This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post presents a solution where you can upload a recording of your meeting (a feature available in most modern digital communication services such as Amazon Chime ) to a centralized video insights and summarization engine. This post provides guidance on how you can create a video insights and summarization engine using AWS AI/ML services.
To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. We walk you through our solution, detailing the core logic of the Lambda functions. Amazon S3 invokes the {stack_name}-create-batch-queue-{AWS-Region} Lambda function.
The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket. The Lambda function runs the database query against the appropriate OpenSearch Service indexes, searching for exact matches or using fuzzy matching for partial information.
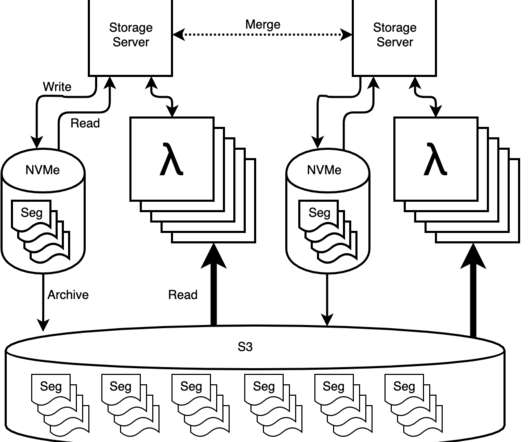
When we introduced Secondary Storage two years ago, it was a deliberate compromise between economy and performance. Compared to Honeycomb’s primary NVMe storage attached to dedicated servers, secondary storage let customers keep more data for less money. Enter AWS Lambda. Today things look very different.
Enhancing AWS Support Engineering efficiency The AWS Support Engineering team faced the daunting task of manually sifting through numerous tools, internal sources, and AWS public documentation to find solutions for customer inquiries. To handle large volumes, the data is split into smaller chunks to mitigate Lambda function overload.
Introduction With an ever-expanding digital universe, data storage has become a crucial aspect of every organization’s IT strategy. S3 Storage Undoubtedly, anyone who uses AWS will inevitably encounter S3, one of the platform’s most popular storage services. Storage Class Designed For Retrieval Change Min.
The following is a review of the book Fundamentals of Data Engineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a data engineer.
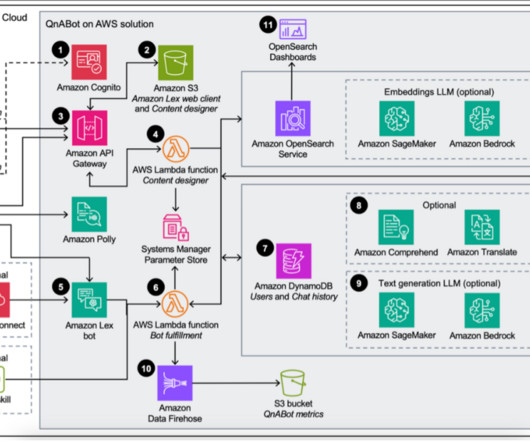
The solution also uses Amazon Cognito user pools and identity pools for managing authentication and authorization of users, Amazon API Gateway REST APIs, AWS Lambda functions, and an Amazon Simple Storage Service (Amazon S3) bucket. To launch the solution in a different Region, change the aws_region parameter accordingly.
AI-powered email processing engine – Central to the solution, this engine uses AI to analyze and process emails. The AI engine accesses this resource to pull relevant information needed to effectively address customer inquiries. When a customer sends an email, WorkMail receives it and invokes the next component in the workflow.
The solution consists of the following steps: Relevant documents are uploaded and stored in an Amazon Simple Storage Service (Amazon S3) bucket. The text extraction AWS Lambda function is invoked by the SQS queue, processing each queued file and using Amazon Textract to extract text from the documents.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. Prompt engineering is typically an iterative process, and teams experiment with different techniques and prompt structures until they reach their target outcomes. They’re illustrated in the following figure.
This post was co-written with Vishal Singh, Data Engineering Leader at Data & Analytics team of GoDaddy Generative AI solutions have the potential to transform businesses by boosting productivity and improving customer experiences, and using large language models (LLMs) in these solutions has become increasingly popular.
