This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One of the key differences between the approach in this post and the previous one is that here, the Application LoadBalancers (ALBs) are private, so the only element exposed directly to the Internet is the Global Accelerator and its Edge locations. In the following sections we will review this step-by-step region evacuation example.
The AWS Command Line Interface (AWS CLI) installed eksctl kubectl docker In this post, the examples use an inf2.48xlarge instance; make sure you have a sufficient service quota to use this instance. As a result, traffic won’t be balanced across all replicas of your deployment.
For example, if a company’s e-commerce website is taking too long to process customer transactions, a causal AI model determines the root cause (or causes) of the delay, such as a misconfigured loadbalancer. First, a brief description of these three types of AI: Causal AI analyzes data to infer the root causes of events.
It contains services used to onboard, manage, and operate the environment, for example, to onboard and off-board tenants, users, and models, assign quotas to different tenants, and authentication and authorization microservices. You can use AWS services such as Application LoadBalancer to implement this approach.
For example, DeepSeek-V3 is a 671-billion-parameter model, but only 37 billion parameters (approximately 5%) are activated during the output of each token. Additionally, SageMaker endpoints support automatic loadbalancing and autoscaling, enabling your LLM deployment to scale dynamically based on incoming requests.
For example, MaestroQA offers sentiment analysis for customers to identify the sentiment of their end customer during the support interaction, enabling MaestroQAs customers to sort their interactions and manually inspect the best or worst interactions. For example, Can I speak to your manager?
The examples will be presented as Google Cloud Platform (GCP) resources, but can in most cases be inferred to other public cloud vendors. This setup will adopt the usage of cloud loadbalancing, auto scaling and managed SSL certificates. Network This example will use the same network as from the previous example.
PostgreSQL 16 has introduced a new feature for loadbalancing multiple servers with libpq, that lets you specify a connection parameter called load_balance_hosts. You can use query-from-any-node to scale query throughput, by loadbalancing connections across the nodes. Postgres 16 support in Citus 12.1
So this was an example in terms of operating systems. So in the second example, The cost will be too lower than building a new PC. Loadbalancing – you can use this to distribute a load of incoming traffic on your virtual machine. The second option is creating a virtual machine with that much computing power.
CloudWatch metrics can be a very useful source of information for a number of AWS services that dont produce telemetry as well as instrumented code. There are also a number of useful metrics for non-web-request based functions, like metrics on concurrent database requests. New to Honeycomb? Get your free account today!
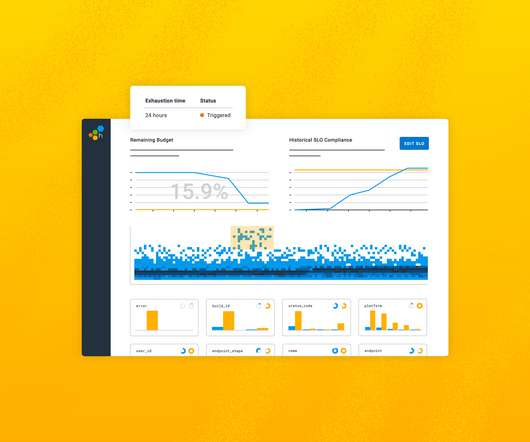
Honeycomb’s SLOs allow teams to define, measure, and manage reliability based on real user impact, rather than relying on traditional system metrics like CPU or memory usage. Instead, they consolidate logs, metrics, and traces into a unified workflow.
As an example, the OWASP Top 10 for LLMs can serve as a comprehensive framework for identifying and addressing critical AI vulnerabilities. For example, you can specify input features such as gender or age, and SageMaker Clarify will run an analysis job to detect imbalances in those features.
Most successful organizations base their goals on improving some or all of the DORA or Accelerate metrics. DORA metrics are used by DevOps teams to measure their performance and find out whether they are “low performers” to “elite performers.” You want to maximize your deployment frequency while minimizing the other metrics.
It includes rich metrics for understanding the volume, path, business context, and performance of flows traveling through Azure network infrastructure. For example, Express Route metrics include data about inbound and outbound dropped packets.
Observability starts by collecting system telemetry data, such as logs, metrics, and traces. To gain a more complete picture, observability tools collect data from various components of the software system: logs, metrics, and traces (typically considered the “three pillars of observability” but don’t get us started on that rant ).
Additionally, you can access device historical data or device metrics. The device metrics are stored in an Athena DB named "iot_ops_glue_db" in a table named "iot_device_metrics". It is hosted on Amazon Elastic Container Service (Amazon ECS) with AWS Fargate , and it is accessed using an Application LoadBalancer.
