineLearning development only about training a ML model.
With AI models demanding vast amounts of structured and unstructured data for training, data lakehouses offer a highly flexible approach that is ideally suited to support them at scale. Then there’s the data lakehouse—an analytics system that allows data to be processed, analyzed, and stored in both structured and unstructured forms.
To regularly train models needed for use cases specific to their business, CIOs need to establish pipelines of AI-ready data, incorporating new methods for collecting, cleansing, and cataloguing enterprise information. Now with agentic AI, the need for quality data is growing faster than ever, giving more urgency to the existing trend.
It’s only as good as the models and data used to train it, so there is a need for sourcing and ingesting ever-larger data troves. But annotating and manipulating that training data takes a lot of time and money, slowing down the work or overall effectiveness, and maybe both. V7 even lays out how the two services compare.)
But that’s exactly the kind of data you want to include when training an AI to give photography tips. Conversely, some of the other inappropriate advice found in Google searches might have been avoided if the origin of content from obviously satirical sites had been retained in the training set.
The gap between emerging technological capabilities and workforce skills is widening, and traditional approaches such as hiring specialized professionals or offering occasional training are no longer sufficient as they often lack the scalability and adaptability needed for long-term success. Take cybersecurity, for example.
For example, in the digital identity field, a scientist could get a batch of data and a task to show verification results. Ive spent more than 25 years working with machinelearning and automation technology, and agentic AI is clearly a difficult problem to solve. So its a question-and-answer process.
Job titles like data engineer, machinelearning engineer, and AI product manager have supplanted traditional software developers near the top of the heap as companies rush to adopt AI and cybersecurity professionals remain in high demand. An example of the new reality comes from Salesforce.
These powerful models, trained on vast amounts of data, can generate human-like text, answer questions, and even engage in creative writing tasks. However, training and deploying such models from scratch is a complex and resource-intensive process, often requiring specialized expertise and significant computational resources.
Fed enough data, the conventional thinking goes, a machinelearning algorithm can predict just about anything — for example, which word will appear next in a sentence. Given that potential, it’s not surprising that enterprising investment firms have looked to leverage AI to inform their decision-making.
Kakkar and his IT teams are enlisting automation, machinelearning, and AI to facilitate the transformation, which will require significant innovation, especially at the edge. For example, for its railway equipment business, Escorts Kubota produces IoT-based devices such as brakes and couplers.
A 2020 IDC survey found that a shortage of data to train AI and low-quality data remain major barriers to implementing it, along with data security, governance, performance and latency issues. “The main challenge in building or adopting infrastructure for machinelearning is that the field moves incredibly quickly.
Wetmur says Morgan Stanley has been using modern data science, AI, and machinelearning for years to analyze data and activity, pinpoint risks, and initiate mitigation, noting that teams at the firm have earned patents in this space. I am excited about the potential of generative AI, particularly in the security space, she says.
Machinelearning can provide companies with a competitive advantage by using the data they’re collecting — for example, purchasing patterns — to generate predictions that power revenue-generating products (e.g. e-commerce recommendations). One of its proponents is Mike Del Balso, the CEO of Tecton.
Our LLM was built on EXLs 25 years of experience in the insurance industry and was trained on more than a decade of proprietary claims-related data. Our EXL Insurance LLM is consistently achieving a 30% improvement in accuracy on insurance-related tasks over the top pre-trained models, such as GPT4, Claude, and Gemini.
I don’t have any experience working with AI and machinelearning (ML). We also read Grokking Deep Learning in the book club at work. Seeing a neural network that starts with random weights and, after training, is able to make good predictions is almost magical. But it is hard to get machines to do it.
Fine-tuning is a powerful approach in natural language processing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. Tools and APIs – For example, when you need to teach Anthropic’s Claude 3 Haiku how to use your APIs well.
This, of course, is where machinelearning come into play. “We For example, if a company receives hundreds or thousands of emails from partners and customers with attachments every day, someone typically has to download the attachment, look at it and then decide what to do with it,” explains Keil.
According to Gartner, 30% of all AI cyberattacks in 2022 will leverage these techniques along with data poisoning, which involves injecting bad data into the dataset used to train models to attack AI systems. In fact, at HiddenLayer, we believe we’re not far off from seeing machinelearning models ransomed back to their organizations.”
Training large language models (LLMs) models has become a significant expense for businesses. PEFT is a set of techniques designed to adapt pre-trained LLMs to specific tasks while minimizing the number of parameters that need to be updated. You can also customize your distributed training.
