This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With Cloud getting a more prominent place in the digital world and with that Cloud Service Providers (CSP), it triggered the question on how secure our data with Google Cloud actually is when looking at their Cloud LoadBalancing offering. During threat modelling, the SSL LoadBalancing offerings often come into the picture.
Recently I was wondering if I could deploy a Google-managed wildcard SSL certificate on my Global External HTTPS LoadBalancer. In this blog, I will show you step by step how you can deploy a Global HTTPS LoadBalancer using a Google-managed wildcard SSL certificate.
It is therefore important to distribute the load between those instances. The component that does this is the loadbalancer. Spring provides a Spring Cloud LoadBalancer library. In this article, you will learn how to use it to implement client-side loadbalancing in a Spring Boot project.
The just-announced general availability of the integration between VM-Series virtual firewalls and the new AWS Gateway LoadBalancer (GWLB) introduces customers to massive security scaling and performance acceleration – while bypassing the awkward complexities traditionally associated with inserting virtual appliances in public cloud environments.
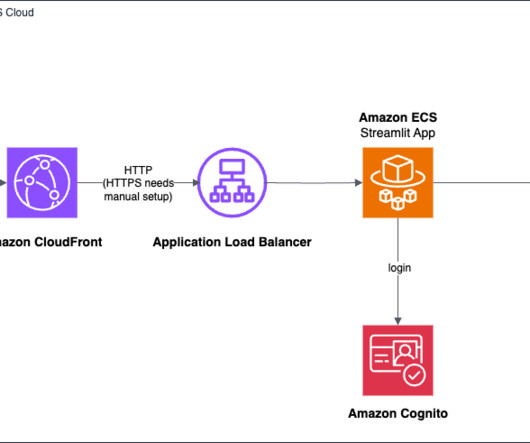
The custom header value is a security token that CloudFront uses to authenticate on the loadbalancer. For example, let’s say you want to add a button to invoke the LLM answer instead of invoking it automatically when the user enters input text. Choose a different stack name for each application. See the README.md
One of the key differences between the approach in this post and the previous one is that here, the Application LoadBalancers (ALBs) are private, so the only element exposed directly to the Internet is the Global Accelerator and its Edge locations. In the following sections we will review this step-by-step region evacuation example.
The AWS Command Line Interface (AWS CLI) installed eksctl kubectl docker In this post, the examples use an inf2.48xlarge instance; make sure you have a sufficient service quota to use this instance. As a result, traffic won’t be balanced across all replicas of your deployment.
For example, if a company’s e-commerce website is taking too long to process customer transactions, a causal AI model determines the root cause (or causes) of the delay, such as a misconfigured loadbalancer. First, a brief description of these three types of AI: Causal AI analyzes data to infer the root causes of events.
For example, you could make a group called developers. I am using an Application LoadBalancer to invoke a Lambda function. In this case, we can use the native Cognito integration of the application loadbalancer. The loadbalancer will now invoke the target group with the request.
The examples will be presented as Google Cloud Platform (GCP) resources, but can in most cases be inferred to other public cloud vendors. This setup will adopt the usage of cloud loadbalancing, auto scaling and managed SSL certificates. Network This example will use the same network as from the previous example.
Find the full example on GitHub. Return load-balanced traffic to the Source VPC The Squid Proxy uses an internal Network LoadBalancer to balance requests. An internal passthrough Network LoadBalancer routes connections directly from clients to the healthy backends, without any interruption.
Find the full example on GitHub. Return load-balanced traffic to the Source VPC The NGINX gateway uses an internal Network LoadBalancer to balance requests. An internal passthrough Network LoadBalancer routes connections directly from clients to the healthy backends, without any interruption.
It contains services used to onboard, manage, and operate the environment, for example, to onboard and off-board tenants, users, and models, assign quotas to different tenants, and authentication and authorization microservices. You can use AWS services such as Application LoadBalancer to implement this approach.
Take for example the ability to interact with various cloud services such as Cloud Storage, BigQuery, Cloud SQL, etc. For ingress access to your application, services like Cloud LoadBalancer should be preferred and for egress to the public internet a service like Cloud NAT. They can also be combined with other Access Levels.
The easiest way to use Citus is to connect to the coordinator node and use it for both schema changes and distributed queries, but for very demanding applications, you now have the option to loadbalance distributed queries across the worker nodes in (parts of) your application by using a different connection string and factoring a few limitations.
PostgreSQL 16 has introduced a new feature for loadbalancing multiple servers with libpq, that lets you specify a connection parameter called load_balance_hosts. You can use query-from-any-node to scale query throughput, by loadbalancing connections across the nodes. The coordinator is in port 9700 in this example.
