This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, you will learn how to extract key objects from image queries using Amazon Rekognition and build a reverse image search engine using Amazon Titan Multimodal Embeddings from Amazon Bedrock in combination with Amazon OpenSearch Serverless Service. An Amazon OpenSearch Serverless collection. b64encode(resized_image).decode('utf-8')
That’s where the new Amazon EMR Serverless application integration in Amazon SageMaker Studio can help. In this post, we demonstrate how to leverage the new EMR Serverless integration with SageMaker Studio to streamline your data processing and machine learning workflows.
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. An interactive chat interface allows deeper exploration of both the original document and generated content.
Leveraging Serverless and Generative AI for Image Captioning on GCP In today’s age of abundant data, especially visual data, it’s imperative to understand and categorize images efficiently. TL;DR We’ve built an automated, serverless system on Google Cloud Platform where: Users upload images to a Google Cloud Storage Bucket.
Access to car manuals and technical documentation helps the agent provide additional context for curated guidance, enhancing the quality of customer interactions. The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket.
With Amazon Q Business , Hearst’s CCoE team built a solution to scale cloud best practices by providing employees across multiple business units self-service access to a centralized collection of documents and information. User authorization for documents within the individual S3 buckets were controlled through access control lists (ACLs).
With the growth of the application modernization demands, monolithic applications were refactored to cloud-native microservices and serverless functions with lighter, faster, and smaller application portfolios for the past years.
We also use Vector Engine for Amazon OpenSearch Serverless (currently in preview) as the vector data store to store embeddings. For instance, a financial firm might prefer its Q&A bot to source answers from its latest internal documents, ensuring accuracy and compliance with its business rules.
With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using the AWS tools without having to manage any infrastructure. You will be given two documents to compare. Here are the two documents.
Amazon Bedrock offers a serverless experience so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage infrastructure.
Organizations typically can’t predict their call patterns, so the solution relies on AWS serverless services to scale during busy times. Amazon Simple Storage Service (Amazon S3) is an object storage service offering industry-leading scalability, data availability, security, and performance.
This enables sales teams to interact with our internal sales enablement collateral, including sales plays and first-call decks, as well as customer references, customer- and field-facing incentive programs, and content on the AWS website, including blog posts and service documentation.
That’s right, while you were avoiding the back-to-school rush at Office Depot, cutting the crusts off PB&Js, and taking the layers out of mothballs (confession: I have never seen let alone used a single mothball), Serverless Summer School began winding down and is now over for the season. SSS: Serverless Confidence, AWS Proficiency.
With Serverless, it’s not the technology that’s hard, it’s understanding the language of a new culture and operational model. Serverless architecture has coined some new terms and, more confusingly, re-used a few older terms with new meanings. This glossary will clarify some of them. For now, we’re sticking with ‘App’.
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. For more details about pricing, refer to Amazon Bedrock pricing.
Flexible logging –You can use this solution to store logs either locally or in Amazon Simple Storage Service (Amazon S3) using Amazon Data Firehose, enabling integration with existing monitoring infrastructure. Cost optimization – This solution uses serverless technologies, making it cost-effective for the observability infrastructure.
Mozart, the leading platform for creating and updating insurance forms, enables customers to organize, author, and file forms seamlessly, while its companion uses generative AI to compare policy documents and provide summaries of changes in minutes, cutting the change adoption time from days or weeks to minutes.
Its structure of saving the data is different because it stores data in a document which is like JSON. It uses the most popular document store database model. So, It has some great features like document-oriented storage, ease of use, high performance, fast execution of queries and maintenance of database backup is easy.
For example, consider how the following source document chunk from the Amazon 2023 letter to shareholders can be converted to question-answering ground truth. To convert the source document excerpt into ground truth, we provide a base LLM prompt template. Further, Amazons operating income and Free Cash Flow (FCF) dramatically improved.
API Gateway is serverless and hence automatically scales with traffic. The advantage of using Application Load Balancer is that it can seamlessly route the request to virtually any managed, serverless or self-hosted component and can also scale well. It’s serverless so you don’t have to manage the infrastructure.
Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive. This solution uses the powerful capabilities of Amazon Q Business.
If you’ve built a serverless application or two, you’re probably familiar with the benefits of serverless architecture. You take advantage of already built, managed cloud services to handle standard application requirements like authentication, storage, compute, API gateways, and a long list of other infrastructure needs.
We explore how to build a fully serverless, voice-based contextual chatbot tailored for individuals who need it. The aim of this post is to provide a comprehensive understanding of how to build a voice-based, contextual chatbot that uses the latest advancements in AI and serverless computing. We discuss this later in the post.
