This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. An interactive chat interface allows deeper exploration of both the original document and generated content.
That’s where the new Amazon EMR Serverless application integration in Amazon SageMaker Studio can help. In this post, we demonstrate how to leverage the new EMR Serverless integration with SageMaker Studio to streamline your data processing and machine learning workflows.
Leveraging Serverless and Generative AI for Image Captioning on GCP In today’s age of abundant data, especially visual data, it’s imperative to understand and categorize images efficiently. TL;DR We’ve built an automated, serverless system on Google Cloud Platform where: Users upload images to a Google Cloud Storage Bucket.
With Amazon Q Business , Hearst’s CCoE team built a solution to scale cloud best practices by providing employees across multiple business units self-service access to a centralized collection of documents and information. User authorization for documents within the individual S3 buckets were controlled through access control lists (ACLs).
As successful proof-of-concepts transition into production, organizations are increasingly in need of enterprise scalable solutions. For latest information, please refer to the documentation above. VectorIngestionConfiguration – Contains details about how to ingest the documents in a data source.
Amazon Bedrock Custom Model Import enables the import and use of your customized models alongside existing FMs through a single serverless, unified API. This serverless approach eliminates the need for infrastructure management while providing enterprise-grade security and scalability.
Truly serverless. Serverless doesn't mean it's a burstable VM that saves its instance state to disk during periods of idle. I'm dreaming of a world where things are truly serverless. Eventually, it evolves into its own super-custom DSL with its own documentation. Can't wait. I don't want to pay for idle resources.
With the growth of the application modernization demands, monolithic applications were refactored to cloud-native microservices and serverless functions with lighter, faster, and smaller application portfolios for the past years.
Access to car manuals and technical documentation helps the agent provide additional context for curated guidance, enhancing the quality of customer interactions. The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket.
For instance, consider an AI-driven legal document analysis system designed for businesses of varying sizes, offering two primary subscription tiers: Basic and Pro. Meanwhile, the business analysis interface would focus on text summarization for analyzing various business documents. This is illustrated in the following figure.
Organizations typically can’t predict their call patterns, so the solution relies on AWS serverless services to scale during busy times. Amazon DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability.
Its structure of saving the data is different because it stores data in a document which is like JSON. It uses the most popular document store database model. High scalability, sharding and availability with built-in replication makes it more robust. Basic database model used in this is document store. application.
Many companies across various industries prioritize modernization in the cloud for several reasons, such as greater agility, scalability, reliability, and cost efficiency, enabling them to innovate faster and stay competitive in today’s rapidly evolving digital landscape.
Since Amazon Bedrock is serverless, you don’t have to manage any infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with. Furthermore, our solutions are designed to be scalable, ensuring that they can grow alongside your business.
That’s right, while you were avoiding the back-to-school rush at Office Depot, cutting the crusts off PB&Js, and taking the layers out of mothballs (confession: I have never seen let alone used a single mothball), Serverless Summer School began winding down and is now over for the season. SSS: Serverless Confidence, AWS Proficiency.
Whether processing invoices, updating customer records, or managing human resource (HR) documents, these workflows often require employees to manually transfer information between different systems a process thats time-consuming, error-prone, and difficult to scale. The following diagram illustrates the solution architecture.
Mozart, the leading platform for creating and updating insurance forms, enables customers to organize, author, and file forms seamlessly, while its companion uses generative AI to compare policy documents and provide summaries of changes in minutes, cutting the change adoption time from days or weeks to minutes.
However, these tools may not be suitable for more complex data or situations requiring scalability and robust business logic. On the other hand, using serverless solutions from scratch can be time-consuming and require a lot of effort to set up and manage. To know more about events, refer to the official documentation.
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. There might also be costs associated with using Google services.
When serverless pops up in conversation, there is sometimes an uncomfortable silence in the room. This is possibly because the majority of us don’t know much about serverless. Serverless is the new paradigm for building applications. Hopefully, you’ll know more after you read this post!
In this article, we are going to compare the leading cloud providers of serverless computing frameworks so that you have enough intel to make a sound decision when choosing one over the others. Scalability, Limits, and Restrictions. Documentation. You can find a comprehensive list in the AWS Lambda documentation here.
API Gateway is serverless and hence automatically scales with traffic. The advantage of using Application Load Balancer is that it can seamlessly route the request to virtually any managed, serverless or self-hosted component and can also scale well. It’s serverless so you don’t have to manage the infrastructure.
This enables sales teams to interact with our internal sales enablement collateral, including sales plays and first-call decks, as well as customer references, customer- and field-facing incentive programs, and content on the AWS website, including blog posts and service documentation.
Cost optimization – This solution uses serverless technologies, making it cost-effective for the observability infrastructure. For a detailed breakdown of the features and implementation specifics, refer to the comprehensive documentation in the GitHub repository. However, some components may incur additional usage-based costs.
Scalability: GCP tools offer a cohesive platform to build, manage, and scale RAG systems. No Internal Data Access: Without access to proprietary datasets or internal company documents, responses are generic and lack personalization. Starting with a basic level, vector search is often a key component powering a RAG setup.
Intelligent document processing , translation and summarization, flexible and insightful responses for customer support agents, personalized marketing content, and image and code generation are a few use cases using generative AI that organizations are rolling out in production.
When I browse Stackery’s documentation and blog, I see some great writing that I know not everyone has read. Learn what Serverless is… and isn’t. This post was inspired by reading an article on serverless as a general topic that managed to get almost every detail wrong. Local Development with Stackery. Get Over the VPC Roadbump.