Backends are based on a loadbalancer. Find the full example on GitHub. Endpoints are based on a forwarding rule. Previous figure shows an Endpoint-based connection. Services are published using a service attachment. Allow all HTTP traffic, use a more fine-grained setup in production.
For example, MaestroQA offers sentiment analysis for customers to identify the sentiment of their end customer during the support interaction, enabling MaestroQAs customers to sort their interactions and manually inspect the best or worst interactions. For example, Can I speak to your manager?
Public Application LoadBalancer (ALB): Establishes an ALB, integrating the previous SSL/TLS certificate for enhanced security. As an example, we’ll use “ subdomain-1.cloudns.ph” Example values: ns-123.awsdns-00.com. Make sure to replace the example domain with your own. e.g., “subdomain-2.subdomain-1.cloudns.ph”
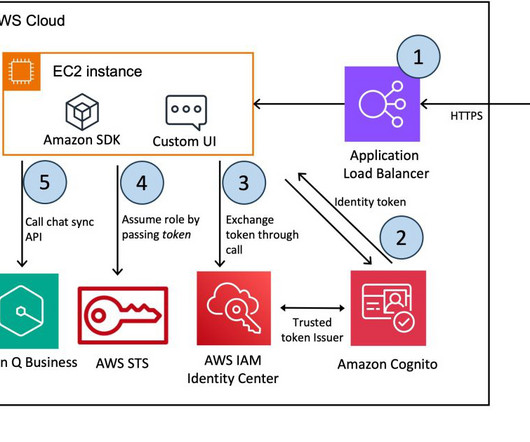
With this solution, you can interact directly with the chat assistant powered by AWS from your Google Chat environment, as shown in the following example. On the Configuration tab, under Application info , provide the following information, as shown in the following screenshot: For App name , enter an app name (for example, bedrock-chat ).
The workflow includes the following steps: The user accesses the chatbot application, which is hosted behind an Application LoadBalancer. Provide the following parameters for the stack: Stack name – The name of the CloudFormation stack (for example, AmazonQ-UI-Demo ). The following diagram illustrates the solution architecture.
This post will show how this can be achieved using a K8s ingress controller and loadbalancer. This example uses the same setup as last time around: virtual machines running under the default Windows Hypervisor (Hyper-V). To make room for the addition of a proxy each VM had to give up some RAM.
LoadBalancer Client Component (Good, Perform LoadBalancing). Feign Client Component (Best, Support All Approached, and LoadBalancing). However, we desire one instance of the target microservice (producer microservice) that has a lower load factor. Loadbalancing is not feasible].
For example, you might add more CPU or RAM to your server. For example, you might deploy three copies of your server instead of one and then place them all behind a loadbalancer that handles routing the traffic to each of them. Vertical scaling means making a single resource bigger or more powerful.
Use the AWS account id that you took note of earlier, the user name you set up (filmappuser, in my example), and the password you set for management console access. When the web application starts in its ECS task container, it will have to connect to the database task container via a loadbalancer. Enter a value: yes.
However, if you already have a cloud account and host the web services on multiple computes with/without a public loadbalancer, then it makes sense to migrate the DNS to your cloud account.
Take the API gateway use case as an example, there are two key personas involved: the platform engineers, who want to set appropriate guardrails to minimize incidents and maximize their security posture, and the developers, who want to release services and functionality rapidly and configure API endpoints dynamically.
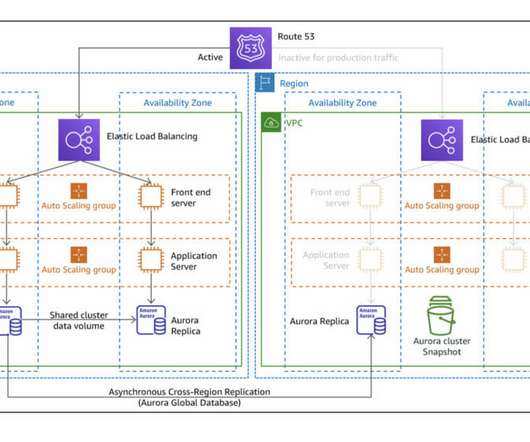
This post explores a proof-of-concept (PoC) written in Terraform , where one region is provisioned with a basic auto-scaled and load-balanced HTTP * basic service, and another recovery region is configured to serve as a plan B by using different strategies recommended by AWS. Pilot Light strategy diagram. Strategies.