When setting up a data model, SurrealDB users can choose between simple documents, documents with embedded fields or related graph connections between records, Tobie says — depending on the nature of the data being stored.
No Internal Data Access: Without access to proprietary datasets or internal company documents, responses are generic and lack personalization. Levels of RAG Implementation on GCP Level 1: Basic RAG This level involves document retrieval using vector search and answer generation via a prompt containing the retrieved context.
In this article, we are going to compare the leading cloud providers of serverless computing frameworks so that you have enough intel to make a sound decision when choosing one over the others. Documentation. You can find a comprehensive list in the AWS Lambda documentation here. Capacity and Support . AWS Lambda. 0.000016/GB-s.
Since Amazon Bedrock is serverless, you don’t have to manage any infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with.
Last week, I joined an awesome lineup of speakers and serverless users in Tennessee for the inaugural ServerlessDays Nashville conference. Whether you help architect serverless applications at work or you’re just getting started in the community, chances are you’ve caught wind of a ServerlessDays event. Enter serverless.
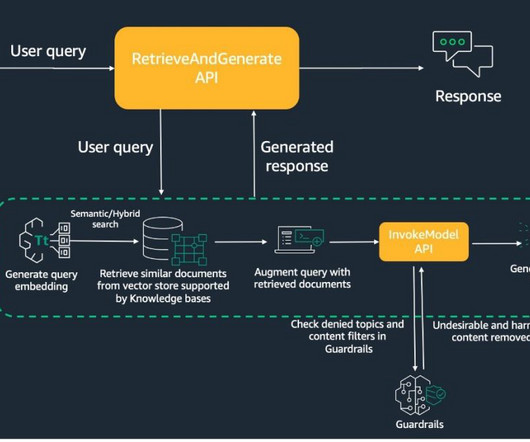
This new functionality offers industry-leading safety measures that filter harmful content and protect sensitive information in your documents, improving user experience and aligning with organizational standards. The query is then augmented to have the retrieved document chunks, prompt, and guardrails configuration.
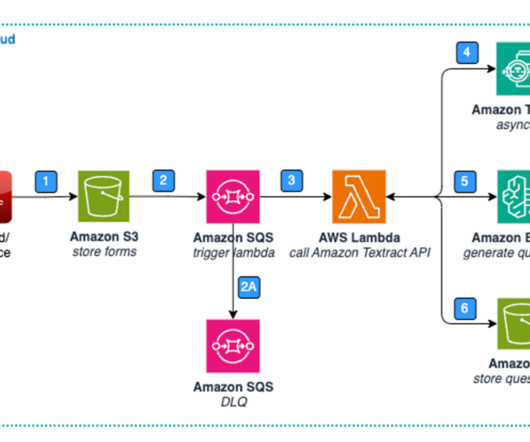
The healthcare industry generates and collects a significant amount of unstructured textual data, including clinical documentation such as patient information, medical history, and test results, as well as non-clinical documentation like administrative records. Figure 1: Architecture – Standard Form – Data Extraction & Storage.
According to the RightScale 2018 State of the Cloud report, serverless architecture penetration rate increased to 75 percent. Aware of what serverless means, you probably know that the market of cloudless architecture providers is no longer limited to major vendors such as AWS Lambda or Azure Functions. Where does serverless come from?
Security is Less of a Problem with Serverless but Still Critical. But the fact is, the two resources I just shared serve as amazing documentation; Ory found examples of these vulnerabilities in active GitHub repos! It might seem like a serverless function just isn’t vulnerable to code injection. Get the full guide here.
Here are some features which we will cover: AWS CloudFormation support Private network policies for Amazon OpenSearch Serverless Multiple S3 buckets as data sources Service Quotas support Hybrid search, metadata filters, custom prompts for the RetreiveAndGenerate API, and maximum number of retrievals.
Prerequisites To implement the solution provided in this post, you should have the following: An active AWS account and familiarity with FMs, Amazon Bedrock, and OpenSearch Serverless. An S3 bucket where your documents are stored in a supported format (.txt,md,html,doc/docx,csv,xls/.xlsx,pdf). txt,md,html,doc/docx,csv,xls/.xlsx,pdf).
If you’re implementing complex RAG applications into your daily tasks, you may encounter common challenges with your RAG systems such as inaccurate retrieval, increasing size and complexity of documents, and overflow of context, which can significantly impact the quality and reliability of generated answers.
