This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
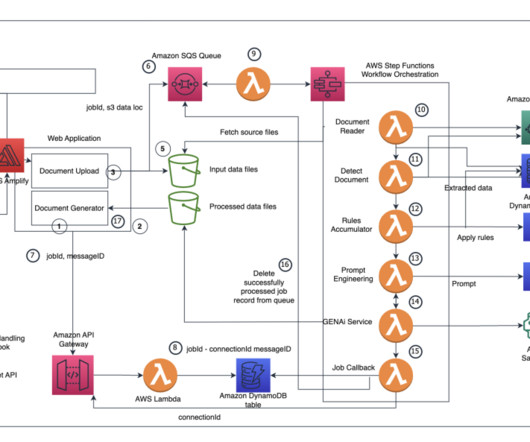
To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. Conclusion In this post, we’ve introduced a scalable and efficient solution for automating batch inference jobs in Amazon Bedrock. This automatically deletes the deployed stack.
Intelligent tiering Tiering has long been a strategy CIOs have employed to gain some control over storage costs. Hybrid cloud solutions allow less frequently accessed data to be stored cost-effectively while critical data remains on high-performance storage for immediate access. Now, things run much smoother.
not domain-specific text like legal documents, financial statements, or medical records), and in one of the seven languages supported by spaCy , this is a great way to go. Training scalability. Scalability difference is significant. Scalability. Image courtesy of Saif Addin Ellafi. Image courtesy of Saif Addin Ellafi.
MongoDB is a document-oriented server that was developed in the C++ programming language. MongoDB and is the open-source server product, which is used for document-oriented storage. All three of them experienced relational database scalability issues when developing web applications at their company. MongoDB History.
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. An interactive chat interface allows deeper exploration of both the original document and generated content.
Azure Storage is a cloud-based storage service from Microsoft Azure. It provides a scalable, secure and highly available data storage solution for businesses of any size. Azure Files […] The post Quick Guide to Azure Storage Pricing appeared first on DevOps.com.
Today, were excited to announce the general availability of Amazon Bedrock Data Automation , a powerful, fully managed feature within Amazon Bedrock that automate the generation of useful insights from unstructured multimodal content such as documents, images, audio, and video for your AI-powered applications. billion in 2025 to USD 66.68
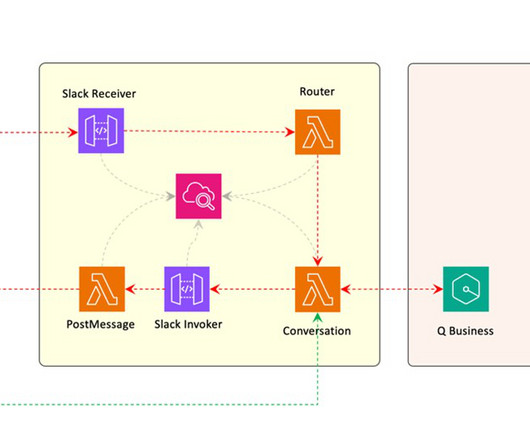
With Amazon Q Business , Hearst’s CCoE team built a solution to scale cloud best practices by providing employees across multiple business units self-service access to a centralized collection of documents and information. User authorization for documents within the individual S3 buckets were controlled through access control lists (ACLs).
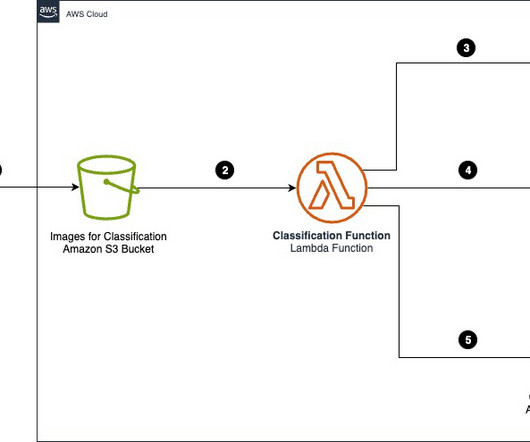
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizing documents is an important first step in IDP systems.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
Access to car manuals and technical documentation helps the agent provide additional context for curated guidance, enhancing the quality of customer interactions. The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. As Principal grew, its internal support knowledge base considerably expanded.