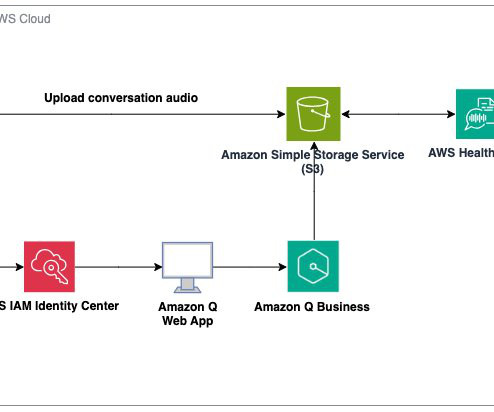
With the advent of generative AI and machinelearning, new opportunities for enhancement became available for different industries and processes. AWS HealthScribe combines speech recognition and generative AI trained specifically for healthcare documentation to accelerate clinical documentation and enhance the consultation experience.
The use of synthetic data to train AI models is about to skyrocket, as organizations look to fill in gaps in their internal data, build specialized capabilities, and protect customer privacy, experts predict. Gartner, for example, projects that by 2028, 80% of data used by AIs will be synthetic, up from 20% in 2024.
For example, organizations that build an AI solution using Open AI need to consider more than the AI service. For example, Mosaic recently created a data-heavy Mosaic GPT safety model for mining operations on Microsofts Bing platform, and is about to roll that out in a pilot. Adding vaults is needed to secure secrets. But should you?
This turnaround is not surprising, with Goldman Sachs Research , for example, predicting that the humanoid robot market could reach $38 billion by 2035 a six-fold increase over earlier estimates. Cosmos enables AI models to simulate environments and generate real-world scenarios, accelerating training for humanoid robots.
Smart Snippet Model in Coveo The Coveo MachineLearning Smart Snippets model shows users direct answers to their questions on the search results page. Navigate to Recommendations : In the left-hand menu, click “models” under the “MachineLearning” section. These snippets highlight key information that matches their query.
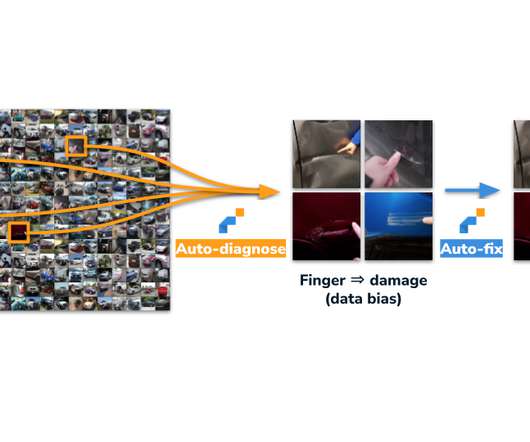
LatticeFlow , a startup that was spun out of Zurich’s ETH in 2020, helps machinelearning teams improve their AI vision models by automatically diagnosing issues and improving both the data and the models themselves. LatticeFlow uncovers a bias in data for training car damage inspection AI models.
For example, Asanas cybersecurity team has used AI Studio to help reduce alert fatigue and free up the amount of busy work the team had previously spent on triaging alerts and vulnerabilities. Then it is best to build an AI agent that can be cross-trained for this cross-functional expertise and knowledge, Iragavarapu says.
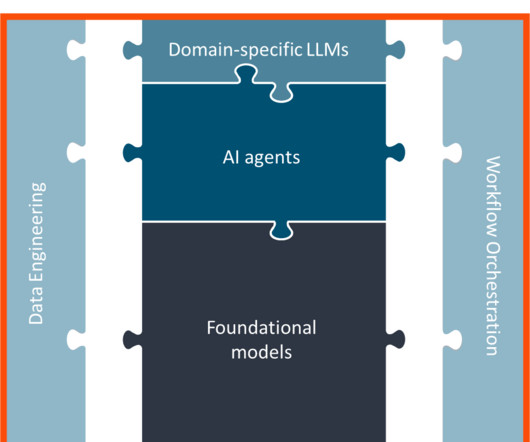
Demystifying RAG and model customization RAG is a technique to enhance the capability of pre-trained models by allowing the model access to external domain-specific data sources. Unlike fine-tuning, in RAG, the model doesnt undergo any training and the model weights arent updated to learn the domain knowledge.
Shrivastava, who has a mathematics background, was always interested in artificial intelligence and machinelearning, especially rethinking how AI could be developed in a more efficient manner. It was when he was at Rice University that he looked into how to make that work for deep learning.
Tuning model architecture requires technical expertise, training and fine-tuning parameters, and managing distributed training infrastructure, among others. Its a familiar NeMo-style launcher with which you can choose a recipe and run it on your infrastructure of choice (SageMaker HyperPod or training). recipes=recipe-name.
For example, a retailer might scale up compute resources during the holiday season to manage a spike in sales data or scale down during quieter months to save on costs. For example, data scientists might focus on building complex machinelearning models, requiring significant compute resources.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content