This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In our first episode of Breaking 404 , a podcast bringing to you stories and unconventional wisdom from engineering leaders of top global organizations around the globe, we caught up with Ajay Sampat , Sr. EngineeringManager, Lyft to understand the challenges that engineering teams across domains face while tackling large user traffic.
Part of the problem is that data-intensive workloads require substantial resources, and that adding the necessary compute and storage infrastructure is often expensive. Adding more infrastructure often proves to be cost prohibitive and hard to manage. Thirty-six percent cited controlling costs as their top challenge. . ”
High Density storage with PMEM on Aerospike leads to significant Capex/Opex reduction with Intel Optane DC Persistent Memory. See the presentation by Athreya Gopalakrishna, Senior EngineeringManager, PayPal and Sai Devabhaktuni, Sr.
When you send telemetry into Honeycomb, our infrastructure needs to buffer your data before processing it in our “retriever” columnar storage database. Using Apache Kafka to buffer the data between ingest and storage benefits both our customers by way of durability/reliability and our engineering teams in terms of operability.
Scale more efficiently AI can automate an array of routine tasks, ensuring consistent operations across the entire IT infrastructure, says Alok Shankar, AI engineeringmanager at Oracle Health. This scalability allows you to expand your business without needing a proportionally larger IT team.”
Umesh Mohan is a Software EngineeringManager at AWS, where he has been leading a team of talented engineers for over three years. He is passionate about serverless technologies, mobile development, leveraging Generative AI, and architecting innovative high-impact solutions.
Those are any of your databases, cloud-storages, and separate files filled with unstructured data. Data sources are the starting points of any BI system because they are connected with all the following data-integration tools, storages, and business intelligence UI. Documenting contents in a data warehouse and meta-data storage.
Dr. Daniel Duffy is head of the NASA Center for Climate Simulation (NCCS, Code 606.2), which provides high performance computing, storage, networking, and data systems designed to meet the specialized needs of the Earth science modeling communities. High Performance Computing Lead, NASA Center for Climate Simulation (NCCS). Eddie Garcia.
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE EngineeringManager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN. Thursday?—?December
Scalare in modo più efficiente L’intelligenza artificiale può automatizzare una serie di compiti di routine, garantendo operazioni coerenti nell’intera infrastruttura IT, sottolinea Alok Shankar, AI engineeringmanager di Oracle Health.
Dr. Daniel Duffy is head of the NASA Center for Climate Simulation (NCCS, Code 606.2), which provides high performance computing, storage, networking, and data systems designed to meet the specialized needs of the Earth science modeling communities. High Performance Computing Lead, NASA Center for Climate Simulation (NCCS). Eddie Garcia.
Understanding Service Accounts and Scopes on Google Compute Engine. Deploying to a Google Kubernetes Engine Cluster. Object Versioning in Google Cloud Storage. Deploying to Google Cloud App Engine. Working with Google Cloud Storage. Deploying Resources with Google Cloud Deployment Manager.
Annie Freeman, Green Software advocate and engineer at Xero, delivered a compelling speech titled “ How Software Engineers Can Help Solve Climate Change ,” while Paola E. Sasha Luccioni’s perspective on the illogicality of using AI to address environmental issues caused by activities like deforestation.
Much of Cloudera’s internal research and development infrastructure for CDP Public Cloud and CDP Private Cloud runs on compute and storage from the big three cloud providers, and at the beginning of 2020 costs were on course to top $25 million per year.
Our technical preview customers have shared the following feedback: Teranet : “ After evaluating all the major open-source storage frameworks to build our lakehouse, we chose Apache Iceberg because it’s 100% open , feature rich, and has strong community engagement. Read why the future of data lakehouses is open.
You have previously been a Senior EngineeringManager at a tech giant, Google and now you are with Citadel, a top company in the financial space. As in how different has your experience been working in the engineering teams of two different industries (Tech and FinTech)? You learn a thing best by teaching it to others.
The former extracts and transforms information before loading it into centralized storage while the latter allows for loading data prior to transformation. Developed in 2012 and officially launched in 2014, Snowflake is a cloud-based data platform provided as a SaaS (Software-as-a-Service) solution with a completely new SQL query engine.
I was curious about moving up the engineeringmanagement ladder eventually, but I assumed a VP opportunity would be out of reach for a long time, if ever. I had enough experience at early-stage startups to know that, if the company is successful, you’ll probably do a whole host of things as the company moves through different phases.
Intel Optane DC persistent memory is a new tier in the memory and storage hierarchy located between DRAM and Solid State Drives with latency closer to DRAM (see Figure 1). This is achieved through an architecture that fundamentally separates compute from storage.
Key Skills and Responsibilities for Remote DevOps Engineer. DevOps Freelance engineersmanage the delivery of new code and primarily collaborate with the IT team and developers. The Differences between AWS, Azure, and GCP Engineers. Storage AWS offers distributed, temporary (short-term) stockpiling.
8/3 – Query engine lambda startup failures : A code change was merged that prevented the lambda-based portion of our query engine from starting. This is the portion of our query engine that runs queries against S3-based storage — typically older data. We resolved the issue by rolling back to a previous release.