Stackery is a tool to deploy complete serverless applications via Amazon Web Services (AWS). Epsagon monitors and tracks your serverless components to increase observability. Observability is a Problem for Serverless. Here’s how they can not only work together but improve each other. What do you do? Try it Yourself.
This domain knowledge is traditionally captured in reference manuals, service bulletins, quality ticketing systems, engineering drawings, and more, but the quantity and complexity of documents is growing and takes time to learn. How can I trace the reasoning of my model back to source documents to build user trust?” “How
Nowadays, the cliche “serverless architecture” is the latest addition in the technology wordbook, prevailing following the launch of AWS (Amazon Web Services) Lambada in 2014. While the gospel truth is serverless, architecture proffers the promise of writing codes without any ongoing server administration apprehension.
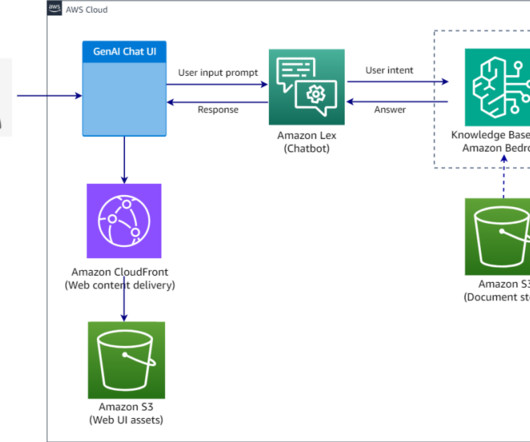
In this post, we demonstrate how you can build chatbots with QnAIntent that connects to a knowledge base in Amazon Bedrock (powered by Amazon OpenSearch Serverless as a vector database ) and build rich, self-service, conversational experiences for your customers. Select the embedding model to vectorize the documents. Choose Next.
In this post, we illustrate contextually enhancing a chatbot by using Knowledge Bases for Amazon Bedrock , a fully managed serverless service. Embeddings are created for documents and user questions. The document embeddings are split into chunks and stored as indexes in a vector database. Choose Next.
Organizations that have used Google Cloud Platform’s Cloud Functions – a serverless execution environment – could be impacted by a privilege escalation vulnerability discovered by Tenable and dubbed as “ConfusedFunction.” Cloud Functions in GCP are event-triggered, serverless functions. What are Cloud Functions?
Our solution uses an FSx for ONTAP file system as the source of unstructured data and continuously populates an Amazon OpenSearch Serverless vector database with the user’s existing files and folders and associated metadata. The RAG Retrieval Lambda function stores conversation history for the user interaction in an Amazon DynamoDB table.
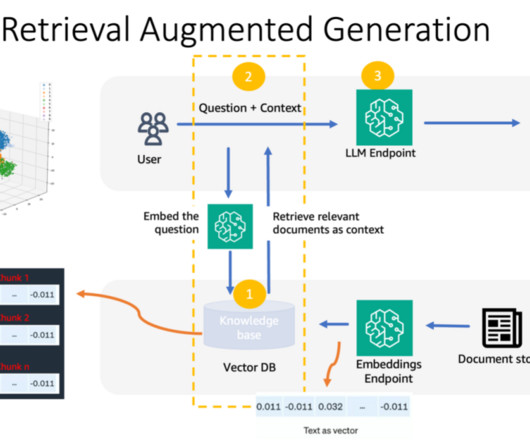
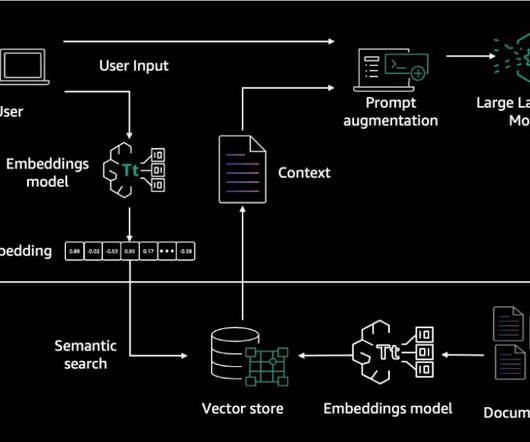
Knowledge Bases for Amazon Bedrock automates synchronization of your data with your vector store, including diffing the data when it’s updated, document loading, and chunking, as well as semantic embedding. It then employs a language model to generate a response by considering both the retrieved documents and the original query.
Google Cloud Functions is a serverless, event-driven, managed platform for building and connecting cloud services. Serverless Concepts – Serverless has been gaining momentum as cloud technology continues to become more and more widespread. Free Mastery Courses. Vim- The Improved Editor. YAML Essentials.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content