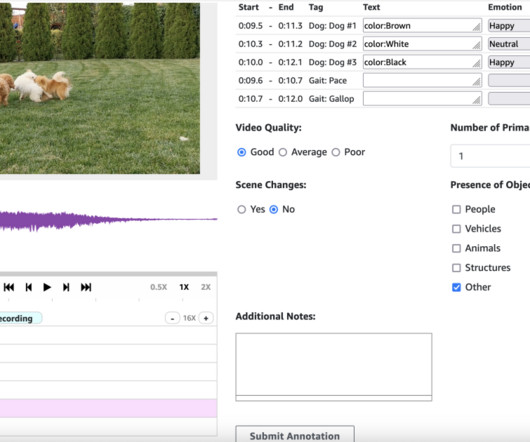
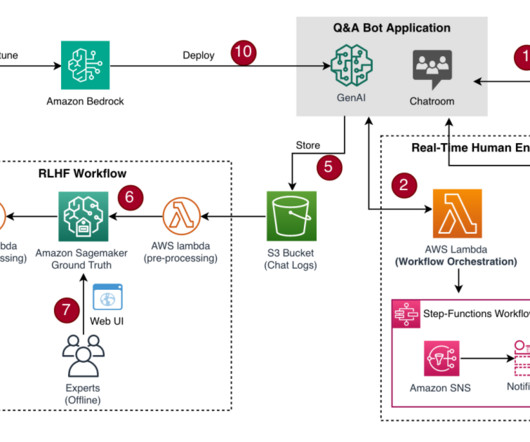
At its core, Amazon Simple Storage Service (Amazon S3) serves as the secure storage for input files, manifest files, annotation outputs, and the web UI components. Pre-annotation and post-annotation AWS Lambda functions are optional components that can enhance the workflow. On the SageMaker console, choose Create labeling job.
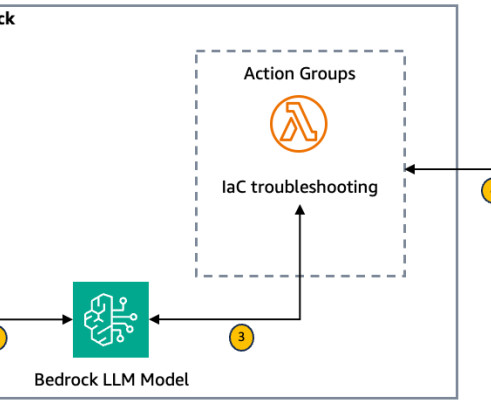
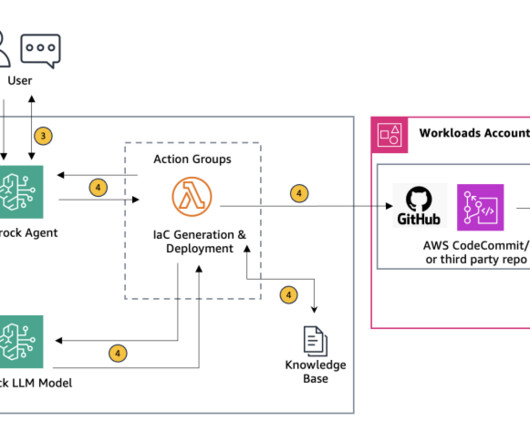
Error retrieval and context gathering The Amazon Bedrock agent forwards these details to an action group that invokes the first AWS Lambda function (see the following Lambda function code ). This contextual information is then sent back to the first Lambda function. Provide the troubleshooting steps to the user.
Flexible logging –You can use this solution to store logs either locally or in Amazon Simple Storage Service (Amazon S3) using Amazon Data Firehose, enabling integration with existing monitoring infrastructure. Yanyan graduated from Texas A&M University with a PhD in Electrical Engineering.
Customizable Uses prompt engineering , which enables customization and iterative refinement of the prompts used to drive the large language model (LLM), allowing for refining and continuous enhancement of the assessment process. The WAFR reviewer, based on Lambda and AWS Step Functions , is activated by Amazon SQS.
It enables you to privately customize the FM of your choice with your data using techniques such as fine-tuning, prompt engineering, and retrieval augmented generation (RAG) and build agents that run tasks using your enterprise systems and data sources while adhering to security and privacy requirements.
Audio-to-text transcription The recorded audio files are securely transmitted to a speech-to-text engine, which converts the spoken words into text format. Data consolidation The transcribed patient reports are consolidated into a structured database, enabling efficient storage, retrieval, and analysis. Choose Test. Choose Test.
Traditionally, cloud engineers learning IaC would manually sift through documentation and best practices to write compliant IaC scripts. Additionally, it offers beginner cloud engineers initial script drafts as standard templates to build upon, facilitating their IaC learning journey. Access to Amazon Bedrock models.
