This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
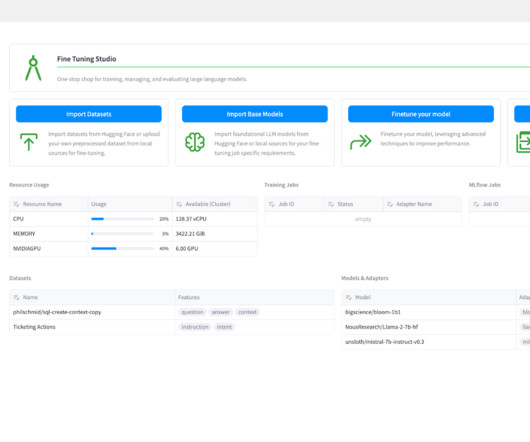
Across diverse industries—including healthcare, finance, and marketing—organizations are now engaged in pre-training and fine-tuning these increasingly larger LLMs, which often boast billions of parameters and larger input sequence length. This approach reduces memory pressure and enables efficient training of large models.
We end up in a cycle of constantly looking back at incomplete or poorly documented trouble tickets to find a solution.” Educate and train help desk analysts. Equip the team with the necessary training to work with AI tools. The number one help desk data issue is, without question, poorly documented resolutions,” says Taylor.
Intelligent document processing (IDP) is changing the dynamic of a longstanding enterprise content management problem: dealing with unstructured content. The ability to effectively wrangle all that data can have a profound, positive impact on numerous document-intensive processes across enterprises. Not so with unstructured content.
But Stephen Durnin, the company’s head of operational excellence and automation, says the 2020 Covid-19 pandemic thrust automation around unstructured input, like email and documents, into the spotlight. “We This was exacerbated by errors or missing information in documents provided by customers, leading to additional work downstream. “We
As explained in a previous post , with the advent of AI-based tools and intelligent document processing (IDP) systems, ECM tools can now go further by automating many processes that were once completely manual. That relieves users from having to fill out such fields themselves to classify documents, which they often don’t do well, if at all.
LLMs deployed as internal enterprise-specific agents can help employees find internal documentation, data, and other company information to help organizations easily extract and summarize important internal content. Given some example data, LLMs can quickly learn new content that wasn’t available during the initial training of the base model.
The extensive pre-trained knowledge of the LLMs enables them to effectively process and interpret even unstructured data. Traditionally, such an application might have used a specially trained ML model to classify uploaded receipts into accounting categories, such as DATEV. This makes their wide range of capabilities usable.
TIAA has launched a generative AI implementation, internally referred to as “Research Buddy,” that pulls together relevant facts and insights from publicly available documents for Nuveen, TIAA’s asset management arm, on an as-needed basis. When the research analysts want the research, that’s when the AI gets activated.
Summer school At the moment, everyone can familiarize themselves with the AI support on their own, but during August this year was the time for mandatory training, where everyone got the basic knowledge they needed to be able to use it correctly, and how to ask questions and prompts to get exactly what’s needed.
Language models like GPT-4 and Claude are powerful and useful, but the data on which they are trained is a closely guarded secret. Image Credits: AI2 Of course it is these companies’ prerogative, in the context of a fiercely competitive AI landscape, to guard the secrets of their models’ training processes.
Training, communication, and change management are the real enablers. The proof lay in another project conducted by Sicca for Eurostampa of the paperless factory, or the transition from processes based entirely on paper supports, to being managed entirely on workflow and with digital documents.
Baker says productivity is one of the main areas of gen AI deployment for the company, which is now available through Office 365, and allows employees to do such tasks as summarize emails, or help with PowerPoint and Excel documents. We have a ton of documents we can talk about. Were taking that part very slowly.
Document verification, for instance, might seem straightforward, but it involves multiple steps, including image capture and data collection, behind the scenes. Its also possible to train agentic AI to recognize itself and determine that responses during a verification are likely coming from a computer.