For example, consider how the following source document chunk from the Amazon 2023 letter to shareholders can be converted to question-answering ground truth. To convert the source document excerpt into ground truth, we provide a base LLM prompt template. Further, Amazons operating income and Free Cash Flow (FCF) dramatically improved.
Switch to Serverless Computing. Serverless computing is a more recent development that offers an array of potential benefits ranging from cost savings and easier scalability, to faster deployment of new applications. With serverless computing, you ‘pay as you use’ for backend services. Move from VMs to Containerization.
AWS is the first major cloud provider to deliver Pixtral Large as a fully managed, serverless model. This capability makes it particularly effective in analyzing documents, detailed charts, graphs, and natural images, accommodating a broad range of practical applications.
We explore how to build a fully serverless, voice-based contextual chatbot tailored for individuals who need it. The aim of this post is to provide a comprehensive understanding of how to build a voice-based, contextual chatbot that uses the latest advancements in AI and serverless computing. We discuss this later in the post.
According to the RightScale 2018 State of the Cloud report, serverless architecture penetration rate increased to 75 percent. Aware of what serverless means, you probably know that the market of cloudless architecture providers is no longer limited to major vendors such as AWS Lambda or Azure Functions. Where does serverless come from?
Nowadays, the cliche “serverless architecture” is the latest addition in the technology wordbook, prevailing following the launch of AWS (Amazon Web Services) Lambada in 2014. While the gospel truth is serverless, architecture proffers the promise of writing codes without any ongoing server administration apprehension.
" That was indeed my feedback to the team: include in the documentation the reason why the service was created and when to use it instead of the existing options. The first question that came to my mind upon learning about this service was: "Why is Microsoft launching another service to run containers?" Kubernetes Cluster).
Prerequisites To implement the solution provided in this post, you should have the following: An active AWS account and familiarity with FMs, Amazon Bedrock, and OpenSearch Serverless. An S3 bucket where your documents are stored in a supported format (.txt,md,html,doc/docx,csv,xls/.xlsx,pdf). txt,md,html,doc/docx,csv,xls/.xlsx,pdf).
This domain knowledge is traditionally captured in reference manuals, service bulletins, quality ticketing systems, engineering drawings, and more, but the quantity and complexity of documents is growing and takes time to learn. How can I trace the reasoning of my model back to source documents to build user trust?” “How
Organizations strive to implement efficient, scalable, cost-effective, and automated customer support solutions without compromising the customer experience. Select the S3 bucket where you uploaded the Amazon shareholder documents and choose Choose. Select the embedding model to vectorize the documents. Create an Amazon Lex bot.
Our solution uses an FSx for ONTAP file system as the source of unstructured data and continuously populates an Amazon OpenSearch Serverless vector database with the user’s existing files and folders and associated metadata. The RAG Retrieval Lambda function stores conversation history for the user interaction in an Amazon DynamoDB table.
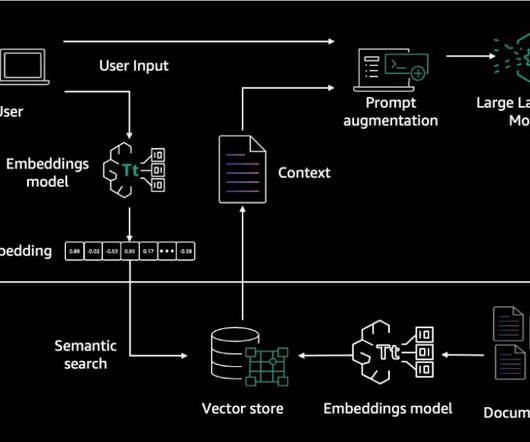
Knowledge Bases for Amazon Bedrock automates synchronization of your data with your vector store, including diffing the data when it’s updated, document loading, and chunking, as well as semantic embedding. It then employs a language model to generate a response by considering both the retrieved documents and the original query.
The Product Stewardship department is responsible for managing a large collection of regulatory compliance documents. Example questions might be “What are the restrictions for CMR substances?”, “How long do I need to keep the documents related to a toluene sale?”, or “What is the reach characterization ratio and how do I calculate it?”
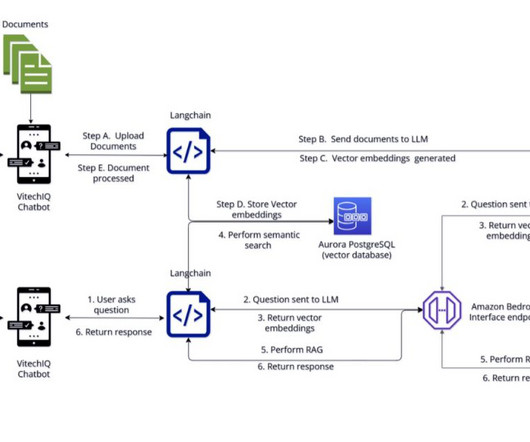
To serve their customers, Vitech maintains a repository of information that includes product documentation (user guides, standard operating procedures, runbooks), which is currently scattered across multiple internal platforms (for example, Confluence sites and SharePoint folders).
In this post, we illustrate contextually enhancing a chatbot by using Knowledge Bases for Amazon Bedrock , a fully managed serverless service. Embeddings are created for documents and user questions. The document embeddings are split into chunks and stored as indexes in a vector database. Choose Next.
Their focus was on creating a robust tech stack that would ensure scalability, maintainability, and performance. Document Hub : Automatically generates API documentation and can be utilized for various other documentation needs. However, the complexity of this setup raised concerns about costs and management.
Many companies across all industries still rely on laborious, error-prone, manual procedures to handle documents, especially those that are sent to them by email. Intelligent automation presents a chance to revolutionize document workflows across sectors through digitization and process optimization.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content