For example, you can score your initiatives according to reach, impact, confidence, and effort factors. They must track key metrics, analyze user feedback, and evolve the platform to meet customer expectations. For example, it represents GDPR for data privacy, HIPAA for healthcare data, SOC 2 for service security, and many more.
For example, a 16-core box connecting to an 800-server origin would have 12,800 connections. It seems like a minor change, but it had to be seamlessly integrated into our existing metrics and connection bookkeeping. Below is an example of what the binary Van der Corput sequence looks like. In this example, each subset has 0.25
LoadBalancer Client If any microservice has more demand, then we allow the creation of multiple instances dynamically. In that situation, to pick up the right instance with less Load Factor from other microservices, we use a LoadBalancer Client (LBC) like Ribbon, Feign Client, HTTP LoadBalancer, etc.
When evaluating solutions, whether to internal problems or those of our customers, I like to keep the core metrics fairly simple: will this reduce costs, increase performance, or improve the network’s reliability? It’s often taken for granted by network specialists that there is a trade-off among these three facets. Resiliency.
An important part of ensuring a system is continuing to run properly is around gathering relevant metrics about the system so that they can either have alerts triggered on them, or graphed to aid diagnosing problems. The metrics are stored in blocks encompassing a configured period of time (by default 2 hours). Introduction.
Common monitoring metrics are latency, packet loss, and jitter. But these metrics usually are at an individual service level, like a particular internet gateway or loadbalancer. The outcome of having metrics and logging at the service level is the difficulty of tracing through the system.
Which loadbalancer should you pick and how should it be configured? Figure 1: CDF-PC takes care of everything you need to provide stable, secure, scalable endpoints including loadbalancers, DNS entries, certificates and NiFi configuration. Who manages certificates and configures the source system and NiFi correctly?
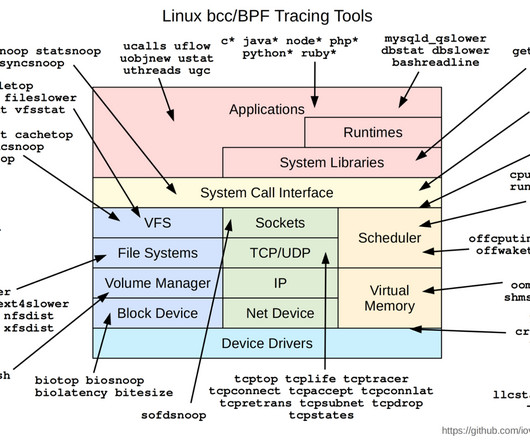
For example, developers often write programs in C or Rust compiled with clang, which is part of the LLVM toolchain, into usable bytecode. This is a simple example, but eBPF bytecode can perform much more complex operations. Typically, eBPF programs are written to bytecode using some other language.
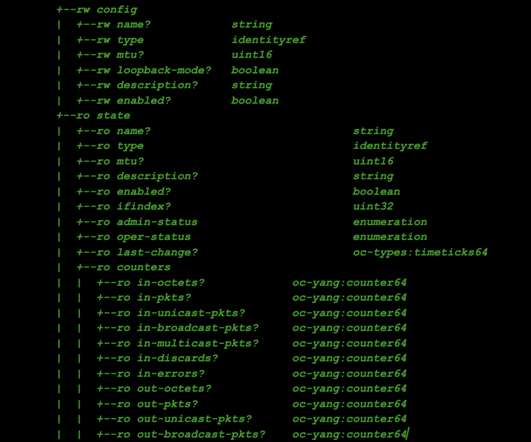
In order to design, operate, and measure these networks, we must collect metrics and state data from the thousands of devices that compose them. For example, Arista’s EOS provides eAPI, a RESTful service using JSON payloads. Here is a example of what some of these leaves may look like: Tree example generated by pyang.
Get the latest on the Hive RaaS threat; the importance of metrics and risk analysis; cloud security’s top threats; supply chain security advice for software buyers; and more! . Yes, keeping tabs on, for example, the number of patched systems and the percentage of trained staffers is a good start. What would this look like?
And that’s just a simple micro example. LoadBalancers – AWS Elastic LoadBalancers (ELB) cannot be stopped (or parked), so to avoid getting billed for the time you need to remove it. The same can be said for Azure LoadBalancer and GCP LoadBalancers. One hundred instances?