Gen AI agenda Beswick has an ambitious gen AI agenda but everything being developed and trained today is for internal use only to guard against hallucinations and data leakage. He estimates 40 generative AI production use cases currently, such as drafting and emailing documents, translation, document summarization, and research on clients.
In these cases, the AI sometimes fabricated unrelated phrases, such as “Thank you for watching!” — likely due to its training on a large dataset of YouTube videos. This phenomenon, known as hallucination, has been documented across various AI models.
Seven companies that license music, images, videos, and other data used for training artificial intelligence systems have formed a trade association to promote responsible and ethical licensing of intellectual property. They must also introduce operational processes document and disclose copyright-related information during dataset creation.”
ChatGPT ChatGPT, by OpenAI, is a chatbot application built on top of a generative pre-trained transformer (GPT) model. So given the current climate of access and adoption, here are the 10 most-used gen AI tools in the enterprise right now. The free version leverages OpenAIs GPT-3.5 LLM, but paid users can choose their model.
While a firewall is simply hardware or software that identifies and blocks malicious traffic based on rules, a human firewall is a more versatile, real-time, and intelligent version that learns, identifies, and responds to security threats in a trained manner. The training has to result in behavioral change and be habit-forming.
That correlates strongly with getting the right training, especially in terms of using gen AI appropriately for their own workflow. According to some fairly comprehensive research by Microsoft and LinkedIn, AI power users who say the tools save them 30 minutes a day are 37% more likely to say their company gave them tailored gen AI training.
Gen AI agenda Beswick has an ambitious gen AI agenda but everything being developed and trained today is for internal use only to guard against hallucinations and data leakage. He estimates 40 generative AI production use cases currently, such as drafting and emailing documents, translation, document summarization, and research on clients.
This is where intelligent document processing (IDP), coupled with the power of generative AI , emerges as a game-changing solution. The Education and Training Quality Authority (BQA) plays a critical role in improving the quality of education and training services in the Kingdom Bahrain.
In particular, it is essential to map the artificial intelligence systems that are being used to see if they fall into those that are unacceptable or risky under the AI Act and to do training for staff on the ethical and safe use of AI, a requirement that will go into effect as early as February 2025.
Nate Melby, CIO of Dairyland Power Cooperative, says the Midwestern utility has been churning out large language models (LLMs) that not only automate document summarization but also help manage power grids during storms, for example. The firm has also established an AI academy to train all its employees. “We
What was once a preparatory task for training AI is now a core part of a continuous feedback and improvement cycle. Training compact, domain-specialized models that outperform general-purpose LLMs in areas like healthcare, legal, finance, and beyond. Todays annotation tools are no longer just for labeling datasets.
But that’s exactly the kind of data you want to include when training an AI to give photography tips. Conversely, some of the other inappropriate advice found in Google searches might have been avoided if the origin of content from obviously satirical sites had been retained in the training set.
Throughout 2024, Camelot’s team of in-house developers built the AI wizard that would become “Myrddin,” training it to understand CMMC guidelines and answer questions quickly with a focus on actionable, real-time guidance. Birmingham says the company plans to expand Myrddin’s AI capabilities into its other product areas.
Code copilots, intelligent document processing, and models fine-tuned on domain-specific data sets can create a first draft of whatever the employee needs, saving time and increasing productivity. That means that admins can spend more time addressing and preventing threats and less time trying to interpret security data and alerts.
We recommend referring to the Submit a model distillation job in Amazon Bedrock in the official AWS documentation for the most up-to-date and comprehensive information. Amazon Bedrock provides two primary methods for preparing your training data: uploading JSONL files to Amazon S3 or using historical invocation logs.
Typical repetitive tasks that can be automated includes reviewing and categorizing documents, images, or text. Specifically, the startup targets work processes that involve making decisions on unstructured data, such as images, text, PDFs and other documents.
Medical professionals can spend long hours reading upwards of 1,000 pages of medical records and other documents for a single claim. Because its trained on proprietary industry data, the model provides specific, accurate, and concise responses that enhance insurers efficiency and improve the customer experience.