A key part of the submission process is authoring regulatory documents like the Common Technical Document (CTD), a comprehensive standard formatted document for submitting applications, amendments, supplements, and reports to the FDA. The tedious process of compiling hundreds of documents is also prone to errors.
From insurance to banking to healthcare, organizations of all stripes are upgrading their aging content management systems with modern, advanced systems that introduce new capabilities, flexibility, and cloud-based scalability. million documents, representing the past 15 years of business documents, to OnBase.
Amazon DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability. Amazon Simple Storage Service (Amazon S3) is an object storage service offering industry-leading scalability, data availability, security, and performance.
Mozart, the leading platform for creating and updating insurance forms, enables customers to organize, author, and file forms seamlessly, while its companion uses generative AI to compare policy documents and provide summaries of changes in minutes, cutting the change adoption time from days or weeks to minutes.
Every company needs documents for its processes, information, contracts, proposals, quotes, reports, non-disclosure agreements, service agreements, and for various other purposes. Document creation and management is a crucial part of their operations. What is Industries Document Generation? How to generate documents?
This is where intelligent document processing (IDP), coupled with the power of generative AI , emerges as a game-changing solution. The process involves the collection and analysis of extensive documentation, including self-evaluation reports (SERs), supporting evidence, and various media formats from the institutions being reviewed.
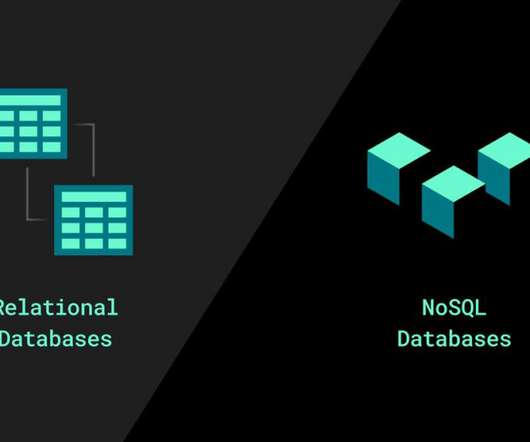
The fundraising perhaps reflects the growing demand for platforms that enable flexible data storage and processing. That’s opposed to a nonrelational database, which has a storage model optimized for the type of data that it’s storing. customer preferences).
Solution overview This solution uses the Amazon Bedrock Knowledge Bases chat with document feature to analyze and extract key details from your invoices, without needing a knowledge base. Importantly, your document and data are not stored after processing. Install Python 3.7 or later on your local machine.
As successful proof-of-concepts transition into production, organizations are increasingly in need of enterprise scalable solutions. For latest information, please refer to the documentation above. VectorIngestionConfiguration – Contains details about how to ingest the documents in a data source.
Scalability and performance – The EMR Serverless integration automatically scales the compute resources up or down based on your workload’s demands, making sure you always have the necessary processing power to handle your big data tasks. By unlocking the potential of your data, this powerful integration drives tangible business results.
The map functionality in Step Functions uses arrays to execute multiple tasks concurrently, significantly improving performance and scalability for workflows that involve repetitive operations. Furthermore, our solutions are designed to be scalable, ensuring that they can grow alongside your business.
However, these tools may not be suitable for more complex data or situations requiring scalability and robust business logic. In short, Booster is a Low-Code TypeScript framework that allows you to quickly and easily create a backend application in the cloud that is highly efficient, scalable, and reliable. WTF is Booster?
This enables sales teams to interact with our internal sales enablement collateral, including sales plays and first-call decks, as well as customer references, customer- and field-facing incentive programs, and content on the AWS website, including blog posts and service documentation.
Its structure of saving the data is different because it stores data in a document which is like JSON. It uses the most popular document store database model. High scalability, sharding and availability with built-in replication makes it more robust. Basic database model used in this is document store. application.
Scalability: GCP tools offer a cohesive platform to build, manage, and scale RAG systems. No Internal Data Access: Without access to proprietary datasets or internal company documents, responses are generic and lack personalization. Vector Similarity Search : Enables efficient retrieval of relevant documents by comparing embeddings.
Non-relational databases are the other type of databases that uses documents other than tables. These databases are designed to store the unstructured data in a particular document. In this document, the organizations can store their customers’ information such as name, order, favorite, address, contact details, and many more.
Could It Be the Best Customer Experience in the Storage Industry? At Infinidat, we set out to deliver the best customer experience in the storage industry. The Solution provides easy to provision, manage and scale storage for both file and block. Adriana Andronescu. Thu, 08/26/2021 - 11:24. Reliability.