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE EngineeringManager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN. Thursday?—?December
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE EngineeringManager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN. Thursday?—?December
A Technical Look at CDP Data Engineering. Managed, Serverless Spark. This is made possible by running Spark on Kubernetes which provides isolation from security and resource perspective while still leveraging the common storage layer provided by SDX. Let’s take a technical look at what’s included.
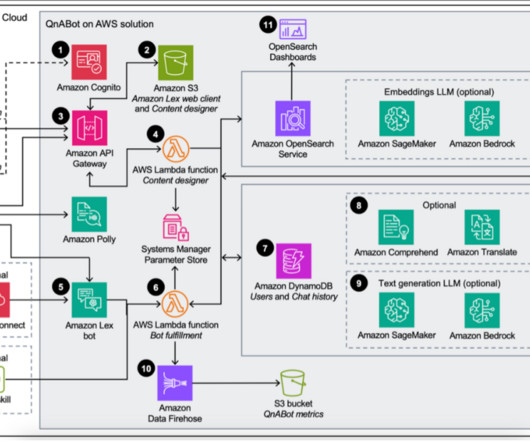
This solution uses Amazon Bedrock, Amazon Relational Database Service (Amazon RDS), Amazon DynamoDB , and Amazon Simple Storage Service (Amazon S3). Aishwarya Gupta is a Senior Data Engineer at Twilio focused on building data systems to empower business teams to derive insights.
With prompt engineering, managed RAG workflows, and access to multiple FMs, you can provide your customers rich, human agent-like experiences with precise answers. You can then retrieve your company-specific information with source attribution (such as citations) to improve transparency and minimize hallucinations.
In the last year, we have seen tremendous growth on our engineering teams. This growth forced us to rethink our engineering growth paths as well as what we needed in engineeringmanagers. One key result of this was an update to our engineering competency matrix that we published. A Hubot postscript.
TB of memory, and 24 TB of storage. The Citus coordinator node has 64 vCores, 256 GB of memory, and 1 TB of storage.). …… Marco Slot – Technical lead of the Citus database engine and Principal Engineer at Microsoft. Why Postgres? Why Postgres?
Amazon Q Business offers multiple prebuilt connectors to a large number of data sources, including Atlassian Jira, Atlassian Confluence, Amazon Simple Storage Service (Amazon S3), Microsoft SharePoint, Salesforce, and many more, and helps you create your generative AI solution with minimal configuration.
As management data increases, legacy approaches will be capable of storing an even smaller percentage of it, and will be even less able to provide the required visibility.
These powerful frameworks simplify the complexities of parallel processing, enabling you to write code in a familiar syntax while the underlying enginemanages data partitioning, task distribution, and fault tolerance. When integrating EMR Serverless in SageMaker Studio, you can configure the IAM role to be used by SageMaker Studio.
This method offers bounded padding and efficient unsharded storage, but might not always allow optimal sharding for individual parameters. Special thanks Special thanks to Gokul Nadathur (EngineeringManager at Meta), Gal Oshri (Principal Product Manager Technical at AWS) and Janosch Woschitz (Sr.
On Dec 07, 2017 Netlify EngineeringManager Shawn Erquhart wrote, “ Today we shipped Netlify CMS 1.0, All of these large media assets are backed by Netlify’s Edge – our robust and redundant cloud storage. Read more about this milestone. Netlify CMS is released. Read more about this milestone.
In between, there are data engineersmanaging the data infrastructure with ETL/ ELT processes and tools required to transform operational data into analytical ones. For example, there might be some sort of menu of available options that are provided centrally like a relational database, object storage, a NoSQL database, etc.
EngineeringManager at ShopBack. X Pack, a component of the Elastic Stack ensures secure storage and retrieval of sensitive patient data and meet HIPAA requirements. “We “Through AWS, we were using an older version of Elasticsearch and missing out on the full features and benefits of the Elastic Stack. Alberto Resco Perez.
So, you know I run a platform engineering organization now, which means that I’m thinking just a lot about distributed compute and storage and the systems that other engineers use is kind of the software that my team is providing. See it’s really easy for you as a manager to observe generally how people are working.
So, eventually, engineeringmanagement is going to start looking at moving people around different teams, getting them exposed to different areas of the product, so they become more domain experts in the entire product. The PM, product manager, was not from a technical background. All hands so to speak on.
Decades-old apps designed to retain a limited amount of data due to storage costs at the time are also unlikely to integrate easily with AI tools, says Brian Klingbeil, chief strategy officer at managed services provider Ensono.
Additionally, Amazon Simple Storage Service (Amazon S3) served as the central data lake, providing a scalable and cost-effective storage solution for the diverse data types collected from different systems. About the Authors Emrah Kaya is Data EngineeringManager at Omron Europe and Platform Lead for ODAP Project.
Additionally, developers must invest considerable time optimizing price performance through fine-tuning and extensive prompt engineering. Managing multiple models, implementing safety guardrails, and adapting outputs to align with downstream system requirements can be difficult and time consuming.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content