This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
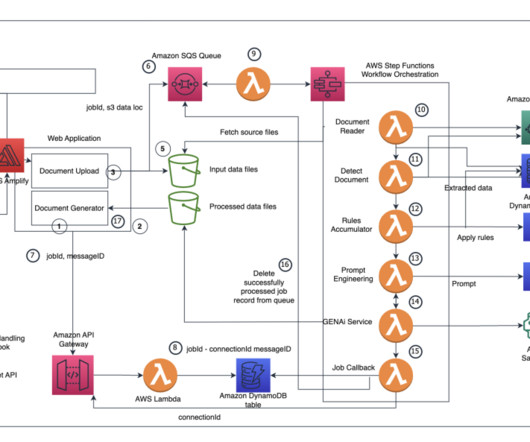
To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. Conclusion In this post, we’ve introduced a scalable and efficient solution for automating batch inference jobs in Amazon Bedrock. This automatically deletes the deployed stack.
Traditional keyword-based search mechanisms are often insufficient for locating relevant documents efficiently, requiring extensive manual review to extract meaningful insights. This solution improves the findability and accessibility of archival records by automating metadata enrichment, document classification, and summarization.
AI practitioners and industry leaders discussed these trends, shared best practices, and provided real-world use cases during EXLs recent virtual event, AI in Action: Driving the Shift to Scalable AI. And its modular architecture distributes tasks across multiple agents in parallel, increasing the speed and scalability of migrations.
The team opted to build out its platform on Databricks for analytics, machinelearning (ML), and AI, running it on both AWS and Azure. I want to provide an easy and secure outlet that’s genuinely production-ready and scalable. MMTech built out data schema extractors for different types of documents such as PDFs.
Intelligent document processing (IDP) is changing the dynamic of a longstanding enterprise content management problem: dealing with unstructured content. The ability to effectively wrangle all that data can have a profound, positive impact on numerous document-intensive processes across enterprises. Not so with unstructured content.
The banking landscape is constantly changing, and the application of machinelearning in banking is arguably still in its early stages. Machinelearning solutions are already rooted in the finance and banking industry. Machinelearning solutions are already rooted in the finance and banking industry.
not domain-specific text like legal documents, financial statements, or medical records), and in one of the seven languages supported by spaCy , this is a great way to go. Training scalability. Scalability difference is significant. Scalability. Image courtesy of Saif Addin Ellafi. Image courtesy of Saif Addin Ellafi.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. As Principal grew, its internal support knowledge base considerably expanded.
It often requires managing multiple machinelearning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats. With Amazon Bedrock Data Automation, enterprises can accelerate AI adoption and develop solutions that are secure, scalable, and responsible.
The team opted to build out its platform on Databricks for analytics, machinelearning (ML), and AI, running it on both AWS and Azure. I want to provide an easy and secure outlet that’s genuinely production-ready and scalable. MMTech built out data schema extractors for different types of documents such as PDFs.
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. An interactive chat interface allows deeper exploration of both the original document and generated content.
Finally, we delve into the supported frameworks, with a focus on LMI, PyTorch, Hugging Face TGI, and NVIDIA Triton, and conclude by discussing how this feature fits into our broader efforts to enhance machinelearning (ML) workloads on AWS. This feature is only supported when using inference components. gpu-py311-cu124-ubuntu22.04-sagemaker",
This engine uses artificial intelligence (AI) and machinelearning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. Amazon DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability.
On the Configure data source page, provide the following information: Specify the Amazon S3 location of the documents. Prior to AWS, Flora earned her Masters degree in Computer Science from the University of Minnesota, where she developed her expertise in machinelearning and artificial intelligence. Specify a chunking strategy.
For instance, consider an AI-driven legal document analysis system designed for businesses of varying sizes, offering two primary subscription tiers: Basic and Pro. Meanwhile, the business analysis interface would focus on text summarization for analyzing various business documents. This is illustrated in the following figure.
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizing documents is an important first step in IDP systems.
For a detailed breakdown of the features and implementation specifics, refer to the comprehensive documentation in the GitHub repository. Although the implementation is straightforward, following best practices is crucial for the scalability, security, and maintainability of your observability infrastructure.