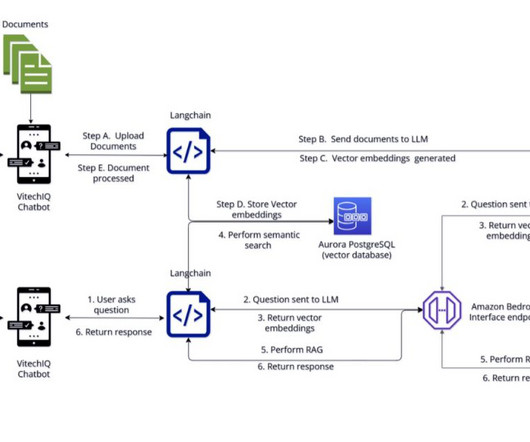
To serve their customers, Vitech maintains a repository of information that includes product documentation (user guides, standard operating procedures, runbooks), which is currently scattered across multiple internal platforms (for example, Confluence sites and SharePoint folders). Your primary functions are: 1.
In the deployment phase, you can still run regression tests — for example, to verify performance in a stress test. Another technique is to use a loadbalancer for dividing traffic among multiple running instances. They have services that implicitly use a loadbalancer while offering an explicit loadbalancer, too.
For example, do you need an Amazon ELB, NLB, or ALB, or are you using a GCP L4 or (HTTPS-friendly) L7 loadbalancer? You can deploy a new service to the cluster in minutes and access this via a properly configured cloud loadbalancer and Kubernetes ingress, and view top line metrics via Prometheus.
And you find the balance of how much telemetry to sample, retaining the shape of important metrics and traces of all the errors, while dropping the rest to minimize costs. A currently-unfolding example of this is http.status_code becoming http.response.status_code. You build up alerts based on those errors.
For example, on Ubuntu, you can use the following commands: Once Cassandra is installed, edit the `cassandra.yaml` configuration file located in the `/etc/cassandra/` directory: In the `cassandra.yaml` file, update the following properties to configure the new node: – cluster_name: Set the name of your Cassandra cluster.
A part of the “service level” family , an SLO is a reliability target (for example, “99%”) driven by an SLI (which is a metric like “requests completed without error”) that organizations use to ensure user experiences are smooth and customer contracts are being met. Can we express this in clear language with common-sense metrics?
As your traffic rises and falls, you can set up auto-scaling on a specific metric (e.g., Therefore, you can bring the number of containers up or down in response to fluctuations in the selected metric. For example, when using EC2, you can have multiple Docker tasks and containers running on that single instance.
For example, the Kubernetes documentation suggests using multiple “track” labels, such as “stable” and “canary”, in addition to the common identifying Service selector labels (e.g. Instead of relying on a round robin loadbalancing implementation, the smart proxy can direct a specified percentage of Service requests to each Deployment.
Decompose these into quantifiable KPIs to direct the project, utilizing metrics like migration duration, savings on costs, and enhancements in performance. For example, transitioning from an on-premises CRM to a cloud-based option such as Salesforce operating on AWS. lowering costs, enhancing scalability).
For example, an organization might create separate deployments for different business units, projects, or applications, each with its own dedicated resources and data. Availability ECE provides features such as automatic failover and loadbalancing, which can help ensure high availability and minimize downtime.
This bursting is intentional and guided by state-of-the-art monitoring and metrics to know exactly which tiers of the application need to be scaled to maintain SLA’s (Service Level Agreements). Federating Metrics. Aggregating metrics from diverse nodes is feasible with tooling such as Prometheus. Machine Learning.
These are all examples of instability with our network and its adverse effects on application performance. But notice all of these examples start with “why.” We have flow records, security tags, SNMP metrics, VPC flow logs, eBPF metrics, threat feeds, routing tables, DNS mappings, geo-id information, etc.
For example, developers can use observability to determine when an application performance issue occurs and pinpoint specific areas of code or instances where it happens. By monitoring the metrics of running systems, developers can detect when these systems begin to deviate from normal behavior. Observability makes this possible.
It is also important to detect when services are not available (for example when a service is compulsorily terminated or health checking isn’t operational). Consul is quite flexible and the monitoring system has numerous metrics. We can even choose metrics for monitoring containers. .
And it supports like an extensible set of metric services and judges and cloud platforms and everything else. But that’s one example, but we have lots of ideas like that. But looking at this diagram, this is again, it’s an example, but this is a pretty typical deployment pattern for say a microservice.
From a high-level perspective, network operators engage in network capacity planning to understand some key network metrics: Types of network traffic. Measure and analyze traffic metrics to establish performance and capacity baselines for future bandwidth consumption. Key metrics for planning network capacity.
That said, the only way to get that 50% cost reduction is to install the AWS CloudWatch Agent on your instances and configure it to send memory metrics to CloudWatch. If you are not running the agent…then no memory metrics. Examples of such applications include fraud detection and image or speech recognition.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content