This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data scientists and AI engineers have so many variables to consider across the machinelearning (ML) lifecycle to prevent models from degrading over time. Explainability is also still a serious issue in AI, and companies are overwhelmed by the volume and variety of data they must manage.
We end up in a cycle of constantly looking back at incomplete or poorly documented trouble tickets to find a solution.” The number one help desk data issue is, without question, poorly documented resolutions,” says Taylor. High quality documentation results in high quality data, which both human and artificial intelligence can exploit.”
Were thrilled to announce the release of a new Cloudera Accelerator for MachineLearning (ML) Projects (AMP): Summarization with Gemini from Vertex AI . We built this AMP for two reasons: To add an AI application prototype to our AMP catalog that can handle both full document summarization and raw text block summarization.
As explained in a previous post , with the advent of AI-based tools and intelligent document processing (IDP) systems, ECM tools can now go further by automating many processes that were once completely manual. That relieves users from having to fill out such fields themselves to classify documents, which they often don’t do well, if at all.
The game-changing potential of artificial intelligence (AI) and machinelearning is well-documented. Any organization that is considering adopting AI at their organization must first be willing to trust in AI technology.
Before LLMs and diffusion models, organizations had to invest a significant amount of time, effort, and resources into developing custom machine-learning models to solve difficult problems. In many cases, this eliminates the need for specialized teams, extensive data labeling, and complex machine-learning pipelines.
Ive spent more than 25 years working with machinelearning and automation technology, and agentic AI is clearly a difficult problem to solve. Document verification, for instance, might seem straightforward, but it involves multiple steps, including image capture and data collection, behind the scenes.
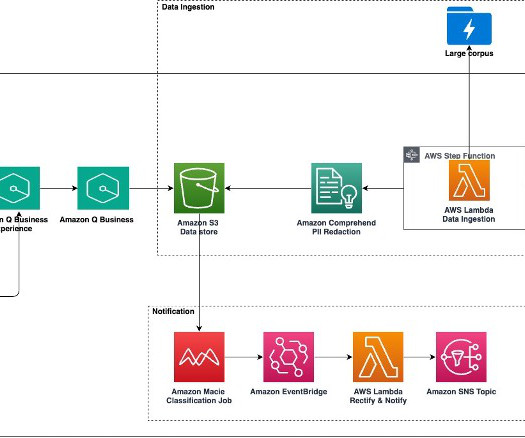
Traditional keyword-based search mechanisms are often insufficient for locating relevant documents efficiently, requiring extensive manual review to extract meaningful insights. This solution improves the findability and accessibility of archival records by automating metadata enrichment, document classification, and summarization.
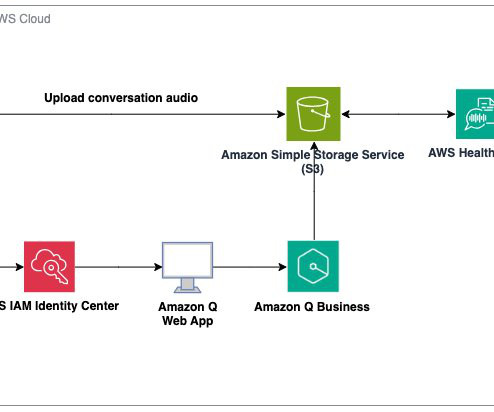
With the advent of generative AI and machinelearning, new opportunities for enhancement became available for different industries and processes. AWS HealthScribe combines speech recognition and generative AI trained specifically for healthcare documentation to accelerate clinical documentation and enhance the consultation experience.
The Global Banking Benchmark Study 2024 , which surveyed more than 1,000 executives from the banking sector worldwide, found that almost a third (32%) of banks’ budgets for customer experience transformation is now spent on AI, machinelearning, and generative AI.
Intelligent document processing (IDP) is changing the dynamic of a longstanding enterprise content management problem: dealing with unstructured content. The ability to effectively wrangle all that data can have a profound, positive impact on numerous document-intensive processes across enterprises. Not so with unstructured content.
By eliminating time-consuming tasks such as data entry, document processing, and report generation, AI allows teams to focus on higher-value, strategic initiatives that fuel innovation.
This phenomenon, known as hallucination, has been documented across various AI models. Another machinelearning engineer reported hallucinations in about half of over 100 hours of transcriptions inspected. A third study identified hallucinations in nearly every one of 26,000 transcripts generated using Whisper, AP said.