With Amazon Q Business , Hearst’s CCoE team built a solution to scale cloud best practices by providing employees across multiple business units self-service access to a centralized collection of documents and information. Readers will learn the key design decisions, benefits achieved, and lessons learned from Hearst’s innovative CCoE team.
In a world fueled by disruptive technologies, no wonder businesses heavily rely on machinelearning. Google, in turn, uses the Google Neural Machine Translation (GNMT) system, powered by ML, reducing error rates by up to 60 percent. The role of a machinelearning engineer in the data science team.
SageMaker JumpStart is a machinelearning (ML) hub that provides a wide range of publicly available and proprietary FMs from providers such as AI21 Labs, Cohere, Hugging Face, Meta, and Stability AI, which you can deploy to SageMaker endpoints in your own AWS account. It’s serverless so you don’t have to manage the infrastructure.
This is where intelligent document processing (IDP), coupled with the power of generative AI , emerges as a game-changing solution. The process involves the collection and analysis of extensive documentation, including self-evaluation reports (SERs), supporting evidence, and various media formats from the institutions being reviewed.
Whether processing invoices, updating customer records, or managing human resource (HR) documents, these workflows often require employees to manually transfer information between different systems a process thats time-consuming, error-prone, and difficult to scale. In his free time, Krishna loves to go on hikes.
It is a very versatile, platform independent and scalable language because of which it can be used across various platforms. It is frequently used in developing web applications, data science, machinelearning, quality assurance, cyber security and devops. Clean and widely available documentation.
Over the last 18 months, AWS has announced more than twice as many machinelearning (ML) and generative artificial intelligence (AI) features into general availability than the other major cloud providers combined. as part of a larger research document and should be evaluated in the context of the entire document.
This capability makes it particularly effective in analyzing documents, detailed charts, graphs, and natural images, accommodating a broad range of practical applications. Andre Boaventura is a Principal AI/ML Solutions Architect at AWS, specializing in generative AI and scalablemachinelearning solutions.
This allows SageMaker Studio users to perform petabyte-scale interactive data preparation, exploration, and machinelearning (ML) directly within their familiar Studio notebooks, without the need to manage the underlying compute infrastructure.
Mozart, the leading platform for creating and updating insurance forms, enables customers to organize, author, and file forms seamlessly, while its companion uses generative AI to compare policy documents and provide summaries of changes in minutes, cutting the change adoption time from days or weeks to minutes.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. Amazon S3 is an object storage service that offers industry-leading scalability, data availability, security, and performance. Choose Next.
Koletzki would use the move to upgrade the IT environment from a small data room to something more scalable. He knew that scalability was a big win for a company in aggressive growth mode, but he just needed to be persuaded that the platforms were more robust, and the financials made sense. Thats not the case in AI.
As successful proof-of-concepts transition into production, organizations are increasingly in need of enterprise scalable solutions. For latest information, please refer to the documentation above. VectorIngestionConfiguration – Contains details about how to ingest the documents in a data source.
It enables you to index, search, and analyze extensive amounts of content utilizing full-text searches, faceted navigation, and machine-learning features (such as language comprehension and semantic search). Why it’s great Super fast and scalable search experiences. Built-in AI for enhanced relevance. Result; if (!response.IsSuccessStatusCode)
A key part of the submission process is authoring regulatory documents like the Common Technical Document (CTD), a comprehensive standard formatted document for submitting applications, amendments, supplements, and reports to the FDA. The tedious process of compiling hundreds of documents is also prone to errors.
Solution overview This solution uses the Amazon Bedrock Knowledge Bases chat with document feature to analyze and extract key details from your invoices, without needing a knowledge base. Importantly, your document and data are not stored after processing. or later on your local machine. Install Python 3.7
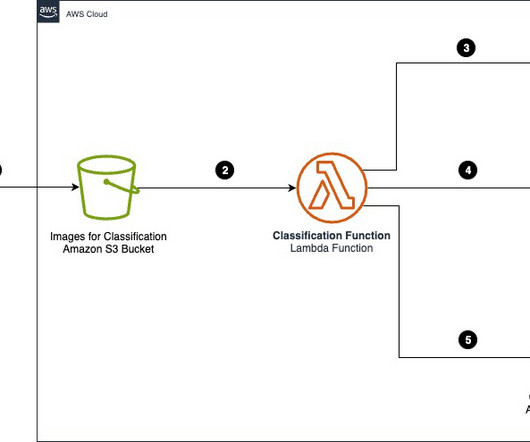
Access to car manuals and technical documentation helps the agent provide additional context for curated guidance, enhancing the quality of customer interactions. The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket.