Flexible logging –You can use this solution to store logs either locally or in Amazon Simple Storage Service (Amazon S3) using Amazon Data Firehose, enabling integration with existing monitoring infrastructure. Access the source code and documentation in our GitHub repository and start your integration journey.
To accelerate iteration and innovation in this field, sufficient computing resources and a scalable platform are essential. High-quality video datasets tend to be massive, requiring substantial storage capacity and efficient data management systems. This integration brings several benefits to your ML workflow.
This book will help you in identifying the most important concerns and apply unique tricks to achieve higher scalability and modularity in your Node.js This book is going to help you in creating apps using the best practices of the node js with improved performances and you’ll create readily-scalable production system.
They must be accompanied by documentation to support compliance-based and operational auditing requirements. It must be clear to all participants and auditors how and when data-related decisions and controls were introduced into the processes. Data-related decisions, processes, and controls subject to data governance must be auditable.
This paper proposes a safe, effective, and interactive search scheme that allows for precise multi-keyword searching and dynamic document elimination. The device keeps knowledge anonymous and accessible by using cooperating nodes while being highly scalable, alongside an effective adaptive routing algorithm. Cloud Storage.
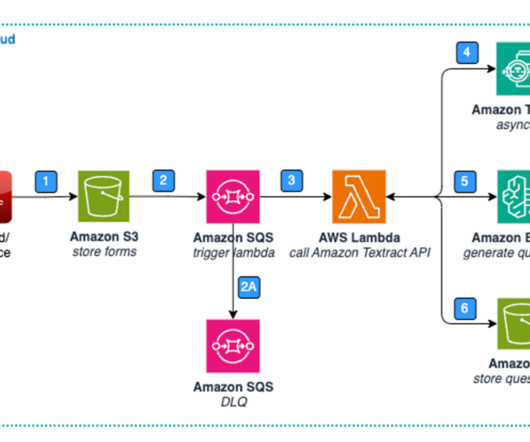
The healthcare industry generates and collects a significant amount of unstructured textual data, including clinical documentation such as patient information, medical history, and test results, as well as non-clinical documentation like administrative records. Figure 1: Architecture – Standard Form – Data Extraction & Storage.
For example, consider how the following source document chunk from the Amazon 2023 letter to shareholders can be converted to question-answering ground truth. To convert the source document excerpt into ground truth, we provide a base LLM prompt template. Further, Amazons operating income and Free Cash Flow (FCF) dramatically improved.
Reusability, composability, accessibility, and scalability are some of the core elements that a good API strategy can provide to support tech trends like hybrid cloud, hyper-automation, or AI.” For these reasons, API-first has gathered steam, a practice that privileges the development of the developer-facing interface above other concerns.
The underlying objective was to tap into GCP’s scalable and efficient infrastructure, without the overhead of server management, while benefiting from VertexAI’s image captioning abilities. TL;DR We’ve built an automated, serverless system on Google Cloud Platform where: Users upload images to a Google Cloud Storage Bucket.
Integrating GitHub repositories with Azure Storage proves to be a robust solution for the management of project files in the cloud. You must be wondering why, although the files already exist in the repository, we are sending them from a GitHub repository to an Azure Storage container.
This scalability allows you to expand your business without needing a proportionally larger IT team.” By reducing boilerplating, teams can save time on repetitive tasks while automated and enhanced documentation keeps pace with code changes and project developments.”
This modular approach improved maintainability and scalability of applications, as each service could be developed, deployed, and scaled independently. Graphs visually represent the relationships and dependencies between different components of an application, like compute, data storage, messaging and networking.
Fidelity National Information Services And among low-code tools, for instance, FIS chose WaveMaker because its components seemed more scalable than its competitors, and its per-developer licensing model was less expensive than the per runtime model of other tools. Vikram Ramani, Fidelity National Information Services CTO.
Data Modelers: They design and create conceptual, logical, and physical data models that organize and structure data for best performance, scalability, and ease of access. They oversee implementation to ensure performance and scalability and may use the generated reports. In the 1990s, data modeling was a specialized role.
These databases are more agile and provide scalable features; also, they are a better choice to handle the vast data of the customers and find crucial insights. This is in our list of best NoSQL databases because it has the functionality of scalability, consistent reading of data, and many more.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content