The team opted to build out its platform on Databricks for analytics, machinelearning (ML), and AI, running it on both AWS and Azure. He estimates 40 generative AI production use cases currently, such as drafting and emailing documents, translation, document summarization, and research on clients.
It often requires managing multiple machinelearning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats. Amazon Bedrock Data Automation is expanding to additional Regions, so be sure to check the documentation for the latest updates. billion in 2025 to USD 66.68
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. As Principal grew, its internal support knowledge base considerably expanded.
Typical repetitive tasks that can be automated includes reviewing and categorizing documents, images, or text. This, of course, is where machinelearning come into play. “We Specifically, the startup targets work processes that involve making decisions on unstructured data, such as images, text, PDFs and other documents.
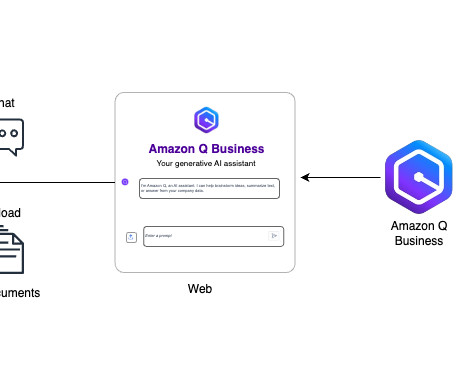
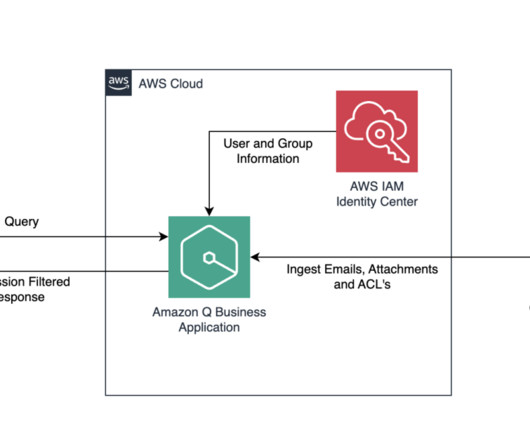
Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive. This solution uses the powerful capabilities of Amazon Q Business.
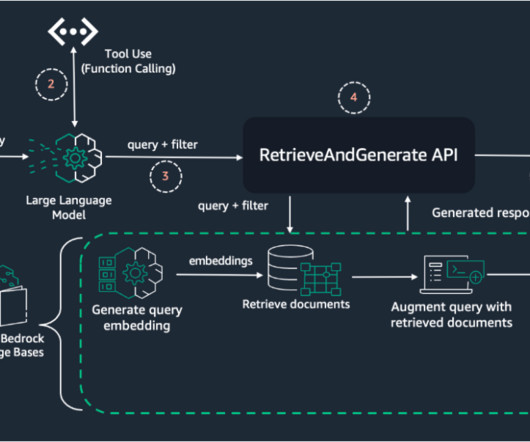
By narrowing down the search space to the most relevant documents or chunks, metadata filtering reduces noise and irrelevant information, enabling the LLM to focus on the most relevant content. This approach narrows down the search space to the most relevant documents or passages, reducing noise and irrelevant information.
The team opted to build out its platform on Databricks for analytics, machinelearning (ML), and AI, running it on both AWS and Azure. He estimates 40 generative AI production use cases currently, such as drafting and emailing documents, translation, document summarization, and research on clients.
You can find instructions on how to do this in the AWS documentation for your chosen SDK. Additionally, consider exploring other AWS services and tools that can complement and enhance your AI-driven applications, such as Amazon SageMaker for machinelearning model training and deployment, or Amazon Lex for building conversational interfaces.
But you can stay tolerably up to date on the most interesting developments with this column, which collects AI and machinelearning advancements from around the world and explains why they might be important to tech, startups or civilization. “We weren’t sure it would be possible.” Image Credits: Asensio, et.
Similarly, when an incident occurs in IT, the responding team must provide a precise, documented history for future reference and troubleshooting. As businesses expand, they encounter a vast array of transactions that require meticulous documentation, categorization, and reconciliation.
For a detailed breakdown of the features and implementation specifics, refer to the comprehensive documentation in the GitHub repository. You can follow the steps provided in the Deleting a stack on the AWS CloudFormation console documentation to delete the resources created for this solution.