Image Credits: OpenAI The live web is less curated than a static training data set and — by implication — less filtered, of course. Once limited to the information within its training data, ChatGPT is, with plugins, suddenly far more capable — and perhaps at less legal risk. Meta’s since-disbanded BlenderBot 3.0
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. An interactive chat interface allows deeper exploration of both the original document and generated content.
Utilizing AI, the tool interprets the queries, scans through a broad range of documents spread across different repositories, and delivers relevant answers. Utilizing AI, the tool interprets the queries, scans through a broad range of documents spread across different repositories, and delivers relevant answers.
Today, were excited to announce the general availability of Amazon Bedrock Data Automation , a powerful, fully managed feature within Amazon Bedrock that automate the generation of useful insights from unstructured multimodal content such as documents, images, audio, and video for your AI-powered applications. billion in 2025 to USD 66.68
For instance, a conversational AI software company, Kore.ai , trained its BankAssist solution for voice, web, mobile, SMS, and social media interactions. Intelligent Search People rely on intelligent search every single day, thanks to LLMs trained on internet datasets. Take healthcare, for instance.
While a trained copywriter might produce more polished content, LLMs ensure that no product remains without a description, preventing potential revenue loss due to delayed listings. Rather than sifting through documentation manually, an AI-powered assistant can generate concise and relevant answers, enhancing productivity across teams.
and Australian cyber agencies have published “ Safe Software Deployment: How Software Manufacturers Can Ensure Reliability for Customers. ” “It is critical for all software manufacturers to implement a safe software deployment program supported by verified processes, including robust testing and measurements,” reads the 12-page document.
AI research startup Anthropic aims to raise as much as $5 billion over the next two years to take on rival OpenAI and enter over a dozen major industries, according to company documents obtained by TechCrunch. “We believe that companies that train the best 2025/26 models will be too far ahead for anyone to catch up in subsequent cycles.”
Developers now have access to various AI-powered tools that assist in coding, debugging, and documentation. It uses OpenAI’s Codex, a language model trained on a vast amount of code from public repositories on GitHub. Documentation Assistance : Helps in creating and improving code documentation.
Reasons for using RAG are clear: large language models (LLMs), which are effectively syntax engines, tend to “hallucinate” by inventing answers from pieces of their training data. See the primary sources “ REALM: Retrieval-Augmented Language Model Pre-Training ” by Kelvin Guu, et al., Split each document into chunks.
While employee training is a must to avoid these behaviors, in some cases it goes directly against the desires of the development team to maximize productivity and meet schedule deadlines.Ive talked to development executives who have encouraged the use of public tools and repos for their employees who are stuck.
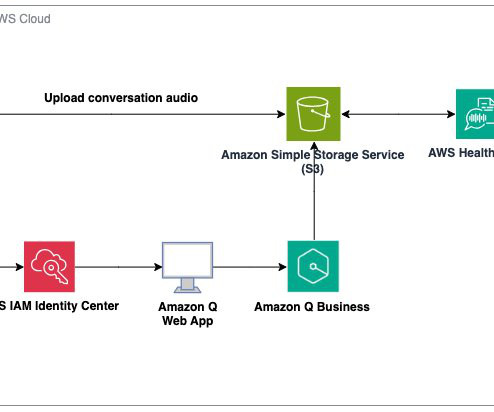
During re:Invent 2023, we launched AWS HealthScribe , a HIPAA eligible service that empowers healthcare software vendors to build their clinical applications to use speech recognition and generative AI to automatically create preliminary clinician documentation.
Document understanding Fine-tuning is particularly effective for extracting structured information from document images. When working with documents, note that Meta Llama 3.2 processes documents as images (such as PNG format), not as native PDFs or other document formats. As of writing this post, Meta Llama 3.2
Skilled labor shortage : The construction workforce is aging faster than the younger population that joins it, resulting in a shortage of labor particularly for skilled trades that may require years of training and certifications.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content