Applications and services, network gateways and loadbalancers, and even third-party services? What are some examples of complex architectures that could have been simplified? Teams that practice evolutionary design start with “the simplest thing that could possibly work” and evolve their design from there. About the Book Club.
An example of this use case is a flow that utilizes the ConsumeKafka and PutHDFS processors. An example of this use case is a flow that utilizes the QueryDatabaseTableRecord and PutKudu processors. An example of this use case is a flow that utilizes the ListenHTTP and PutHDFS processors.
So this was an example in terms of operating systems. So in the second example, The cost will be too lower than building a new PC. Loadbalancing – you can use this to distribute a load of incoming traffic on your virtual machine. The second option is creating a virtual machine with that much computing power.
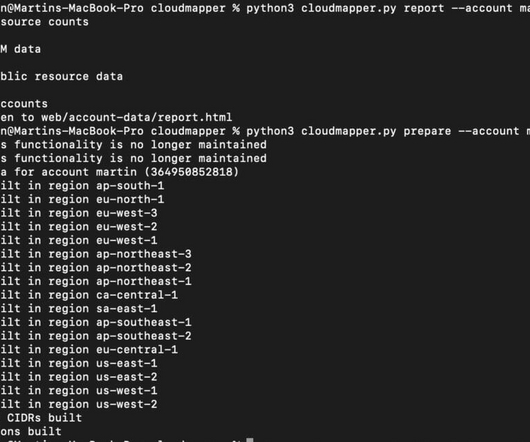
One for my Disaster Recovery blog post ( vpc_demo ) depicting an ASG and two loadbalancers on different AZs. Also, you can see that the loadbalancers are exposed to the Internet. For example, an S3 endpoint has the same icon as an S3 actual bucket. python cloudmapper.py Icons have limited capability.
For example, DeepSeek-V3 is a 671-billion-parameter model, but only 37 billion parameters (approximately 5%) are activated during the output of each token. Additionally, SageMaker endpoints support automatic loadbalancing and autoscaling, enabling your LLM deployment to scale dynamically based on incoming requests.
For example, a 16-core box connecting to an 800-server origin would have 12,800 connections. We had discussed subsetting many times over the years, but there was concern about disrupting loadbalancing with the algorithms available. Below is an example of what the binary Van der Corput sequence looks like.
For example, you can score your initiatives according to reach, impact, confidence, and effort factors. For example, it represents GDPR for data privacy, HIPAA for healthcare data, SOC 2 for service security, and many more. It must be tested under different conditions so it is prepared to perform well even in peak loads.
This resembles a familiar concept from Elastic LoadBalancing. A target group can refer to Instances, IP addresses, a Lambda function or an Application LoadBalancer. For example, there would be no cross-VPC SSH or RDP traffic. To connect a service to target workloads, you use the concept of Target Groups.
Heres an example of using Python Tutor to step through a recursive function that builds up a linked list of Python tuples. When you hit Send here, the AI tutor responds with something like: Note that when the AI generates code examples, theres a Visualize Me button underneath each one so that you can directly visualize it in Python Tutor.
Highly available networks are resistant to failures or interruptions that lead to downtime and can be achieved via various strategies, including redundancy, savvy configuration, and architectural services like loadbalancing. Resiliency. Resilient networks can handle attacks, dropped connections, and interrupted workflows.
Let’s take an example. Network flapping is a good mechanism for traffic control, but sometimes the router is unnecessarily configured to load-balance, thus they started unwanted flapping. And if the dynamic router continuously repeats the thing, then the overall network may be disturbed. This is called Route Summarization.
A good example of this complexity is with IP Whitelisting. One of our customers wanted us to crawl from a fixed IP address so that they could whitelist that IP for high-rate crawling without being throttled by their loadbalancer. He provided an example that ended up looking like this: View the code on Gist.
LoadBalancer Client If any microservice has more demand, then we allow the creation of multiple instances dynamically. In that situation, to pick up the right instance with less Load Factor from other microservices, we use a LoadBalancer Client (LBC) like Ribbon, Feign Client, HTTP LoadBalancer, etc.
What Youll Learn How Pulumi works with AWS Setting up Pulumi with Python Deploying various AWS services with real-world examples Best practices and advanced tips Why Pulumi for AWS? The goal is to deploy a highly available, scalable, and secure architecture with: Compute: EC2 instances with Auto Scaling and an Elastic LoadBalancer.
No need to worry about licensing, loadbalancing, and rate limits when these five amazing APIs provide you everything you need! exchangeratesapi. Having reliable exchange rate data is critical to maintaining a global eCommerce or financial website. Not only is real time exchange rate data important, but so is historical data.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content