The following example shows how prompt optimization converts a typical prompt for a summarization task on Anthropics Claude Haiku into a well-structured prompt for an Amazon Nova model, with sections that begin with special markdown tags such as ## Task, ### Summarization Instructions , and ### Document to Summarize.
In 2013, I was fortunate to get into artificial intelligence (more specifically, deep learning) six months before it blew up internationally. It started when I took a course on Coursera called “Machinelearning with neural networks” by Geoffrey Hinton. It was like being love struck.
In claims and operations, insurers are applying AI to fraud detection, loss summarization and automation of large-scale document processing. Underwriting is a key target area, with AI being used to improve data ingestion, risk triaging and portfolio optimization.
On the Configure data source page, provide the following information: Specify the Amazon S3 location of the documents. Prior to AWS, Flora earned her Masters degree in Computer Science from the University of Minnesota, where she developed her expertise in machinelearning and artificial intelligence. Specify a chunking strategy.
This is where intelligent document processing (IDP), coupled with the power of generative AI , emerges as a game-changing solution. The process involves the collection and analysis of extensive documentation, including self-evaluation reports (SERs), supporting evidence, and various media formats from the institutions being reviewed.
Finally, we delve into the supported frameworks, with a focus on LMI, PyTorch, Hugging Face TGI, and NVIDIA Triton, and conclude by discussing how this feature fits into our broader efforts to enhance machinelearning (ML) workloads on AWS. This feature is only supported when using inference components. gpu-py311-cu124-ubuntu22.04-sagemaker",
Enterprises provide their developers, engineers, and architects with a range of knowledge bases and documents, such as usage guides, wikis, and tools. Team members can chat directly or upload documents and receive summarization, analysis, or answers to a calculation. This is a well-known use case asked about by several MuleSoft teams.
Google Drive supports storing documents such as Emails contain a wealth of information found in different places, such as within the subject of an email, the message content, or even attachments. Types of documents Gmail messages can be sorted and stored inside your email inbox using folders and labels.
However, today’s startups need to reconsider the MVP model as artificial intelligence (AI) and machinelearning (ML) become ubiquitous in tech products and the market grows increasingly conscious of the ethical implications of AI augmenting or replacing humans in the decision-making process.
For instance, consider an AI-driven legal document analysis system designed for businesses of varying sizes, offering two primary subscription tiers: Basic and Pro. Meanwhile, the business analysis interface would focus on text summarization for analyzing various business documents. This is illustrated in the following figure.
Whether processing invoices, updating customer records, or managing human resource (HR) documents, these workflows often require employees to manually transfer information between different systems a process thats time-consuming, error-prone, and difficult to scale.
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. An interactive chat interface allows deeper exploration of both the original document and generated content.
He has extensive experience designing end-to-end machinelearning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. She innovates and applies machinelearning to help AWS customers speed up their AI and cloud adoption.
His team was tasked with digitizing the onboarding process — particularly document-heavy manual review workflows — that were costing the bank millions of dollars every year and not catching fraud. Inspired by this, Burke and his twin brother, Ronan Burke, launched Inscribe , an AI-powered document fraud detection service.
SageMaker JumpStart is a machinelearning (ML) hub that provides a wide range of publicly available and proprietary FMs from providers such as AI21 Labs, Cohere, Hugging Face, Meta, and Stability AI, which you can deploy to SageMaker endpoints in your own AWS account. It’s serverless so you don’t have to manage the infrastructure.
You can also use this model with Amazon SageMaker JumpStart , a machinelearning (ML) hub that provides access to algorithms and models that can be deployed with one click for running inference. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5%
It efficiently manages the distribution of automated reports and handles stakeholder communications, providing properly formatted emails containing portfolio information and document summaries that reach their intended recipients. Note that additional documents can be incorporated to enhance your data assistant agents capabilities.
Set up your knowledge base with relevant customer service documentation, FAQs, and product information. Join the generative AI builder community at community.aws to share your experiences and learn from others. She is leading the Amazon Bedrock Flows, with 18 years of experience building customer-centric and data-driven products.
OpenAI is quietly launching a new developer platform that lets customers run the company’s newer machinelearning models, like GPT-3.5 , on dedicated capacity. ” “[Foundry allows] inference at scale with full control over the model configuration and performance profile,” the documentation reads.
This design simplifies the complexity of distributed training while maintaining the flexibility needed for diverse machinelearning (ML) workloads, making it an ideal solution for enterprise AI development. His expertise includes: End-to-end MachineLearning, model customization, and generative AI.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content