This scalability allows you to expand your business without needing a proportionally larger IT team.” Many AI systems use machinelearning, constantly learning and adapting to become even more effective over time,” he says. Easy access to constant improvement is another AI growth benefit.
The architectures modular design allows for scalability and flexibility, making it particularly effective for training LLMs that require distributed computing capabilities. We recommend starting your LLM customization journey by exploring our sample recipes in the Amazon SageMaker HyperPod documentation.
Intelligent document processing , translation and summarization, flexible and insightful responses for customer support agents, personalized marketing content, and image and code generation are a few use cases using generative AI that organizations are rolling out in production.
This AI-driven approach is particularly valuable in cloud development, where developers need to orchestrate multiple services while maintaining security, scalability, and cost-efficiency. Skip hours of documentation research and immediately access ready-to-use patterns for complex services such as Amazon Bedrock Knowledge Bases.
In this post, we explore how to deploy distilled versions of DeepSeek-R1 with Amazon Bedrock Custom Model Import, making them accessible to organizations looking to use state-of-the-art AI capabilities within the secure and scalable AWS infrastructure at an effective cost.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
Machinelearning engineer Machinelearning engineers are tasked with transforming business needs into clearly scoped machinelearning projects, along with guiding the design and implementation of machinelearning solutions.
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. There might also be costs associated with using Google services.
Amazon SageMaker AI provides a managed way to deploy TGI-optimized models, offering deep integration with Hugging Faces inference stack for scalable and cost-efficient LLM deployment. Simon Pagezy is a Cloud Partnership Manager at Hugging Face, dedicated to making cutting-edge machinelearning accessible through open source and open science.
For example, consider how the following source document chunk from the Amazon 2023 letter to shareholders can be converted to question-answering ground truth. To convert the source document excerpt into ground truth, we provide a base LLM prompt template. Further, Amazons operating income and Free Cash Flow (FCF) dramatically improved.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






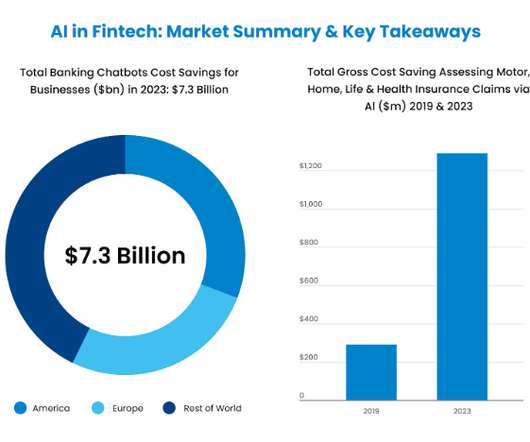















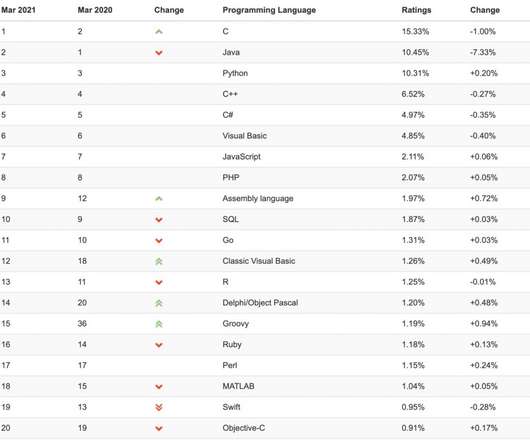




























Let's personalize your content