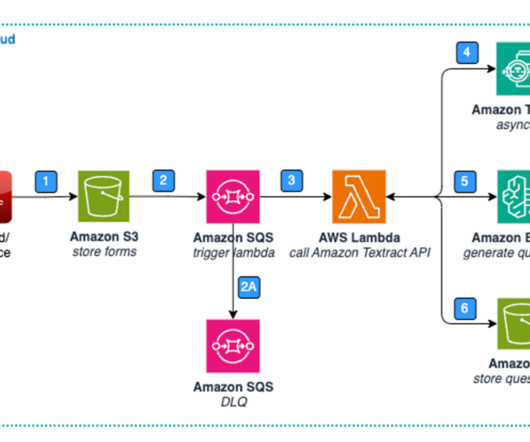
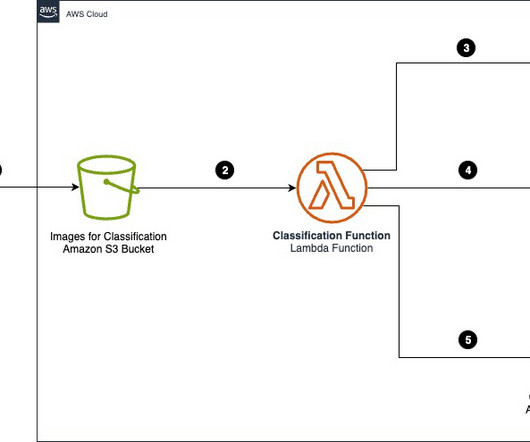
Part 1: Standard forms: Data extraction and storage The following diagram highlights the key elements of a solution for data extraction and storage with standard forms. Figure 1: Architecture – Standard Form – Data Extraction & Storage. Lastly, the Lambda function stores the question list in Amazon S3.
Agents for Amazon Bedrock automates the prompt engineering and orchestration of user-requested tasks. Diagram analysis and query generation : The Amazon Bedrock agent forwards the architecture diagram location to an action group that invokes an AWS Lambda. This gives your agent access to required services, such as Lambda.
In this post, we show you how to build a speech-capable order processing agent using Amazon Lex, Amazon Bedrock, and AWS Lambda. A Lambda function pulls the appropriate prompt template from the Lambda layer and formats model prompts by adding the customer input in the associated prompt template. awscli>=1.29.57
After being in cloud and leveraging it better, we are able to manage compute and storage better ourselves,” said the CIO, who notes that vendors are not cutting costs on licenses or capacity but are offering more guidance and tools. He went with cloud provider Wasabi for those storage needs. “We
Conversational artificial intelligence (AI) assistants are engineered to provide precise, real-time responses through intelligent routing of queries to the most suitable AI functions. For direct device actions like start, stop, or reboot, we use the action-on-device action group, which invokes a Lambda function. Anthropic Claude v2.1
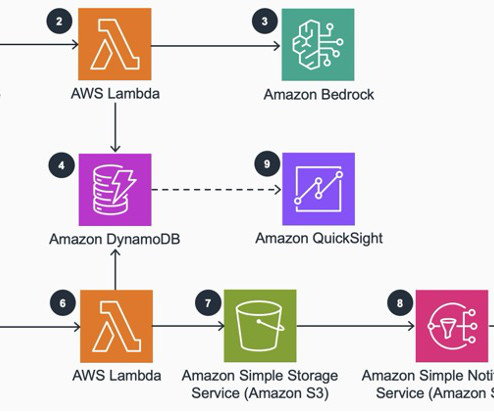
In this post, we demonstrate a few metrics for online LLM monitoring and their respective architecture for scale using AWS services such as Amazon CloudWatch and AWS Lambda. Amazon Bedrock saves the request and completion (response) in Amazon Simple Storage Service (Amazon S3) as the per configuration of invocation logging.
Scaling and State This is Part 9 of Learning Lambda, a tutorial series about engineering using AWS Lambda. So far in this series we’ve only been talking about processing a small number of events with Lambda, one after the other. Lambda will horizontally scale precisely when we need it to a massive extent.
As the name suggests, a cloud service provider is essentially a third-party company that offers a cloud-based platform for application, infrastructure or storage services. In a public cloud, all of the hardware, software, networking and storage infrastructure is owned and managed by the cloud service provider. What Is a Public Cloud?
Get 1 GB of free storage. Try Render Vercel Earlier known as Zeit, the Vercel app acts as the top layer of AWS Lambda which will make running your applications easy. With the Google App Engine, developers can focus more on writing down code without worrying about managing its underlying infrastructure.
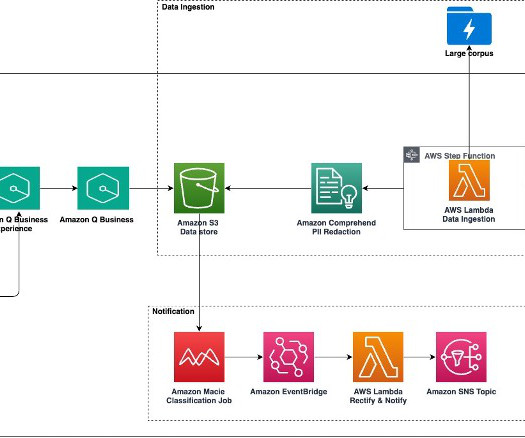
You can apply robust prompt engineering techniques to instruct the model to perform your specified actions to minimize any bias or hallucinations in the response, and have the output in the specific format required. This bucket will have event notifications enabled to invoke an AWS Lambda function to process the objects created or updated.
Solution overview The policy documents reside in Amazon Simple Storage Service (Amazon S3) storage. This action invokes an AWS Lambda function to retrieve the document embeddings from the OpenSearch Service database and present them to Anthropics Claude 3 Sonnet FM, which is accessed through Amazon Bedrock.
The raw photos are stored in Amazon Simple Storage Service (Amazon S3). Aurora MySQL serves as the primary relational data storage solution for tracking and recording media file upload sessions and their accompanying metadata. S3, in turn, provides efficient, scalable, and secure storage for the media file objects themselves.
We’re big fans of AWS Lambda at Honeycomb. As you may have read , we recently made some major improvements to our storageengine by leveraging Lambda to process more data in less time. Making a change to a complex system like our storageengine is daunting, but can be made less so with good instrumentation and tracing.
Python is used extensively among Data Engineers and Data Scientists to solve all sorts of problems from ETL/ELT pipelines to building machine learning models. Apache HBase is an effective data storage system for many workflows but accessing this data specifically through Python can be a struggle. Introduction. spark = SparkSession. .builder.
Build an offline human feedback workflow In this scenario, we assume that the chat transcripts are stored in an Amazon Simple Storage Service (Amazon S3) bucket in JSON format, a typical chat transcript format, for the human experts to provide annotations and labels on each LLM response. Here, we use the on-demand option.
Amazon Lambda : to run the backend code, which encompasses the generative logic. Amazon Simple Storage Service (S3) : for documents and processed data caching. In step 3, the frontend sends the HTTPS request via the WebSocket API and API gateway and triggers the first Amazon Lambda function.
Traditional rule engines or ML-based classification can classify the documents, but often reach a limit on types of document formats and support for the dynamic addition of a new classes of document. An Amazon S3 object notification event invokes the embedding AWS Lambda function.
These techniques include chain-of-thought prompting , zero-shot prompting , multishot prompting , few-shot prompting , and model-specific prompt engineering guidelines (see Anthropic Claude on Amazon Bedrock prompt engineering guidelines). Create and associate a Lambda function to handle the action’s logic.
Scaling and State This is Part 9 of Learning Lambda, a tutorial series about engineering using AWS Lambda. So far in this series we’ve only been talking about processing a small number of events with Lambda, one after the other. Lambda will horizontally scale precisely when we need it to a massive extent.
Here, Amazon SageMaker Ground Truth allowed ML engineers to easily build the human-in-the-loop workflow (step v). The request is then processed by AWS Lambda , which uses AWS Step Functions to orchestrate the process (step 2). Christopher de Beer is a senior software development engineer at Amazon located in Edinburgh, UK.
With prompt engineering, managed RAG workflows, and access to multiple FMs, you can provide your customers rich, human agent-like experiences with precise answers. The Content Designer AWS Lambda function saves the input in Amazon OpenSearch Service in a questions bank index.
Our data storage has two tiers: hot data, stored on the query engine hosts, and cold data, stored in S3 and queried via AWS Lambda. Hot storage is usually reserved for recent data, and cold storage for older data. That was where all the Lambda capacity was going. The incident. A resurgence, then resolution.
Our data storage has two tiers: hot data, stored on the query engine hosts, and cold data, stored in S3 and queried via AWS Lambda. Hot storage is usually reserved for recent data, and cold storage for older data. That was where all the Lambda capacity was going. The incident. A resurgence, then resolution.
The workflow consists of the following steps: The user uploads the meeting recording as an audio or video file to the project’s Amazon Simple Storage Service (Amazon S3) bucket, in the /recordings folder. About the Authors Gabriel Rodriguez Garcia is a Machine Learning engineer at AWS Professional Services in Zurich.
The integration of retrieval and generation also requires additional engineering effort and computational resources. Upload the knowledgebase-lambdalayer.zip file available under the /lambda/layer folder in the GitHub repo you cloned earlier and choose Upload. You will use this Lambda layer code later to create the Lambda function.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content